word2vec应用的主要步骤及算法原理
写在前面:
word2vec的算法实现参考博客:
Spark MLlib — Word2Vechttps://blog.csdn.net/zhangchen2449/article/details/52795529?ops_request_misc=&request_id=&biz_id=102&utm_term=spark%20mllib%20word2vec%20霍夫曼树&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-52795529.first_rank_v2_pc_rank_v29&spm=1018.2226.3001.4187 https://blog.csdn.net/zhangchen2449/article/details/52795529?ops_request_misc=&request_id=&biz_id=102&utm_term=spark%20mllib%20word2vec%20%E9%9C%8D%E5%A4%AB%E6%9B%BC%E6%A0%91&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-52795529.first_rank_v2_pc_rank_v29&spm=1018.2226.3001.4187
https://blog.csdn.net/zhangchen2449/article/details/52795529?ops_request_misc=&request_id=&biz_id=102&utm_term=spark%20mllib%20word2vec%20%E9%9C%8D%E5%A4%AB%E6%9B%BC%E6%A0%91&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-52795529.first_rank_v2_pc_rank_v29&spm=1018.2226.3001.4187
spark word2vec 源码详细解析https://blog.csdn.net/u014552678/article/details/104001725?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163723724416780271599552%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=163723724416780271599552&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-5-104001725.first_rank_v2_pc_rank_v29&utm_term=spark+mllib+word2vec&spm=1018.2226.3001.4187https://blog.csdn.net/u014552678/article/details/104001725?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163723724416780271599552%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=163723724416780271599552&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-5-104001725.first_rank_v2_pc_rank_v29&utm_term=spark+mllib+word2vec&spm=1018.2226.3001.4187
论文参考:
Efficient Estimation of Word Representations in Vector Space
Distributed Representations of Words and Phrases and their Compositionality
ITEM2VEC: NEURAL ITEM EMBEDDING FOR COLLABORATIVE FILTERING
Topic2Vec: Learning Distributed Representations of Topics
spark中word2vec的主要使用步骤为:
import org.apache.spark.ml.feature.Word2Vec
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.ml.linalg.Vectors.norm
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{col, expr}
object word2vec {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("word2vec")
.enableHiveSupport()
.getOrCreate()
//1-语料库
val rawData = spark.createDataFrame(Seq(
(0.0,"spark" ,"Hi,I,heard about,Spark,which,is,very,popular,in,IT"),
(1.0, "java","I,wish,Java,could,use,case classes"),
(2.0, "model","Logistic regression models,are,neat")
)).toDF("id","label", "text")
//2- 训练样本
import spark.implicits._
val trainData = rawData.map({raw => val id = raw.getAs[Double]("id")
val label = raw.getAs[String]("label")
val text = raw.getAs[String]("text")
(id,label,text,text.split(","))
}).toDF("id","label","text","text_array")
trainData.show(false)
//3-训练
val word2Vec = new Word2Vec()
.setInputCol("text_array") // one of the following types: [array, array]
.setOutputCol("features")
.setVectorSize(5) //隐向量的维数
.setWindowSize(3) //滑动窗口2c+1的c取值
.setMinCount(1) //词频少于1的会被丢掉,训练的向量集合中不会有
.setNumPartitions(1) //alpha = learningRate * (1 - numPartitions * wordCount.toDouble / (trainWordsCount + 1))
.setMaxSentenceLength(1000)
val model = word2Vec.fit(trainData)
//4-词向量
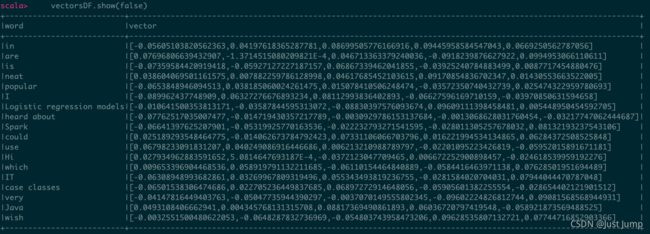
val vectorsDF = model.getVectors
vectorsDF.show(false)
//5 - Top高相关
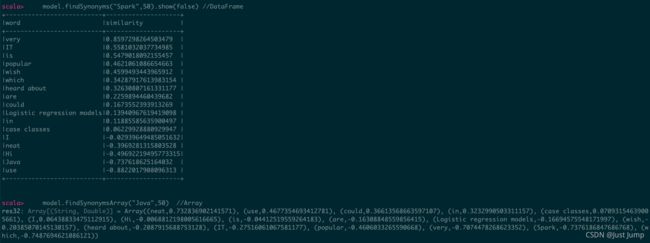
model.findSynonyms("Spark",50).show(false) //DataFrame
model.findSynonymsArray("Java",50) //Array
//6-文本向量
val textVectors = model.transform(trainData)
textVectors.show(false)
}
}
结果展示:
1、训练样本
2、词向量
3、Top相似
4、 文本向量
