计算机视觉大型攻略 —— CUDA(3)内存模型(二)Aligned and Coalesced内存访问
上一篇介绍了CUDA内存空间。GPU对片外DRAM的访问往往是访存性能的瓶颈。[1]第四章的后半部分,通过Global内存为例,说明了GPU访问DRAM的工作模式以及在该模式下,如何高效的使用DRAM内存。同样的内容也可以参考[2]的5.3.2一节。
参考文献:
[1] PROFESSIONAL CUDA C Programming. John Cheng, Max Grossman, Ty McKercher.
[2] CUDA C PROGRAMMING GUIDE
内存访问模式
GPU对片外DRAM的访问延迟大,带宽低,导致其成为很多应用的性能瓶颈。因此对DRAM访问的进一步优化可以有效改善程序性能。优化之前,首先看一下GPU对内存的访问模式。

如上图所示,DRAM内存的读写在物理上是从片外DRAM->片上Cache->寄存器。 其中,片外DRAM到片上Cache是主要性能瓶颈。DRAM到Cache之间的一次传输(transaction)设计为32,64或者128字节,并且内存地址按照32,64或者128字节的间隔对齐。
后文中transaction特指设备内存(DRAM)到片内存储(Cache)的传输。
以读数据为例,DRAM数据首先进入L2 Cache,之后根据GPU架构的不同,有些会继续传输到L1 Cache,最后进入线程寄存器。L2 cache是所有SM共有,而L1 cache是SM私有。如果使用了L1+L2 Cache,那么执行一次DRAM到Cache之间的传输(transaction),是128字节。如果仅使用L2 Cache,那么就是32字节。是否启用L1 Cache取决于GPU架构与编译选项 。
关闭L1 cache
-Xptxas -dlcm=cg
打开L1 cache
-Xptxas -dlcm=ca由于采用SIMT的架构,GPU对内存的访问指令是由warp发起的,即warp中每个线程同时执行内存操作指令,不过每个线程所访问的数据地址可以不同,GPU会根据这些不同的地址发起一次或多次DRAM->Cache的传输(transaction),直到所有线程都拿到各自所需的数据(Cache->Registers)。显然,我们可以通过减少DRAM->Cache的transaction次数来优化程序性能。
回忆门:Stalled warp。执行模型一文中提到,warp执行内存指令时会有很长的延迟,此时warp进入Stalled状态,warp调度器调度其他eligible warp执行。
内存指令延迟的原因:
- 访问设备内存本身存在大的延迟。
- SIMT的执行模型,意味着只有当warp内所有32个线程都得到了数据后,才会从Stalled态转为Eligible态。
最好的情况下,GPU发起一次DRAM->Cache的transaction就把Warp中所有线程所需的数据全部获取到Cache,最坏的情况下,则需要32次transaction。
对齐与合并访问
通过上面的简单分析不难想到,优化全局内存的访问性能,需要考虑下面两个方面,
- 内存对齐访问(Aligned memory access): DRAM->Cache transaction,首地址是32或128字节的倍数。
- 内存合并访问(Coalesced memory access): Warp内线程访问连续内存块。
下图为一个理想的对齐合并内存访问的例子,

Warp内每个线程需要4个字节的数据,且总共32*4=128个字节是连续的,起始地址为128。此时只需一次128字节的memory transactioin(DRAM->Cache)。
下图为非对齐,非合并的情况,
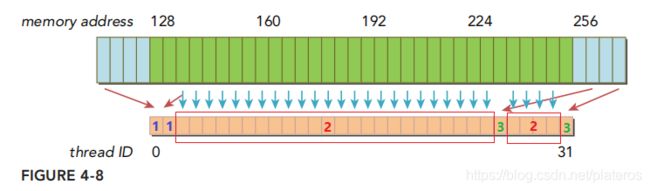
这种情况下需要3个128字节的memory transaction,一个从内存地址0->127,为标记为1的线程取值,, 一个从128->255,为标记2的线程取值,一个从256->383,为标记3的线程取值。
下面以Global Memory为例,展开讨论不同情况下内存访问的性能。
Global Memory Read
根据是否使用L1 cache,可分为两种情况讨论,
- Cached load(使用L1 cache)
- Uncached load(不适用L1 cache)
Cached Load
使用L1 cache,memory transaction的以L1 cache line的大小128字节为间隔访存。
合并对齐访问(Aligned, coalesced):

上图,warp内线程访问的地址在128~256之间,每个线程需要4个字节,所有线程所需内存地址按照线程ID连续排列。只需执行一个128字节的transaction即可满足所有线程的需求。此时总线利用率为100%,即在这次transaction中,内存带宽得以充分使用,没有多余的数据。
另一种情况,

此时,warp的线程访问的数据在128~256之间,每个线程需要4个字节,但是内存地址没有按照线程ID排序。与之前的例子相同,一次128字节的transaction即可满足要求,且总线利用率为100%。
连续,不对齐,

上图warp需要连续的128字节,但是内存的首地址没有128字节对齐。此时需要两次128字节的transaction,总线利用率为50%(总共读了256个字节,实际使用128字节)
如果warp内的线程访问同一4字节数据,

上图warp内所有线程访问了相同4个字节,需要一次128字节的transaction,总线利用率4/128=3.125%。
最坏情况下,

Warp所需的数据散落在global memory里,那么需要最多32次128字节的transaction。
再来看不使用L1 cache的情况。
Uncached Load
如果不使用L1 cache,一次内存传输由1, 2或4个segments完成,每个segment为32字节, 并且按照32字节对齐。显然这种情况下数据传输得到了更精细的划分(最小32字节),这会带来更高效的非对齐,非合并的内存访问。

上图是一个理想的情况下,对齐合并的内存访问,只需一个4 segment的transaction,总线利用率100%。
非对齐情况,

上图warp需要连续的128字节数据,但是首地址并未和32字节对齐,此时128字节的数据最多分布在5个segment内,因此总线利用率至少为80%。显然要比使用L1 cached的时候更好。
再来看warp访问同一个4字节数据的情况,

此时的总线利用率为4/32 = 12.5%,也要比使用L1 cache时(3.125%)要好。
考虑最坏的情况,

32个线程所需的数据散落在至多32个segment里。散落在32个32字节的segment里显然要比散落在32个128字节的情况要好。
Read-Only cache: Read-Only cache原本用于纹理内存的缓存。GPU 3.5以上的版本可以使用该缓存替代L1,作为Global内存的缓存。此cache采用32字节对齐间隔,因此比原128字节的缓冲区更适合非对齐非合并的情况。
Global Memory Write
内存写操作情况要简单的多,Fermi/Kelper的L1 cache并不支持写操作。内存写仅通过L2 cache写入设备内存。与Uncached Load类似,transaction分为1, 2, 4个segment,每个segment32字节。
理性情况下,
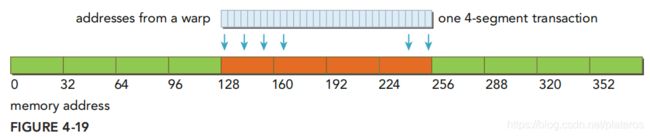
warp写入连续的128个字节,仅需一个4-segments的transaction。
对齐,但是不合并,

对齐,但散落在192个字节的空间内,则需要3个1-segment的transaction。

64字节的连续存储,需要一个2-segment的transaction。
AoS与SoA
[1]中讨论了两种数据组织形式,Array of structures 和 Structure of array.
//Array of structures (AoS)
struct innerStruct {
float x;
float y;
};
struct innerStruct myAoS[N];
//Structure of array
struct innerArray {
float x[N];
float y[N];
};
struct innerArray moa;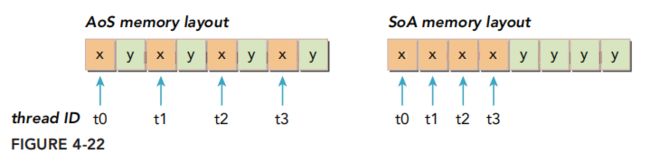
上图为AoS, SoA的内存结构。采用AoS的形式,Warp线程访问x的时候,会把y的值也载入cache。浪费了50%的带宽。而SoA就不存在这个问题。因此推荐采用SoA的形式组织数据。
访存性能瓶颈通常发生在片外DRAM的读写上,除了减少设备内存的transaction以及提高总线利用率之外,在程序设计时还应尽量减少对Global内存的访问次数,这部分在下一篇的共享内存里有所涉及。