图像分割中常用数据集及处理思路(含代码)
图像分割中常用数据集及处理思路(含代码)
- 常用数据集
-
- 1.1 CityScapes
-
- sota
- 1.2 CamVid
-
- sota
- 1.3 ADE20K
-
- sota
- 1.4 PASCAL VOC 2012
-
- sota
- 1.5 COCO-Stuff
-
- sota
- 1.6 SUN RGBD
- 1.7 NYUDv2
- 在这里给大家一套普适的代码,供大家参考,以下是代码:
-
- 首先导入我们需要的模块
- 第二块比较鸡肋,可以直接省略这一步
- 这里以ADE20K为例吧,首先应该重写Dataset,这是用自己数据集的一种非常重要的步骤
-
- 初始化函数
- 读取文件的函数
- 进行数据处理的函数
- 然后就是getitem和len了
- 这里再给大家一个用哈希映射的方式处理标签的方法,这里可能速度会更快,用于那些已经上过色的标签:
常用数据集
1.1 CityScapes
道路场景 包含30个类别 2975张训练,500张验证,1525张测试 一共5000张
侧重于城市街景场景的语义理解,适用于多种视觉任务,数据来自50多个城市,多个季节,白天良好天气条件
手动挑选帧,多种背景
5000例精准标准,20000例粗糙标准

sota
常规分割

实时分割
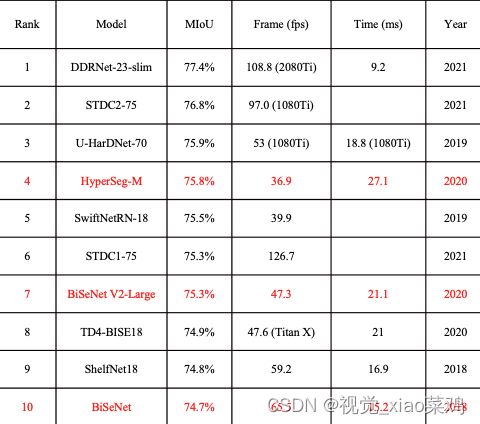
1.2 CamVid
是第一个具有语义标签的视频集合,包含元数据,该数据库共包含32个分类

sota
常规分割算法

实时分割算法

1.3 ADE20K
ADE20k由27000多幅图像组成,跨越3000多个对象类别,数据集的当前版本包含:
27574张图片(25574张用于训练,2000张用于验证),跨越365个不同场景
sota

1.4 PASCAL VOC 2012
该数据集包含20个对象类别,此数据集中的每个图像都有像素级分割注释,边界框注释和对象注释,该数据集已被广泛用于目标检测、语义分割和分类任务

sota
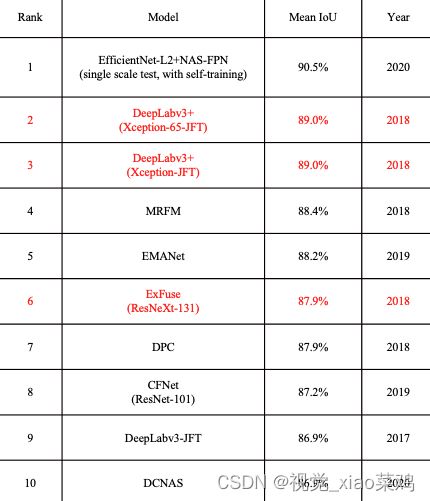
1.5 COCO-Stuff
该数据集用于场景理解任务(如语义分割、对象检测和图像字幕)的数据集,该数据集中有164k个图像,跨越172个类别

sota

1.6 SUN RGBD
通过四款3D摄像机采集图像和深度信息,这四款相机均含有色传感器 红外发射器 红外接收器 其中色彩传感器获取RGB信息,红外发射器和红外接收器获取深度信息。包含10335个房间场景的真实RGB-D图像,每个RGB图像都有相应的深度和分割图,标记对象类别多大700个,训练集和测试集分别包含5285和5050副图像

1.7 NYUDv2
由来自各种室内场景的视频序列组成,由来自Microsoft kinect的RGB和深度相机记录,他的特点是:
- 1449张密集标记的对齐RGB和深度图像
- 464张来自3个城市的新场景
- 407024新的未标记帧
- 每个对象都标有一个类和一个实例号

在这里给大家一套普适的代码,供大家参考,以下是代码:
首先导入我们需要的模块
import os
import torch
import torch.utils.data as data
from PIL import Image
import torchvision.transforms.functional as F
import torchvision.transforms as transforms
import albumentations as A
import numpy as np
import random
其中 albumentations是数据增强的库,在检测分割任务中,这个图像增强的库比其他的库速度要快,后面也会出一个关于数据增强的文章。
第二块比较鸡肋,可以直接省略这一步
class ExtRandomCrop(object):
def __init__(self, size, pad_if_needed=True):
self.size = size
self.pad_if_needed = pad_if_needed
@staticmethod
def get_params(img, output_size):
"""Get parameters for ``crop`` for a random crop.
Args:
img (PIL Image): Image to be cropped.
output_size (tuple): Expected output size of the crop.
Returns:
tuple: params (i, j, h, w) to be passed to ``crop`` for random crop.
"""
w, h = img.size
th, tw = output_size
if w == tw and h == th:
return 0, 0, h, w
i = random.randint(0, h - th)
j = random.randint(0, w - tw)
return i, j, th, tw
def crop(self, img, lbl):
"""
Args:
img (PIL Image): Image to be cropped.
lbl (PIL Image): Label to be cropped.
Returns:
PIL Image: Cropped image.
PIL Image: Cropped label.
"""
assert img.size == lbl.size, 'size of img and lbl should be the same. %s, %s' % (
img.size, lbl.size)
# pad the width if needed
if self.pad_if_needed and img.size[0] < self.size[1]:
img = F.pad(img, padding=int((1 + self.size[1] - img.size[0]) / 2))
lbl = F.pad(lbl, padding=int((1 + self.size[1] - lbl.size[0]) / 2))
# pad the height if needed
if self.pad_if_needed and img.size[1] < self.size[0]:
img = F.pad(img, padding=int((1 + self.size[0] - img.size[1]) / 2))
lbl = F.pad(lbl, padding=int((1 + self.size[0] - lbl.size[1]) / 2))
i, j, h, w = self.get_params(img, self.size)
return F.crop(img, i, j, h, w), F.crop(lbl, i, j, h, w)
这里以ADE20K为例吧,首先应该重写Dataset,这是用自己数据集的一种非常重要的步骤
class ADE20K(data.Dataset)
初始化函数
def __init__(self, root, mode='train', crop_size=(512, 512)):
self.root = root
self.crop_size = crop_size
self.random_crop = ExtRandomCrop(self.crop_size, pad_if_needed=True)
if mode == 'train':
self.mode = mode + 'ing'
elif mode == 'val':
self.mode = mode + 'idation'
self.images, self.mask = self.read_file(self.root, self.mode)
self.crop_size = crop_size
读取文件的函数
def read_file(self, path, mode):
image_path = os.path.join(path, "images", mode)
mask_path = os.path.join(path, "annotations", mode)
image_files_list = os.listdir(image_path)
mask_files_list = os.listdir(mask_path)
image_list = [os.path.join(image_path, img) for img in image_files_list]
mask_list = [os.path.join(mask_path, mask) for mask in mask_files_list]
image_list.sort()
mask_list.sort()
return image_list, mask_list
进行数据处理的函数
def transform(self, image, mask):
image = np.array(image)
mask = np.array(mask)
trans = A.Compose([
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.OneOf([
A.MotionBlur(p=0.5), # 使用随机大小的内核将运动模糊应用于输入图像。
A.MedianBlur(blur_limit=3, p=0.5), # 中值滤波
A.Blur(blur_limit=3, p=0.2), # 使用随机大小的内核模糊输入图像。
], p=1),
A.ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.2, rotate_limit=45, p=0.5),
# 随机应用仿射变换:平移,缩放和旋转输入
A.RandomBrightnessContrast(p=0.5), # 随机明亮对比度
])
trans_results = trans(image=image, mask=mask)
return trans_results
然后就是getitem和len了
def __len__(self):
return len(self.images)
def __getitem__(self, index):
image = Image.open(self.images[index]).convert('RGB')
mask = Image.open(self.mask[index])
image, mask = self.random_crop.crop(image, mask)
mask = np.array(mask)
if self.mode == "train":
trans_results = self.transform(image, mask)
image = trans_results['image']
mask = trans_results['mask']
transform_img = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]
)
image = transform_img(image)
mask = torch.from_numpy(mask)
return image, mask
这里再给大家一个用哈希映射的方式处理标签的方法,这里可能速度会更快,用于那些已经上过色的标签:
class LabelProcessor:
def __init__(self, file_path):
self.colormap = self.read_color_map(file_path)
self.cm2lbl = self.encode_label_pix(self.colormap)
@staticmethod
def read_color_map(file_path):
pd_label_color = pd.read_csv(file_path, sep=',')
colormap = []
for i in range(len(pd_label_color.index)):
tmp = pd_label_color.iloc[i]
color = [tmp['r'], tmp['g'], tmp['b']]
colormap.append(color)
return colormap
@staticmethod
def encode_label_pix(colormap):
cm2lbl = np.zeros(256 ** 3)
for i, cm in enumerate(colormap):
cm2lbl[(cm[0] * 256 + cm[1]) * 256 + cm[2]] = i
return cm2lbl
def encode_label_img(self, img):
data = np.array(img, dtype='int32')
idx = (data[:, :, 0] * 256 + data[:, :, 1]) * 256 + data[:, :, 2]
return np.array(self.cm2lbl[idx], dtype='int64')