详解双向带头循环链表
今天给大家分享的数据结构中的链表的双向带头循环链表结构!听到这个链表大家可能心中一颤,其实他就是个纸老虎,看着比较难搞,实际上非常简单易懂,创建该结构链表的大佬可谓是真的牛,因为该结构比起单链表要好的不是一星半点了!下面来看一下双向带头循环链表的样子

可以看出该链表的head的前面那个指针指向最后一个结点,最后一个结点的next指针指向head指针,构成了循环!
下面来详细解释一下何谓双向带头循环链表!
双向带头循环链表的解释!
带头
首先先来解释一下带头的意思,带头用书面上的话就是引用了哨兵位!简单来说,就是单独开辟了一块空间用来存储指向头结点指针的地址!这一份空间和其他结点相同,不同的是该结点的数值域不存储有效数值!有些课本上会将哨兵位的数值域存储该链表的长度,实际上这是不合理的,若数值为整形类型,这是可以的,但是若换成char类型,其远远不能存放结点的个数!double类型同理!因为有了哨兵位的存在,可以使得我们下面有关链表的功能省下不少功夫!
循环
循环的意思是该链表是一个环形的结构!不能像以前的单链表那种方式来遍历整个链表了!
双向
顾名思义,该链表中的每个结点与前后两个结点都有联系,不同于单链表的是,双向链表的指针域存放的是上一个结点的地址和下一个结点的地址!
双向带头链表各个功能块的具体实现!
代码的规范性,方便后续修改!
为了方便以后链表的数据可以进行修改,采用类型重定义的方式来存储数据,以后改变数据类型只需要将类型改变即可!设置如下代码
//将int类型重命名为Datatype,方便以后的修改!
typedef int Datatype;
//将struct ListNode结构体类型重命名为SLnode!
typedef struct ListNode
{
Datatype data;
struct ListNode* pre;
struct ListNode* next;
}SLnode;结点的创建(Buynode)
//新建链表的结点!
SLnode* Buynode(Datatype x)
{
SLnode* newnode = (SLnode*)malloc(sizeof(SLnode));
//当malloc开辟失败时,返回NULL!
if (newnode == NULL)
{
perror("malloc error");
return NULL;
}
else
{
newnode->data = x;
newnode->next = NULL;
newnode->pre = NULL;
}
return newnode;
}链表的初始化
//链表的初始化!
SLnode* Initnode()
{
//初始化创建哨兵位方便后面的操作!
//因为是双向带头循环,所以当没有结点的时候哨兵位的pre和next都指向自己本身!
SLnode*phead = Buynode(0);
phead->next = phead;
phead->pre = phead;
return phead;
}链表的打印(Print)
//链表的打印!
void Print(SLnode* phead)
{
SLnode* cur = phead->next;
printf("guard<==>");
while (cur != phead)
{
printf("%d==>", cur->data);
cur = cur->next;
}
printf("guard\n");
}因为为循环链表,所以不能像以前单链表那样遍历链表,因为最后一个结点的next指针为哨兵位!所以当cur为哨兵位phead,结束循环!开始遍历的头结点也是哨兵位的后面第一个结点phead->next!
判断是否为空链表(ifempty)
//判断是否位空链表!
bool ifempty(SLnode* phead)
{
//哨兵位不能为空!
assert(pheaad);
//若为空则返回1!非空返回0!
return phead==phead->next;
}链表的头删功能(pophead)
//链表的头删功能! void pophead(SLnode* phead) { assert(phead); //当链表为空时,phead也不能为空! assert(!(ifempty(phead)));//当为空链表时,程序直接结束并且打印出错误行! //first指针指向第一个结点的地址! SLnode* first = phead->next; //second指针指向第二个结点的地址! SLnode* Second = phead->next->next; free(first); phead->next = Second; Second->pre = phead; }
实现头删功能仅需要将第一个结点删除,然后让哨兵位的next指向第二个结点,第二个结点的pre指向哨兵位!然后将第一个first结点释放即可!
链表的头增功能(pushhead)
//链表的头增功能!
void pushhead(SLnode* phead,Datatype x)
{
//创建一个first变量用来记录原来第一个结点的位置!
SLnode* first = phead->next;
SLnode* newnode = Buynode(x);
phead->next = newnode;
newnode->next = first;
newnode->pre = phead;
first->pre = newnode;
}实现头增功能仅需要将新建结点的pre指向哨兵位,哨兵位的next指向新建的结点,新建结点的next指向原来第一个结点即可!第一个结点的pre指向新建结点!
链表的尾增操作(pushend)
//链表的尾增操作!
void pushend(SLnode*phead, Datatype x)
{
SLnode* tail = phead->pre;//tail用来记录原尾结点!
SLnode* newnode = Buynode(x);//newnode是将要新插得尾结点!
tail->next = newnode;
newnode->pre = tail;
newnode->next = phead;
phead->pre = newnode;
}因为有了哨兵位的存在所以不需要改变头结点的指针,所以传一级指针就可以改变结构体!
也不用和单链表那样分情况来考虑尾增的情况,只需要找到尾结点然后进行插入操作即可!
链表的尾删操作 (popend)
//链表的尾删操作!
void popend(SLnode* phead)
{
assert(phead);
assert(!(ifempty(phead)));
SLnode* tail = phead->pre;
SLnode* tailpre = tail->pre;
free(tail);
tailpre->next = phead;
phead->pre = tailpre;
}尾删操作仅需要找到尾结点的前一个结点,然后释放尾结点,最后把尾结点前那个结点的指针关系与哨兵位关系修改即可!
链表的查找功能 (Find)
//链表的查找功能!
SLnode* Find(SLnode* phead, Datatype x)
{
SLnode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}当找到与x值对应的cur指针时,返回cur指针!否则返回NULL!(既然实现了链表的查找功能,那么在某个位置的删除,添加也可以实现!)
删除pos对应的位置(erase)
//删除pos对应的位置!
void erase(SLnode* phead, SLnode* pos)
{
assert(pos);
assert(!(ifempty(phead)));
SLnode* pre = pos->pre;
SLnode* next = pos->next;
free(pos);
pre->next = next;
next->pre = pre;
}要想删除pos的位置,只需要知道pos前面结点的地址和其后面结点的地址即可,然后修改指针指向,free掉pos位置即可!
在pos之前插入数据(Insert)
//在pos之前插入数据!
void Insert(SLnode* pos,Datatype x)
{
SLnode* pre = pos->pre;
SLnode* newnode = Buynode(x);
pre->next = newnode;
newnode->pre = pre;
newnode->next = pos;
pos->pre = newnode;
}在pos位置之前插入数据,只需要知道pos指针的地址即可,然后将指针进行如上代码修改即可完成pos之前插入数据!
销毁链表(destroy)
//销毁链表!
void destroy(SLnode* phead)
{
assert(phead);
SLnode* cur = phead->next;
while (cur != phead)
{
SLnode* next = cur->next;
free(cur);
cur = next;
}
free(phead);
}
销毁链表,即把每个结点释放掉,然后进行置空即可,从哨兵位的下一个结点开始,直到再次走到哨兵位结束!因为传的是一级指针,所以不能将哨兵位不能进行置空,所以在最后使用过destroy函数之后手动置空即可!
erase和Insert的复用!
既然讲了erase函数和Insert函数的实现,那么该函数方便了我们不少,我们可以将其复用到头尾插,头尾删的函数之中!
头插复用insert
头插只需要在head的next位置插入即可,头插复用Insert函数代码如下:
void pushhead(SLnode* phead,Datatype x)
{
assert(phead);
Insert(phead->next, x);
}尾插复用insert
尾插只需要在最后一个结点的next插入即可,最后插入的那个结点的next是指向phead的,所以在phead(哨兵位)之前插入即可,因为在phead之前插入后其next指向phead,符合最后一个结点的特征!链表图如下:
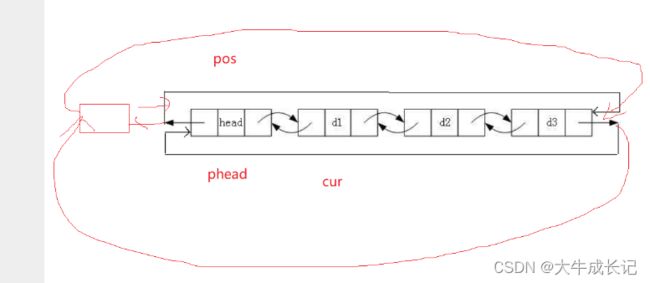 代码如下!
代码如下!
void pushend(SLnode*phead, Datatype x)
{
SLnode* tail = phead->pre;//tail用来记录原尾结点!
SLnode* newnode = Buynode(x);//newnode是将要新插得尾结点!
Insert(phead, x);
}
头,尾删复用erase
头删即删除第一个结点的位置,即head的next,
尾删即删除最后一个结点的位置,即head的pre,
代码如下:
void pophead(SLnode* phead)
{
assert(phead); //当链表为空时,phead也不能为空!
assert(!(ifempty(phead)));//当为空链表时,程序直接结束并且打印出错误行!
erase(phead,phead->next);//头删复用erase!
erase(phead,phead->pre); //尾删复用erase!
}
erase和Insert复用的好处!
通过二者函数的复用,可以让我们不用在写头尾增删的函数了,因为二者函数包含了头尾增删的功能!通过这两个函数可以看出创建这个双向带头循环链表的大佬是多么的牛啦!它可以更方便的实现单链表的功能!这还可以让我们手撕链表省下大把时间!
好了,今日的双向带头循环链表分享结束,若还有疑问等,欢迎评论区讨论!
