PostGIS系列课程之空间索引
空间索引
回想一下,空间索引是空间数据库的三个关键功能之一。索引使使用空间数据库处理大型数据集成为可能。如果不建立索引,则对功能的任何搜索都将需要对数据库中的每个记录进行“顺序扫描”。通过将数据组织到可以快速遍历以查找特定记录的搜索树中,可以加快索引的搜索速度。
空间索引是PostGIS的最大能力之一。在前面的示例中,建立空间联接需要将整个表相互比较。这可能会非常耗时:将两个10,000条记录的表连接起来,每个表没有索引将需要100,000,000个比较;使用索引的成本可能低至20,000次比较。
当我们加载nyc_census_blocks表时,pgShapeLoader自动创建一个名为nyc_census_blocks_geom_idx的空间索引。
为了演示索引对性能的重要性,让我们在没有空间索引的情况下搜索nyc_census_blocks。
我们的第一步是删除索引。
DROP INDEX nyc_census_blocks_geom_idx;
注意
DROP INDEX语句从数据库系统中删除现有索引。 有关更多信息,请参见PostgreSQL [documentation](https://www.postgresql.org/docs/7.4/interactive/sql-dropindex.html)。
现在,观看pgAdmin查询窗口右下角的Timing表,然后运行以下命令。 我们的查询会在每个人口普查区中进行搜索,以识别Broad Street条目。
SELECT blocks.blkid
FROM nyc_census_blocks blocks
JOIN nyc_subway_stations subways
ON ST_Contains(blocks.geom, subways.geom)
WHERE subways.name = 'Broad St';
-------------------------------
blkid
-----------------
360610007001009
nyc_census_blocks表非常小(只有几千条记录),因此即使没有索引,查询在普通的测试计算机上也仅花费 55 ms 。
现在重新添加空间索引,然后再次运行查询。
CREATE INDEX nyc_census_blocks_geom_idx
ON nyc_census_blocksUSING GIST (geom);
注意
USING GIST子句告诉PostgreSQL在建立索引时使用通用索引结构(GIST)。 如果在创建索引时收到的错误看起来像“错误:索引行需要11340个字节,最大大小为8191”,则您可能忽略了添加“使用中的GIST”子句。
在我的测试计算机上,时间降至 9毫秒 。 表越大,索引查询的相对速度改进就越大。
空间索引是如何工作的?
标准数据库索引根据要索引的列的值创建层次结构树。
空间索引略有不同-它们无法自己为几何特征建立索引,而是无法为特征的边界框建立索引。
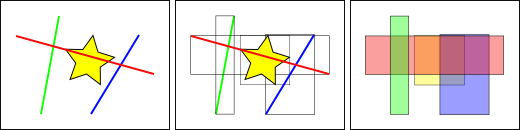
在上图中,与黄色星星相交的线数是 即红色线 。 但是与黄色框相交的要素的边界框是 两个 ,红色和蓝色的。
数据库有效回答“哪些线与黄星相交”问题的方式是,首先使用索引(非常快速)回答“什么框与黄框相交”问题,然后对“哪些线与黄星相交”进行精确计算。
仅适用于首次测试返回的那些功能。
对于大表,这种先评估近似索引然后进行精确测试的“两次通过”系统可以从根本上减少回答查询所需的计算量。
PostGIS和Oracle Spatial都共享相同的"R-Tree" [^ 1] 空间索引结构。 R-Tree将数据分解为矩形,子矩形和子子矩形等。它是一种自调整索引结构,可以自动处理可变数据密度和对象大小。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q69tgMdc-1601056280991)(https://katacoda.com/embed/crunchydata/courses/postgis/indexing/assets/index-01.png)]
注 1. http://postgis.net/docs/support/rtree.pdf
仅索引查询
PostGIS中的大多数常用功能(ST_Contains,ST_Intersects,ST_DWithin等)都自动包含一个索引过滤器。 但是某些函数(例如,ST_Relate)不包含和indexfilter。
要使用索引进行边界框搜索(不进行过滤),请使用&&运算符。 对于几何图形,&& 运算符的含义是“边界框重叠或接触”,对于数字而言,=运算符的含义是“值相同”。
让我们将WestVillage人口的仅索引查询与更精确的查询进行比较。 使用&&,我们的仅索引查询如下所示:
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON neighborhoods.geom && blocks.geom
WHERE neighborhoods.name = 'West Village';
------------------------------------
49821
现在,我们使用更精确的ST_Intersects函数进行相同的查询。
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON ST_Intersects(neighborhoods.geom, blocks.geom)
WHERE neighborhoods.name = 'West Village';
---------------------------------
26718
答案要低得多! 第一个查询总结了与邻域边界框相交的每个块; 第二个查询仅汇总了与邻域本身相交的那些块。
分析和清理索引
分析
违反直觉的,,进行索引搜索并不总是较快:如果搜索要返回表中的每个记录,遍历索引树以获取 每个记录实际比仅从头开始线性转化整个表要慢。
为了弄清楚它正在处理什么情况(读取表的一小部分而不是读取表的一大部分),PostgreSQL在每个索引表列中保留有关数据分布的统计信息。 但是,如果您在短时间内迅速更改表的组成,则统计信息不会是最新的。
为了确保您的统计信息与表内容匹配,明智的做法是在您的表中加载和删除大容量数据后运行“ ANALYZE”命令。这将使统计系统收集所有您的索引列的数据。
ANALYZE命令要求PostgreSQL遍历表并更新其用于查询计划估计的内部统计信息(查询计划分析将在后面讨论)。
ANALYZE nyc_census_blocks;
清理
值得强调的是,仅创建索引不足以允许PostgreSQL有效地使用它。每当创建新索引时或在对表发出大量UPDATE,INSERT或DELETE之后,都必须执行VACUUMing。 VACUUM命令要求PostgreSQL回收更新或删除记录所留下的表页中任何未使用的空间。
清理对于数据库的高效运行至关重要,因此PostgreSQL提供了“自动清理”选项。
默认情况下启用此功能,将根据活动级别确定的合理时间间隔自动抽真空(恢复空间)和分析(更新统计信息)表。尽管这对于高事务性数据库是必不可少的,但建议不要在添加索引或批量加载数据之后等待自动清空。如果执行了大批量更新,则应手动运行VACUUM。
可以根据需要分别执行清理和分析数据库。发出VACUUM命令不会更新数据库统计信息;同样,发出ANALYZE命令将不会恢复未使用的表行。这两个命令都可以针对整个数据库,单个表或单个列运行。
VACUUM ANALYZE nyc_census_blocks;
