一文读懂什么是Byzer
目录
一、什么是Byzer?
二、Byzer特性
2.1 语法特性
2.2 数据的管理特性
2.3 支持自定义函数拓展Byzer语法
三、Byzer有哪些功能?
3.1 Byzer-Lang语言特性
3.1.1强大的数据处理能力
3.1.2内置机器学习算法
3.2 Byzer-Lang支持权限控制
3.3 Byzer-LLM拓展
3.4 Byzer-Python拓展
四、认识Byzer-LLM
4.1 Byzer-llm拓展的安装
4.2 Byzer-llm能够干什么?
4.2.1 帮助企业构建一个统一的数据中台
4.2.2 基于开源大模型或者大模型的SaaS服务搭建自己的大模型
4.2.3 助力大模型微调
一、什么是Byzer?
Byzer的前身是 MLSQL,MLSQL 的前身是 StreamingPro,2021年12月,MLSQL更名为Byzer。下图为Byzer的发展历程。
图1 byzer发展历程
Byzer不同时期的形态体现了不同的任务重心,StreamingPro最初的目的是简化Spark Streaming的开发,提升流数据处理的效率。MLSQL将spark由应用转变成服务,提供了RESTful API接口,之后内置了机器学习的能力,全面打通了从原始数据到机器学习算法部署的链路,加快机器学习算法快速落地。而Byzer不仅继承了MLsql的优点,还扩展了Byzer-python,向python的生态拥抱,拓展了Byzer-LLM向最近火爆的大模型拥抱。
Byzer官网号称是一门全新的语言,有自己的语法(简洁)、有自己的解释器、有自己的执行引擎,这门语言的底座基于Spark+Ray。
Byzer不仅是一门全新的语言,也可以看做是一个功能强大的框架,Byzer允许不同角色的研发人员在其生态体系中进行数据分析;进行机器学习、深度学习算法分布式训练、分布式部署等。总之,Byzer允许数据分析、产品研发、算法开发等人员共同使用它简化自己的工作,提升工作效率,更重要的是它可以在数据层面充分协调不同的部门,加快产品从研发到落地的效率。Byzer的功能很多,但本质上还是用一个统一的平台,管理统一的数据,使用统一的语法在上面各自进行业务开发,并将自己开发的产品API暴露。从而缩短产品从研发到部署的时间。
Byzer是一门全新的语言,不过它是一门面向大数据、AI、云原生的分布式语言,它内置了许多插件,可以帮助软件行业工程人员更好地在数据分析、机器学习、AI等领域落地实际的应用项目。这门语言诞生的初衷是从编程语言层面上进行革新,从根本上提高数据平台落地和 AI 工程化的效率,在统一的平台上实现过去要使用多语言、多平台、多组件才能实现的事情。

图2 byzer架构
二、Byzer特性
2.1 语法特性
一切用类似于sql的语句进行数据操作、数据处理、模型训练、模型部署成应用,并且所有的数据都以数据表的形式存储。

图 3 byzer-notebook界面
上图中在指定目录中加载自定义的图片数据集,保存的数据湖中,再次从数据湖中加载数据可以看到输出的是表结构,也就是说Byzer以表的形式管理任何数据。但这是表面上让人感觉数据似乎变成了表,但实际上byzer用hdfs管理文件,所有数据湖中的数据全部都以切片的形式保存到了Byzer主目录的data文件夹中。
2.2 数据的管理特性
在byzer,数据湖中的数据保存到了byzer的安装路径下,但是用户数据是按照租户隔离的,在notebook中的直观体现就是deleta数据湖中的数据大家都可以看见,都可以使用、修改。但是FileSystem中的数据是用户私有的,不同的用户登录进notebook中只能看到自己的数据而能不能查看其他人的数据,
实际上notebook中FileSystem中的数据存储在notebook安装路径中,所以这样看来notebook不仅是byzer官方推荐的代码编辑器,似乎还是一个数据管理平台。因为notebook做到了将数据按照租户隔离。
2.3 支持自定义函数拓展Byzer语法
目前,byzer中仅仅支持是十几个原生语法比如load,select等,其他的直接照搬spark sql语句拓展自己的语法功能,但是sql语句本来就功能有限,比如实现分支语句、循环语句等都是需要拓展的,byzer支持用户使用java、scala语言对其语法进行拓展。
三、Byzer有哪些功能?
Byzer除了Byzer-Lang核心语法之外,还有许多拓展,比如Byzer-LLM、Byzer-Python、Byzer-Notebook等。下面以这三个拓展为例,看一看Byzer有哪些特性。
3.1 Byzer-Lang语言特性
Byzer官方对Byzer-Lang的解释是:Byzer 是一门结合了声明式编程和命令式编程的混合编程语言,其低代码且类 SQL 的编程逻辑配合内置算法及插件的加持,能帮助数据工作者们高效打通数据链路,完成数据的清洗转换,并快速地进行机器学习相关的训练及预测。
Byzer 希望能够提供一套语言、一个引擎,就能覆盖整个数据链路,同时可以提供各种算法、模型训练等开箱即用的能力。
但是我在简单体验了Byzer之后,特别引起我关注的还是以下两大功能:
3.1.1强大的数据处理能力
Byzer-Lang号称Everything is a table,在 Byzer-Lang 中所有的文件都可以被抽象成表的概念。多样的数据源例如:数据库,数据仓库,数据湖甚至是 Rest API 都可以被 Byzer-lang 抽象成二维表的方式读入并进行后续的分析处理。Byzer官网号称,Byzer-lang几乎可以加载市面上主流的数据源和数据格式:
(1)数据源:JDBC协议的数据库,多种云上对象存储,HDFS等
(2)数据格式:例如text,image,csv, json, xml等文件格式
3.1.2内置机器学习算法
Byzer 提供了一些内置的、开箱即用的机器学习算法,其中包括:自动机器学习(AutoML)、K 均值聚类算法(KMeans)、朴素贝叶斯法(NaiveBayes)、交替最小二乘法(ALS)、随机森林(RandomForest)、线性回归(LinearRegression)、逻辑回归(LogisticRegression)、隐含狄利克雷分布(LDA)等。Byzer不仅内置了这些机器学习算法,而且还内置了诸如特征平滑、归一化等特征工程算子。在Byzer上面不需要书写机器学习的数据处理、模型训练等代码,不需要像python中导入第三方包,只需要一行简单的声明即可使用。数据处理部分仅需load、run几个命令即可完成,模型训练也仅需train命令,算法部署上线只需一个插件并结合一个register命令即可以可api访问的形式部署。
3.2 Byzer-Lang支持权限控制
Byzer-Lang可以通过插件的方式控制权限,在Byzer-notebook中体现为FileSystem中展现的数据是按租户隔离的,而DetltaLake的库表则是所有用户都可以看到和使用的。具体来说,以不同的账号登录进Byzer-notebook,看到的FileSystem中的数据是不同的,因为FileSystem中的数据是属于用户私有的,而看到的DetltaLake是相同的。这一点不同于python的jupyter。
Byzer-Lang还支持从编码层面支持自定义用户权限,只需要将自定义的权限控制类实现streaming.dsl.auth.TableAuth类,然后打包放在byzer-lang下的lib文件夹中即可。
3.3 Byzer-LLM拓展
Byzer-LLM是Byzer语言的一个拓展,Byzer官方对Byzer-LLM的定义是:Byzer-LLM 让用户可以端到端的完成业务数据获取,处理,finetune大模型,多场景部署大模型等全流程。该扩展的目标也是为了让企业更好的将业务数据注入到私有大模型(开源或者商业),并且可对外提供多场景部署形态,诸如 ETL, 流式计算,API 服务等。Byzer-LLM 目前支持两类大模型:(1)私有大模型。用户需要自己下载模型权重,在启动模型时指定路径。(2)SaaS大模型。 用户需要提供token。
3.4 Byzer-Python拓展
Byzer通过 Byzer-python 扩展(内置)来支持Python语言。因此,只需要在notebook中声明python环境的地址既可以在notebook中书写python代码。通过 Byzer-python,用户不仅仅可以进行使用 Python 进行 ETL 处理,比如可以将一个 Byzer 表转化成一个分布式DataFrame on Dask 来操作,它还支持各种机器学习框架,比Tensorflow,Sklearn,PyTorch。
四、认识Byzer-LLM
Byzer-LLM是Byzer的一个拓展,这个拓展最早出现于byzer 2.36版本,也就是去年12月份出现的,这个拓展就是为了让byzer拥抱现在火热的大模型。Byzer官方对Byzer-llm的定义是:让用户可以端到端的完成业务数据获取,处理,finetune大模型,多场景部署大模型等全流程。 该扩展的目标也是为了让企业更好的将业务数据注入到私有大模型(开源或者商业)。
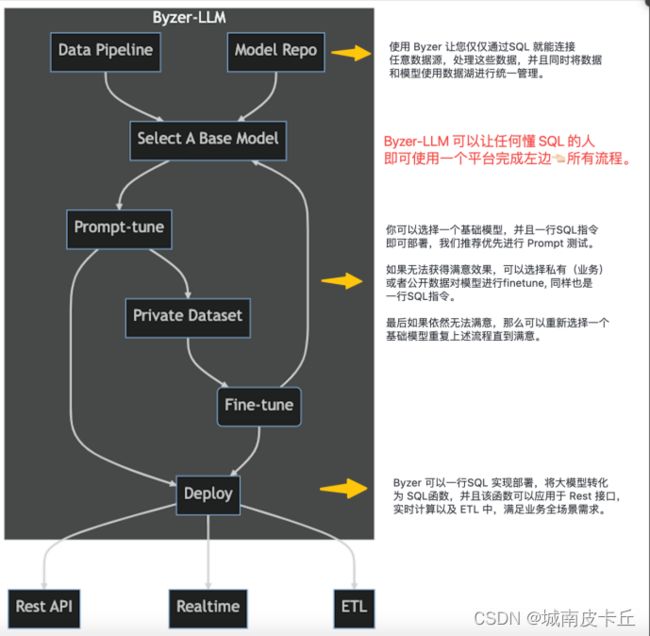
图4 byzer-llm模型能力
4.1 Byzer-llm拓展的安装
Byzer-llm是基于byzer-lang,因此需要首先安装好byzer-lang,其次需要安装Ray。Ray 是一个专门执行人工智能框架的分布式执行引擎,让开发者仅需添加数行代码就能轻松转为适合于计算机集群运行的(或单个多核心计算机的)高性能分布式应用而不需要用户关心那些调度、数据传输和硬件错误等问题。Ray 与 TensorFlow、PyTorch 和 MXNet 等深度学习框架互相兼容。怎么安装ray呢?很简单,只需要在conda环境下执行pip install就行了,不过需要注意的是,byzerllm目前仅支持ray=2.5版本的。安装好Ray之后,可以在命令行启动 ray start --head 之后会在本地8275端口进入ray集群的控制面板,在面板上可以看到集群的信息,包含节点存活状态、日志、内存CPU占用情况等。之后需要下载byzer-llm.jar包放到byzer安装目录的plugin目录下。特别需要注意的是需要在安装有ray的conda环境中运行byzer-llm,后续需要其他pip 包,也要安装在这个conda环境中。
4.2 Byzer-llm能够干什么?
4.2.1 帮助企业构建一个统一的数据中台
数据中台是数据分析师,算法工程师,研发人员,产品部门,运营甚至老板日常工作的集中式的控制台,数据中台不干涉其他部门 API 定义的情况下,提供全司视角的(也包括外部 API)的 API 服务视图。随着大数据、人工智能、云计算等技术的迅速发展,云基础设施、基础软件、算法模型等都逐渐完善和成熟,业界对数据平台的效率诉求是越来越高,低效的跨平台数据运转逐渐成为工程师落地数据平台和完成 AI 工程化的痛点。但是,无论是从更换基础设施入手,还是换上更易用的框架,又或是招聘更优秀的研发人才,都无法做到大幅度的效率提升。Byzer官方相信只有在编程语言层面进行革新,才能从根本上提高数据平台落地和 AI 工程化的效率。Byzer 作为一门低代码的开源编程语言,可以在语言层面将数据处理链路、AI 工程中的复杂操作以及权限管控进行抽象,同时降低编程语言的学习成本和上手成本,从而帮助企业真正将效率提升上来。
4.2.2 基于开源大模型或者大模型的SaaS服务搭建自己的大模型
Byzer也可以助力深度学习领域,让每家公司都可以将自己的业务数据注入进商业或者开源大模型,完成私有化大模型应用。
比如,现在要基于开源模型微调出一个属于自己的图片分类模型,首先可以将自己的数据集上传到数据湖中,数据湖支持将数据分布式存储。由于数据湖中的数据是公共的,因此这份数据集可以统一管理起来,比如公司有自己的数据采集标注人员、有模型开发人员,这两类人员可以通过数据湖的数据管理功能而使数据能够及时、准确地在不同工作人员之间流通。
不仅是数据管理,Byzer还支持仅需简单配置即可实现多机多卡模型训练,能够帮助工程师充分调动训练大模型所需的算力。模型训练完毕之后,还支持一键部署,极大加快一款产品的开发流程。因为使用Byzer,可以使用它自有的语法(类SQL语言)连接任何业务库,获取数据,加工数据,并且注入到大模型内进行fintune,然后一键部署成函数封装成API供其他人调用。 并且Byzer 也对有很好的Python支持,完全可以在Byzer平台上使用Python语言进行算法开发,但是也可以使用Byzer的语法在只懂SQL的基础上完成上述工作。比如模型和数据都可以统一保存成表,方便管理,避免到处手动拷贝数据,模型等等。
它还支持从单机到分布式部署,支持GPU调度,可以根据用户需求随时进行算力和存储的扩展。
4.2.3 助力大模型微调
可以从数据处理、模型训练、算法部署层面助力大模型微调,或者助力企业将自己的数据、知识、业务注入进大模型从而构建自己的私有大模型。
以官网给出的百川大模型为例。看一下微调流程。
首先,值得注意的是,截止到2023年7月,Byzer官方测试过的可微调的大模型有三个:chatglm2、baichuan、falcon。而且截止到2023年7月,Byzer-LLM 大模型微调支持两种QA格式的数据。

图5 QA格式
一个是 Alpaca 格式

图 6 Alpaca数据格式
另一种是MOSS格式

图 7 MOSS数据格式
第一步:加载数据和模型

第二步:配置模型微调参数

训练好之后保存即可。
上面的训练案例仅仅指定了最大输入长度,其实在微调过程中还有很多参数可以指定
