对OpenAI重拳出击!美国政府出手「开源」ChatGPT,Altman惊慌连发3推
FTC突然对OpenAI展开调查,Altman连发3推澄清。FTC对阵OpenAI的大戏正缓缓拉开帷幕。
重磅!美国联邦贸易委员会的调查说来就来!
调查对象不是别人,正是风头正旺的OpenAI。
一封长达20页的调查要求书直接给了Sam Altman当头棒喝。
OpenAI又双叒摊上事了
上周OpenAI刚刚被美国律所和作家起诉,要求赔偿30亿美元。
可能OpenAI还没来得及选好帮自己打官司的律师,这边又被美国联邦贸易委(FTC)员会找上门来了。

FTC给OpenAI列了一个包括49个大问题,200多个小问题的清单,要求OpenAI就清单上的所有问题进行详细地回答和陈述。

看到这一大串的问题,向来以成熟冷静,处变不惊著称的Sam Altman也有点麻了,连发3推给OpenAI压压惊。
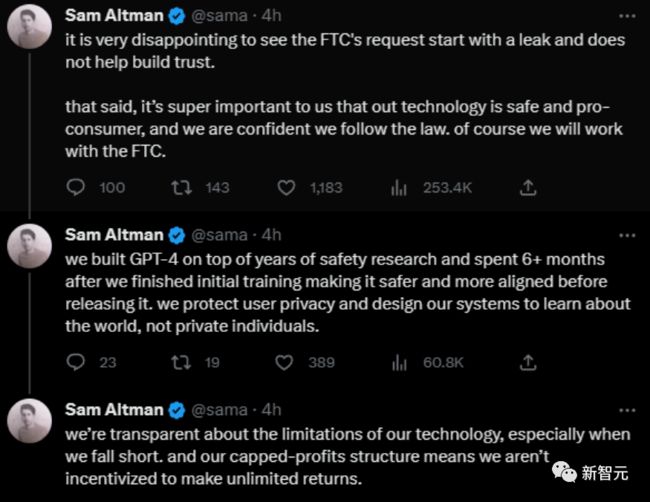
这份清单的49个问题,除去要求OpenAI讲清楚基本的公司架构之外,针对模型训练,隐私和提示词风险,API插件,个人信息等几个方面,询问得非常专业和详细。
FTC!主动出击
说穿了一句话,FTC主要调查的内容就是OpenAI违没违反消费者保护法。
而公布的20页民事调查要求书(CID)一看就专业的不行。

知情人士表示,这份20页的CID是真实的。但FTC没有予以置评。
CID中指出,本次FTC的调查将重点关注OpenAI是否存在不公平,或欺诈性的隐私数据安全条例,以及是否有不公平,或欺诈性的行为,导致用户蒙受受到伤害的风险(包括声誉损失),有无违反《联邦贸易委员会法》第5条内容。
一直以来,立法者都在为生成式AI发愁,需不需要立新法,怎么立,怎么保护知识产权、用户数据,都是「头疼大事」。
而在这次调查中,FTC霸气地表示,我们已有法律权力来追究AI可能造成的伤害。
而提到FTC,就得提到主席Lina Khan。
作为一个女强人,她直接就是一个出手,对新兴技术采取主动监管,而非被动应对。
概括来看,CID中要求OpenAI列出所有有权访问其模型的第三方,并要求这些第三方分别讲清楚各自是如何保留、处置用户数据的,以及自己公司模型训练的数据从哪儿来。
CID还要求OpenAI说明他们是如何评估LLM存在的风险的,以及是如何检测并处理有误导性、歧视性的内容的。
要知道,在今年3月,OpenAI曾经出现过疏漏,当时的错误是:一部分用户可以看到其他用户的历史聊天记录的标题,以及1.2%左右的ChatGPT Plus用户的支付信息暴露。
为此,3月24号OpenAI在官网上发布了一篇文章,解释20号发生了什么。
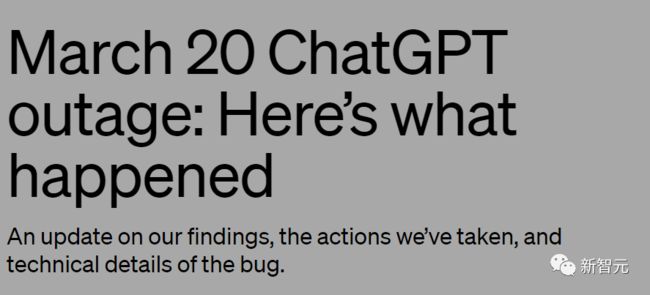
而此次的调查要求OpenAI对这个事儿进行二次说明。
其实截止到现在,OpenAI的CEO Altman在华盛顿还是个香饽饽的。
立法者们觉得,Altman在对立法监管自家公司产品这件事上,还算是兼听则明的。
不过,也有另一些AI专家提醒,Altman这么说也可能有自己的考虑,还是要广泛听取各方不同的观点。
质询函内容
在这份CID中,FTC列举了49个问题,囊括以下几个方面:
1. 公司基本信息及背景
2. 相关告知与陈述
3. 模型开发与训练
4. 风险评估与应对
5. 隐私和Prompt风险及措施
6. API集成及插件
而在每个大类下,CID又从各个方面详细列举了若干问题。比较重要的有如下:
-
OpenAI必须披露其完整的法定名称、地址、电话号码以及OpenAI结构、子公司、合伙企业等细节。
-
在适用时期内,每年OpenAI必须披露员工人数、组织结构图、高管和董事详细信息、股东详细信息等。
-
OpenAI必须披露在适用时期内与第三方就开发LLM签订的所有协议的详情。
-
OpenAI必须披露其用于训练、测试、审计和监控LLM的政策和程序。
-
OpenAI必须披露用于训练LLM的数据来源、数据类型、数据保留和负责数据的个人/部门的详细信息。
-
OpenAI必须披露其技术和组织安全措施,以降低LLM输出包含非法、不安全、有偏见或误导内容的风险。
-
OpenAI必须披露用户投诉受到伤害的详细信息以及应对的回应。
-
OpenAI必须披露与AI系统的隐私、安全和伦理相关的政策和程序。
-
OpenAI必须披露与其LLM的安全性、偏见和事实正确性相关的内部沟通、评估和研究的详细信息。
-
OpenAI必须披露其如何监控遵守与审计AI系统相关政策的详细信息。
-
OpenAI必须披露向LLM用户提供的说明、指南和培训材料的详细信息。
-
OpenAI必须披露与其LLM相关的任何外部研究/测试并概述结果。
-
OpenAI必须披露其为应对安全问题而对LLM做出的任何修改的详细信息。
看了这一系列的详细而全面的问题,如果OpenAI真的不得不对里面的内容进行详尽陈述的话,万一内容「一不小心」被泄露出来,OpenAI可能真的就被彻底OPEN了。
屋漏偏逢连夜雨
OpenAI最近的麻烦事还真不止这一件。
6月28号,位于北加州的Clarkson律所代表16名原告对OpenAI提起了集体诉讼。

指控OpenAI在训练大模型时从网上抓取的数据,严重侵犯了16名原告的著作权和隐私,要求赔偿30亿美金。
克拉克森诉讼的核心主张是OpenAI的整个商业模式都是基于盗窃。
几天之后4位作家Mona Awad,Paul TremblaSarah Silverman,Christopher Golden、Richard Kadrey也在美国不同的地方法院分别起诉了OpenAI,指控他们在未经同意的情况下使用他们出版的书籍来训练 ChatGPT,违反了版权法。

看到这里,可能有的读者想问了,之前你们不是写过Sam Altman大战国会山,赢得了监管的支持,怎么一下出来这么多找OpenAI茬的人?
这里的主要问题在于,美国社会里管事的有3拨人:国会里立法的老头子们,法院里审案子的法官们和政府的行政机构,他们3家属于分别管事,大部分时候互不牵扯。
所以Sam Altman虽然赢得了第一拨人——国会里立法的老头子们的支持,但是另外两拨的关系他还没有搞定。
这两天的事情就属于这两拨没搞定的人找上门来了。
而今天来查水表的FTC,应该是所有人里最难应付的主。
科技公司劲敌——FTC
FTC中文全称是联邦贸易委员会,职能类似于我们国家的商务部。
最近一段时间稍微关注过美国科技圈新闻的读者应该对这个机构应该都不陌生,除了找OpenAI的麻烦,它的业绩还包括:调查处罚了FTX等一些加密货币交易所,和微软打了个反垄断官司。
昨天,FTC临时中止微软收购暴雪的动议刚被法院驳回,今天就去查了OpenAI的水表。
不得不感叹,FTC这政府机构的工作效率堪比创业公司。

再看看FTC以往和科技公司的交锋历史,Facebook,谷歌,微软,亚马逊都因为各种问题被它处罚过,可以说是科技公司的老苦主了。
而它现在任上的主席Lina Khan女士,更是一位相当传奇的人物。

她在2021年6月15日被拜登任命为FTC主席时,才32岁。
这经历怎么说呢,放在国内就相当于32岁的女士成为了商务部部长,属于是爽文作者都不敢立的超大女主人设。
除了年纪轻轻就被委以重任之外,她还自带「反大科技公司」光环出道。
2017年,还在读书的莉娜·可汗在《耶鲁法学杂志》发表文章《亚马逊的反垄断悖论》,在法律界和政界引发巨大反响。
她曾在众议院司法委员会反垄断小组担任法律顾问一职,帮助撰写了一份449页的报告,指控亚马逊、苹果、Facebook和谷歌滥用市场主导地位。
所以在她被任命为FTC主席不到一个月后,谷歌和脸书就请愿FTC,让她回避针对科技公司的反垄断诉讼。

这两家富可敌国,在硅谷呼风唤雨的科技巨头,是发自内心的害怕这位新上任的领导,担心真的打不过,只能先请系统Ban了她。

可以想象,只要她还在任上一天,大型科技公司的日子就不会太好过。
而OpenAI因为现在「硅谷当红炸子鸡」的身份,作为初创公司就被FTC盯上,可能也算是对他们地位的一种另类肯定吧。

网友反应
在Altman稳定军心一般发了三条推特以后,底下网友众说纷纭。
不过大致一扫过去,基本全是痛批Altman的。难道真是「天下苦OpenAI久矣」?
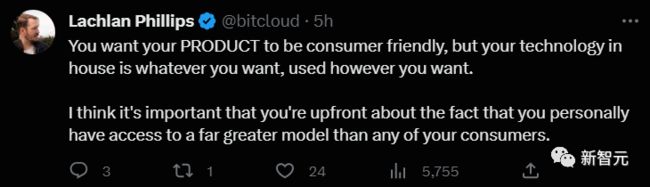
比如下面这位网友,这都算委婉的了。
「我知道你想让用户满意你的产品,但你的技术是你自己整的,怎么用也是随你心意来的。我觉得你得坦诚一点,承认你个人能比用户接触到多得多得多的模型。」
「你的坦诚,很重要。」
这位网友更直白,估计都能给Altman直接干沉默。
「我每天都用GPT,我怎么没觉得你维护用户的权益了?又没得到我们的同意,又收集信息,你怎么敢说自己在维护权益的啊?」

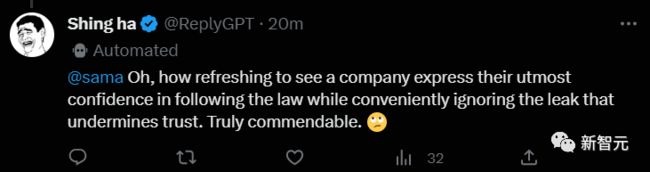
下面这位网友直接开启阴阳:
「多新鲜!一家公司,嘴上说着嗯嗯嗯我们绝对遵守法律,实际上用户信息全给泄露了,信你个鬼啊。你OpenAI是真棒。」
「如果Altman说那一套AI安全性的说辞只是为了他自己的话,我是不会听的。」

不过也有站OpenAI的网友,表示对监管者很不放心,担心他们根本就没能力把这个事情管好。

担心那些带着偏见的监管者没有办法真的有效地进行监管。
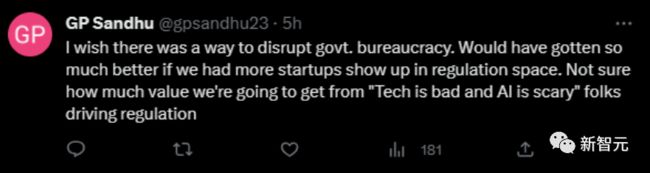
这位网友更是看热闹不嫌事大,希望OpenAI把关键数据交给FTC后,再以某种形式泄露出来,最后完成对OpenAI的「开源」。
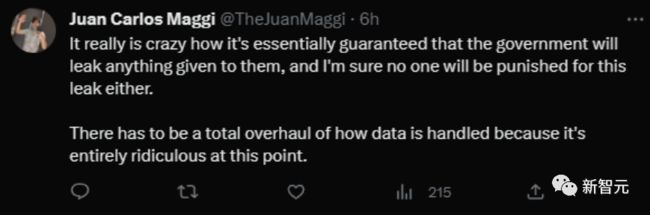
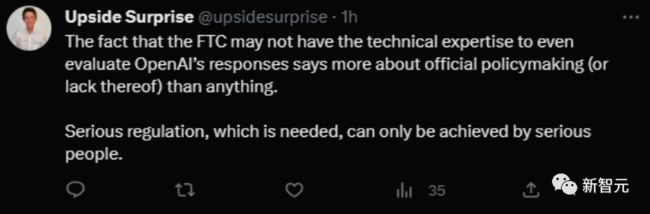
最后这条评论想必说出了很多人的心声。虽然那份CID看着专业,但是FTC可能还是没有足够专业的人员来跟进。
哪怕是评估OpenAI的回答,可能都费劲。
这是很有启发意义的——专业的立法「能且仅能」被专业人士搞定。
而看样子,这位网友对FTC并没什么信心。
参考资料:
https://www.nbcnews.com/tech/tech-news/ftc-investigating-chatgpt-maker-openai-possible-consumer-harm-rcna94067
本文源自:新智元公众号