NER实战之数据预处理:(NLP实战/命名实体识别/文本标注/Doccano工具使用/关键信息抽取/Token分类/源码解读/代码逐行解读/文本BIO处理/文本分类/序列标注)
数据处理解读
训练所有NER的项目代码我个人都不会超过200行,因为很多地方的处理在Hugging Face中都有现场的模块可以调用。这部分的内容会将代码逐行解读哦,这才是真正有价值的内容哦。
5.1 数据读取
在我们的文件中data文件夹有三个数据,我这里就直接偷懒了,训练、验证、测试全都是一样的数据,都和BIO脚本的处理产生的文件相同:
看我们的train.py的代码,首先指定一下数据的位置:
data_dir = '.\data'将训练、验证、测试的数据集的数据都读进来:
train_texts, train_tags = read_data(data_dir + '\\train.txt')
test_texts, test_tags = read_data(data_dir + '\\val.txt')
val_texts, val_tags = read_data(data_dir + '\\test.txt')这里有一个专门读数据的函数read_data,进入到这个函数中,首先是将数据读取进来:
file_path = Path(file_path)
raw_text = file_path.read_text(encoding='UTF-8').strip()
raw_docs = re.split(r'\n\t?\n', raw_text)这里解释一下,在我们的数据中,我们用空行为间隔将每一行的样本隔开。然后我们开始遍历样本:
token_docs = []
tag_docs = []
for doc in raw_docs:
tokens = []
tags = []
for line in doc.split('\n'):
token, tag = line.split(' ')
tokens.append(token)
tags.append(tag)
token_docs.append(tokens)
tag_docs.append(tags)第一个for循环是遍历每一个样本,第二个for循环是遍历每一个样本的每一个字。最后的返回值:
return token_docs, tag_docs- token_docs存的是所有的数据
- tag_docs存的是所有的标签
5.2 数据封装
训练、测试、验证三个数据集都进行了read_data函数的处理,现在将处理的数据进行封装:
unique_tags = set(tag for doc in train_tags for tag in doc)
tag2id = {tag: id for id, tag in enumerate(unique_tags)}
id2tag = {id: tag for tag, id in tag2id.items()}
label_list = list(unique_tags)所有的标签是什么存在了unique_tags
- unique_tags :整个标签
- tag2id:标签名字对应的id
- id2tag: id对应的标签名字(预测的时候,预测0-6的数字,再用这个字典转换成标签名字)
- label_list :将所有的标签转换成list
此时我们已经完成了分词了,后面做tokenizer只需要记住对应的id就行了
5.3 encoding
from transformers import AutoTokenizer, BertTokenizerFast #is_split_into_words表示已经分词好了
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
train_encodings = tokenizer(train_texts, is_split_into_words=True, return_offsets_mapping=True, padding=True, truncation=True,max_length=512)
val_encodings = tokenizer(val_texts, is_split_into_words=True, return_offsets_mapping=True, padding=True, truncation=True,max_length=512)- 第一行:导入Hugging Face提供的自动分词器的包、词嵌入向量的预训练模型包
- 第二行:导入一个中文的预训练的词嵌入模型
- 第三行:对训练集进行词嵌入操作
- 第四行:对验证集集进行词嵌入操作
tokenizer参数解析:
tokenizer(train_texts, is_split_into_words=True, return_offsets_mapping=True, padding=True, truncation=True,max_length=512)- train_texts:训练数据变量名
- is_split_into_words:当前输入文本是否已经完成了分词,tokenizer只需要完成id的映射
- return_offsets_mapping:返回一个offset,后面会解释我们为什么需要一个偏移的offset
- padding:补长
- truncation:截断
- max_length:bert定义的最大长度
如果你对这些参数都完全不明白的话,你应该先阅读一下这篇文章:
Hugging Face实战(NLP实战/Transformer实战/预训练模型/分词器/模型微调/模型自动选择/PyTorch版本/代码逐行解析)上篇之模型调用_会害羞的杨卓越的博客-CSDN博客
现在我们有很多变量,进入pycharm的debug界面,看看有哪些变量,都是什么意思:

我们的每一个样本都会转换成input_ids:

这个token_type是什么意思?就是当前的词属于那句话
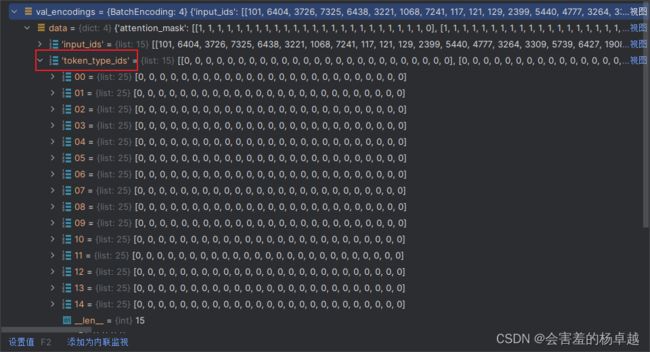
我们的这个任务,每个文本都是一句话,所以全是0
而这个attention_mask是我们在做self_attention的时候,是记录那些话需要计算attention的
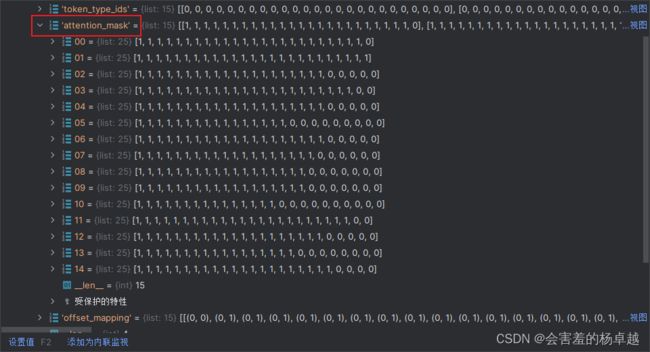
1表示是一个实际的词,为0的表示加的padding。
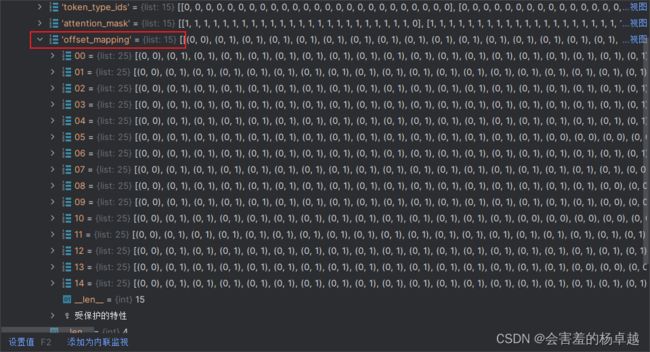
offset_mapping是偏移量是表示标签应该如何对应的,这个很有用,但是我们还是先不解释,后面会解释。
这几行代码就是把文本转换成对应的id,等下要输入模型的东西。
5.4 制作标签
接下来制作标签的对应,分别是训练集和验证集:
train_labels = encode_tags(train_tags, train_encodings)
val_labels = encode_tags(val_tags, val_encodings)在做完tokenizer后,序列会变长一些,因为会加入一些特殊字符,比如最常见的cls分类特殊字符。进入到encode_tags函数中,现在需要做编码完后的标签对应关系:
def encode_tags(tags, encodings):
labels = [[tag2id[tag] for tag in doc] for doc in tags]
#print(labels)
encoded_labels = []
for doc_labels, doc_offset in zip(labels, encodings.offset_mapping):
# 创建全由-100组成的矩阵
doc_enc_labels = np.ones(len(doc_offset),dtype=int) * -100
arr_offset = np.array(doc_offset)
# set labels whose first offset position is 0 and the second is not 0
if len(doc_labels) >= 510:#防止异常
doc_labels = doc_labels[:510]
doc_enc_labels[(arr_offset[:,0] == 0) & (arr_offset[:,1] != 0)] = doc_labels#offset-mapping中 [0,0] 表示不在原文中出现的内容
encoded_labels.append(doc_enc_labels.tolist())
return encoded_labels首先拿到labels:
labels = [[tag2id[tag] for tag in doc] for doc in tags]将偏移量和标签做成对应关系:
labels,encodings.offset_mapping
这是第一个样本的偏移量:
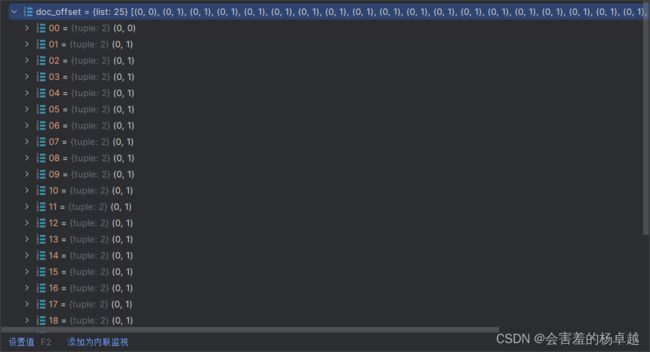
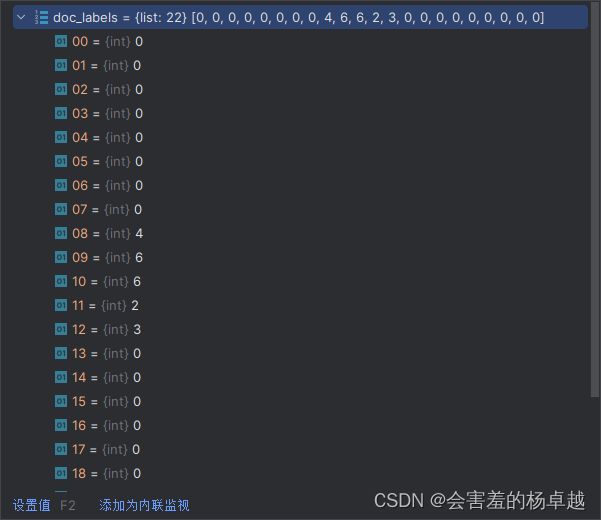
这是第一个样本所对应的一个实际标签:
偏移量表示什么意思,马上就来了:
第一步制作一个由-100组成的矩阵:
doc_enc_labels = np.ones(len(doc_offset),dtype=int) * -100-100在计算attention的时候,相当于不会参与到计算,即无用的信息。这个-100的矩阵只是一个初始化。在经过tokenizer的编码后,最少会给你加两个特殊字符,最长长度不可以超过512,加上两个字符不可以超过510,所以加上一个限制条件:
if len(doc_labels) >= 510:#防止异常
doc_labels = doc_labels[:510]所以偏移量参数到底是什么意思呢?
在我们所有文本中,我们会按照最长的那条为基准,将其他的都加上padding(补0操作)让他跟最长的一样长,然后在进行tokenizer后,第一个开始字符和最后一个结束字符也是不参数计算self-attention的,所以一条文本在经过embbeding后需要把这些标记出来,只有有效的内容才需要需要计算self-attention。
在pycharm的debug模式中,当前的偏移量参数的值:
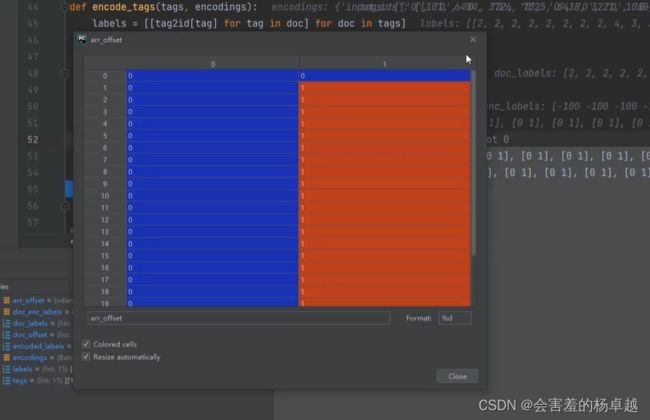
如果两个都是0,则表示不参与计算self-attention,也就不需要制作标签