Python Pandas 使用示例
文章目录
- 使用Boolean 选择rows
- 读取Excel表格里指定的sheet, 并跳过起始n行
- 删除只有一个元素的行
- 删除重复的
- 合并多个csv文件到excel表格中
- 获取csv文件的数据
使用Boolean 选择rows
import pandas as pd
# Sample DataFrame
data = {'Name': ['John', 'Alice', 'Bob', 'Emily'],
'Age': [25, 30, 35, 40],
'City': ['New York', 'Paris', 'London', 'Tokyo']}
df = pd.DataFrame(data)
print(df)
print('================')
# List of boolean values
boolean_list = [True, False, True, False]
# Select rows based on the boolean list
selected_rows = df[boolean_list]
print(selected_rows)
输出:
Name Age City
0 John 25 New York
1 Alice 30 Paris
2 Bob 35 London
3 Emily 40 Tokyo
================
Name Age City
0 John 25 New York
2 Bob 35 London
读取Excel表格里指定的sheet, 并跳过起始n行
安装openpyxl, openpyxl是Python操作Excel文件的另一个库,可以非常方便地读写Excel文件的各种内容
pip install openpyxl
df = pd.read_excel(path, sheet_name= sheetName, skiprows=1)
- sheet_name: 指定读取某个sheet
- skiprows: 参数跳过起始的n行,因为可能有表头等合并单元格之类的数据
删除只有一个元素的行
假设excel表格正常的每行有4个数据(即4列),但是某一行只有一个单元格有数据,需要删除该行(改行可能是数据或者其他内容)
df = df.dropna(thresh=2)
- thresh: thresh = 2表示,如果一行至少有2个以上非空值时才会被删除
删除重复的
原始data frame
brand style rating
0 Yum Yum cup 4.0
1 Yum Yum cup 4.0
2 Indomie cup 3.5
3 Indomie pack 15.0
4 Indomie pack 5.0
默认删除,基于所有列删除重复行
df = df.drop_duplicates()
brand style rating
0 Yum Yum cup 4.0
2 Indomie cup 3.5
3 Indomie pack 15.0
4 Indomie pack 5.0
删除特定的重复列, 使用subset
>>> df.drop_duplicates(subset=['brand'])
brand style rating
0 Yum Yum cup 4.0
2 Indomie cup 3.5
keep参数的使用
keep{‘first’, ‘last’, False}, default ‘first’
Determines which duplicates (if any) to keep.
‘first’ : Drop duplicates except for the first occurrence.
‘last’ : Drop duplicates except for the last occurrence.
df.drop_duplicates(subset=['brand', 'style'], keep='last')
brand style rating
1 Yum Yum cup 4.0
2 Indomie cup 3.5
4 Indomie pack 5.0
合并多个csv文件到excel表格中
使用前确保安装了xlsxwriter
pip install xlsxwriter
import os
import pandas as pd
# Get the directory name
directory_name = "your file path"
# List all CSV files in the directory
csv_files = [f for f in os.listdir(directory_name) if f.endswith('.csv')]
# Create a Pandas Excel writer using the directory name as the Excel file name
excel_file_name = os.path.basename(directory_name) + '.xlsx'
excel_writer = pd.ExcelWriter(excel_file_name, engine='xlsxwriter')
# Loop through each CSV file and add it as a new sheet in the Excel file
for csv_file in csv_files:
sheet_name = os.path.splitext(csv_file)[0] # Use CSV file name as sheet name
# remove the special characters of the name, here is an example
# sheet_name = sheet_name.replace("[", "").replace("]", "") # Remove "[" and "]"
df = pd.read_csv(os.path.join(directory_name, csv_file))
df.to_excel(excel_writer, sheet_name=sheet_name, index=False)
# Save the Excel file
excel_writer.close()
print(f"CSV files merged into {excel_file_name} with different sheets.")
获取csv文件的数据
data = pd.read_csv('test.csv', header=None, encoding = "utf-8").values
读取后,data如下所示
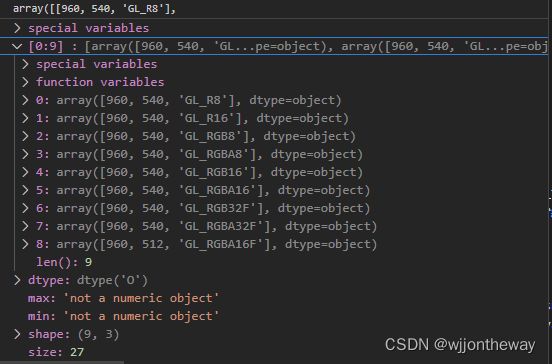
可以通过索引去获取某一行某一列的数据
for i in range(len(data)):
print(data[i][0])
print(data[i][1])
print(data[i][2])