cuda学习
什么是cuda
cuda是带有并行内核的串行代码,全部由c/c++编写,串行代码在host端串行执行,并行内核代码在device短的多线程中执行。
- cuda是用于在英伟达gpu上编程的编译器和工具
- 支持gpu的异构计算
- cuda API扩展了c/c++编程语言
- 快速SIMD并行性
- 从硬件上提供了高级别的抽象
cuda编程流程

- 从host端将数据拷贝到device端
- 呼叫gpu告诉gpu启动
- 在gpu上运行计算
- 将计算完后的device上的数据拷贝到host端
kernel是CUDA中一个重要的概念,kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用<<
cuda主要通过函数限定词来区分host和device上的代码:
global:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
device:在device上执行,单仅可以从device中调用,不可以和__global__同时用。
host:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
软件映射
软件:grid->block->thread
硬件:gpu(device)->sm->core(核心)
注:在gpu上每32个线程一个worp每一个worp中执行的命令必须是相同的,相当与每32个线程一组
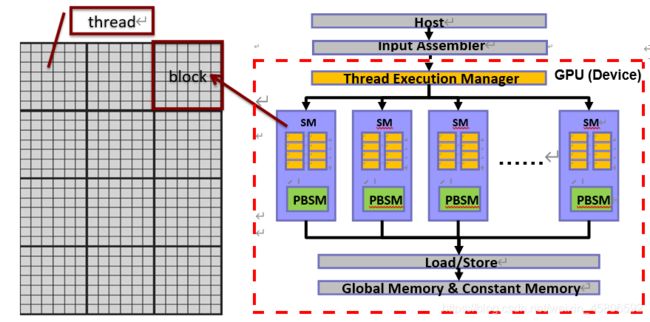

grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺少时值初始化为1
dim3 grid(3, 2);
dim3 block(5, 3);
kernel_fun<<< grid, block >>>(prams…);
一个线程需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识,它们都是dim3类型变量,其中blockIdx指明线程所在grid中的位置,而threaIdx指明线程所在block中的位置
gridDim可以得到一个grid中一行或一列中最大的block数目,同理blockDim可以得到一个block中一行或一列中最大的thread数目
注:排序方式与数组的排序方式不同切勿混淆(在计算thread在全局的位置时一定要注意)


cuda内存模型
每个线程有自己的私有本地内存(Local Memory),而每个线程块有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。此外,所有的线程都可以访问全局内存(Global Memory)。还可以访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)


cuda程序的编写
内存的分配
gpu内存
cudaMalloc((void**)&ad,size)
在device端的global memory上分配内存空间
需要两个参数:
1.指向待分配内存地址的指针
2.待分配内存的大小
cudaFree(ad)
从device端的global memory 上释放内存
参数:指向待释放内存的指针
cpu内存
cudaMallocHost((void**)&ad,size)
申请host内存
cudaFreeHost(ad)
释放host内存
注:如果CPU上申请的不是普通内存而是host内存的话数据传输速度会快将近一倍
统一(unified)内存
cudaMallocManaged((void**)ad,size,unsigned int flags=cudaMemAttachGlobal)
flags=cudaMemAttachGlobal内存可以被任意服务器访问(CPU,GPU)
flags=cudaMemAttachGhost内存只能被cpu访问
cudaFree(ad)
释放内存
共享内存
shared
每个线程块都有自己的共享内存,在gpu端kernel函数中被定义
shared float sData[258];
数据传输
cudaMemcpy(ad,a,size,cudaMemcpyHostToDevice)(同步拷贝)
内存数据传输
四个参数:
1.指向目标数据的指针
2.指向源数据的指针
3.需要传输的数据量
4.传输的方向HostToHost/HostToDevice/DeviceToHost/DeviceToDevice
cudaMemcpuAsync(ad,a,size,cudaMemcpyHostToDevice,cudaStream_t stream=0)(异步拷贝)
stream如果非0可能与其他stream操作有重叠
cuda函数声明
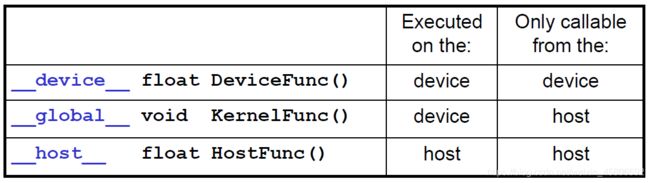
__global__定义一个kernel函数,必须返回void类型
__host__和__device__可以一起使用编译器会将其翻译为host和device通用的函数
__device__函数没有函数地址也没有指向该函数的指针
在device端执行的函数有以下限制:
1.没有递归
2.函数内部没有静态变量
3.参数的数量是固定的
__syncthreads() 同步所有的线程,函数之后的代码不会执行,只有当所有线程全部到达时才会开始继续执行
cuda时间记录
cudaEvent_t start,stop;创建相关变量
cudaEventCreate(&start);开始创建事件
cudaEventCreate(&stop);停止创建事件
cudaEventRecord(start);开始记录事件
cudaEventRecord(stop);停止记录事件
cudaEventSynchronize(stop);同步所有事件
cudaEventElapsedTime(&time, start, stop);计算事件持续时间
或者
clock_t 变量=clock();开始
clock_t 变量=clock();结束
相减得到时间
cuda示例
矩阵相加
//#include矩阵相乘

//#include