MongoDb
文章目录
- 前言
- 一、MongoDb简介
-
- 1、MongoDb介绍
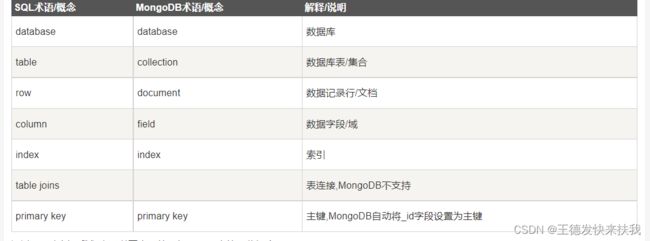
- 2、MongoDb概念描述
- 3、环境搭建
- 二、基本常用命令
-
- 1、数据库操作
- 2、集合操作
- 3、基于文档的CRUD
- 4、文档的更多查询
- 5、索引
- 三、SpringBootData连接MongoDb
-
- 1、环境搭建
- 2、实体类/持久层/服务层
- 4、关于mongodb和mysql不同点
-
- 1、主键
- 2、连接查询
- 3、mysql数据转移到mongodb中
- 总结
前言
资料整理参考B站黑马MongoDb,和菜鸟教程,fds–MongoDb是NoSql中最像Sql的非关系型数据库
一、MongoDb简介
1、MongoDb介绍
传统数据库在当前数据库操作的‘三高’-情况下显得力不从心
1、High Performance :数据库高并发的读写请求
2、Huge Storage :对海量数据的高效率存储和访问的需求
3、High Scalability && High availability:对数据库的高可扩展性和高可用性的需求。
MongoDb是一种基于分布式文件存储的数据库,旨在为web应用提高可扩展的高性能数据库。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。

2、MongoDb概念描述
每个文档的数据类型都是独立的,
1)文档介绍
需要注意的是:
①文档中的键/值对是有序的。
②文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
③MongoDB区分类型和大小写。
④MongoDB的文档不能有重复的键。
⑤文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
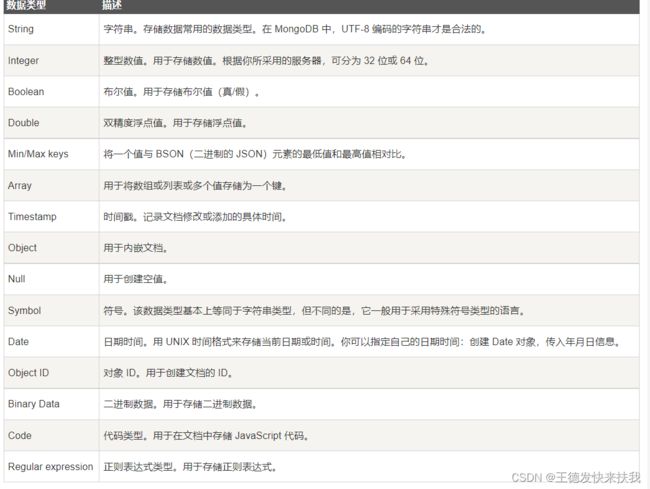
2)数据类型
3、环境搭建
1)windows安装(暂时忽略)
2)linux安装
①tar压缩包安装
解压MongoDB安装包安装即可
②yum安装
3)新建文件夹存储日志和数据
4)修改配置文件(特别注意路径是绝对路径)
systemLog:
#MongoDB发送所有日志输出的目标指定为文件
# #The path of the log file to which mongod or mongos should send all diagnostic logging information
destination: file
#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径
path: "/mongodb/single/log/mongod.1og"
#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾.
logAppend: true
storage:
#mongod实例存储其数据的目录。storage . dbPath设置仅适用于mongod.
##The directory where the mongod instance stores its data.Default value is "/data/db".
dbPath: "/mongodb/single/data/db"
journal:
#启用或禁用持久性日志以确保数据文件保持有效和可恢复。
enabled: true
processManagement:
#启用在后台运行mongos或mongod进程的守护进程模式。
fork: true
net:
#服务实例绑定的IP,默认是1ocalhost
bindIp: localhost,192.168.0.2
#bindIp
#绑定的端口,默认是27017
port: 27017
5)启动mongodb
mongod -f mongodb.conf
启动成功会提示successful
6)远程连接
如果是部署在云服务器的,
1、注意关闭防火墙
2、mongo配置文件的是服务器所在的局域网,而你连接的是你的公网IP
二、基本常用命令
1、数据库操作
创建数据库:use 数据名
查看所有的库:show dbs
查看当前库:db
删除已持久化(磁盘当中)的库:db.dropDatabase()
MongoDb默认使用test库,如果你没有创建数据库,那么集合存储在test中
一个空的数据库是内存当中的,不会存储到磁盘中,所以show dbs看不见刚创建的数据库
自带的库:

2、集合操作
集合就是传统关系型数据库中的表
显示创建:db.createCollection(name)
隐士创建:在插入一个文档的时候自动创建集合
展示所有的集合:show tables
集合删除:db.集合名称.drop()
3、基于文档的CRUD
1)插入和简单的查询
1、插入数据:db.集合名.insert({JSON数据})
2、批量插入:db.集合名.insert([{},{},{}])
3、查询集合的所有数据:db.集合名.find();
4、条件查询:
①查询符合条件的文档:db.集合名.find({})
②查询符合条件的一条文档:db.集合名.findOne({})
5、投影查询(查询部分字段):db.集合名.find({查询条件},{显示的字段:1/0(1表示显示,0表示不显示)})
批量插入容易出错,可以用trycatch捕捉异常处理
2)更新
1、覆盖
db.集合名.update({条件},{字段:数据类型(属性值)}),这样会将其他的字段清空掉,只修改指定的值
2、局部修改:db.集合名.update({条件},{ $ set:{字段:数据类型(属性值)}})
3、以上两种都只会修改匹配的第一个数据,如果想修改所有符合条件的数据,
db.集合名.update({条件},{ $ set:{字段:数据类型(属性值)},{multi:true}})
4、列值的增减:
db.集合名.update({条件},{$inc:{字段:NumberInt(增长值)}})
3)删除

4)分页查询和排序
①统计文档数
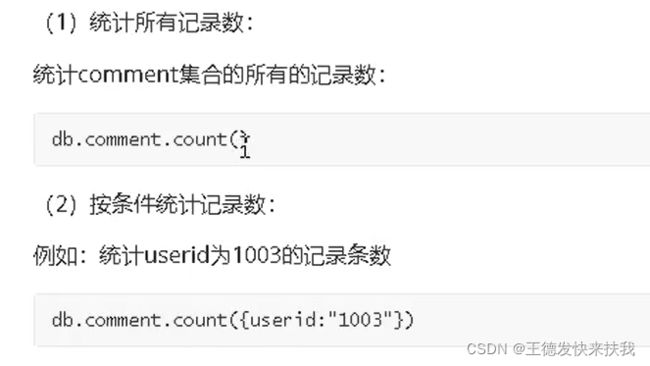
②列表查询

默认查询的记录是20个,skip代表跳过的记录条数,也就是分页的大小
③排序
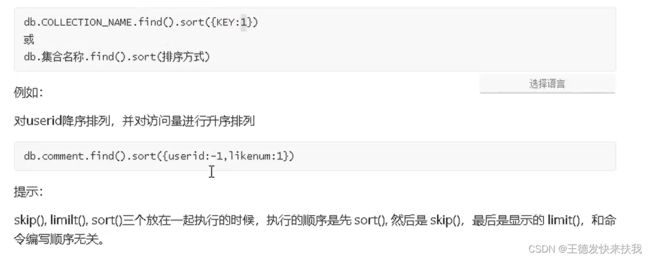
4、文档的更多查询
1)正则表达式
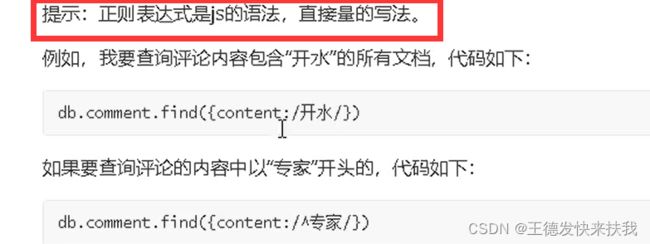
2)比较查询

3)包含查询
类似mysql的in
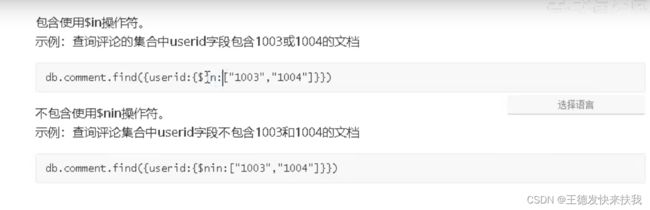
4)条件连接查询

5、索引
1)索引介绍
MongoDb和mysql一样,查询默认都是全局扫描的,也每一条记录都会被扫描,然后筛选出符合条件的记录,这样对于大数据而言无疑是非常耗时的,所以利用索引(一种数据结构)对字段进行特殊的存储,提高查询的效率,MongoDb采用的是B-Tree,mysql采用的是B+Tree
2)索引类型
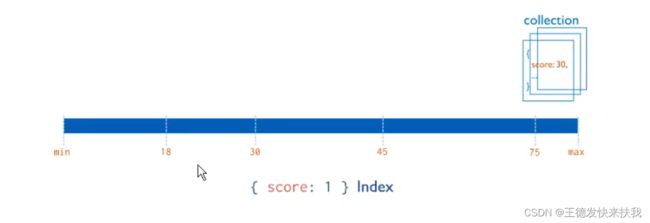
①单字段索引
为指定字段创建升序/降序索引,排序不是很重要,因为MondoDB可以在任何方向进行遍历
②复合索引
类似就是如果第一个字段信息相同的话,按照第二个字段的信息排序,多个字段也是类似的

③其他索引
地理空间索引,文本索引,哈希索引

3)索引操作
①查看一个集合中的索引
db.collection.getIndexs()
②创建索引
db.collection.createIndex({字段名:1/-1,字段名:1/-1},options)
③删除索引
db.collection.dropIndex(索引名)
db.collection.dropIndexs();//删除所有索引
4)索引使用
db.collection.find().explain();
查询语句的执行效率
5)涵盖的查询
如果查询条件和查询的投影只包含索引字段时,那么直接从索引里面拿数据了,效率很高
三、SpringBootData连接MongoDb
1、环境搭建
1)依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-mongodbartifactId>
dependency>
2)配置
spring:
data:
mongodb:
#服务器地址
host: zynight.club
#连接数据库
database: shopping
#默认是27017
port: 27017
2、实体类/持久层/服务层
1)实体类
索引可以大大提升查询效率,一般在查询字段上添加索引,索引的添加可以通过Mongo的命令来添加,也可以在Java的实体类中通过注解添
加。
@Document(collation = "shop_goods") //默认是类型的小写
public class GoodsMongo implements Serializable {
private static final long serialVersionUID = 1L;
@Id //如果属性名就是id,那么不用写
private Integer id;
/**
* 商品名
*/
@Field //字段属性
private String name;
}
2)持久层,提供基本的CRUD方法
public interface GoodsMongoMapper extends MongoRepository<GoodsMongo,Integer> {
}
3)服务层
4、关于mongodb和mysql不同点
1、主键
1)主键自增
每个文档中都有一个_id,是ObjectId类型,就是id可以为任意数据类型,应为mongodb是基于分布式的,那么保证多个系统id自增保持一致也很麻烦,所以不支持,但是我们可以通过获取总记录条数+1来实现,(但是存在一个严重的问题,如果你删除了中间某条数据,那么插入的新文档的id指向最后一条数据的id,必会出错,建议获取当前的最大id自增),而且随机生成的id还带了时间戳,不需要在设置时间字段,每个文档的数据类型都是独立的,
2)整型插入和自定义主键
自定义主键:在实体类中的id默认是对比的数据库中的_id字段,如果想要自定义字段,那么需要加上@Field(“id”)属性
整型插入:在命令行执行时,需要插入整型必须带上NumberInt(2),才可以,不然默认都是double类型的,在项目中使用JPA插入,只要数据类型是int类型即可
2、连接查询
根据查询出来的ID遍历在查询一次
3、mysql数据转移到mongodb中
将得到的数据直接inert就可以