POLARDB 到底打倒了谁 PPT 分享 (文字版)
开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等数据库问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请加微信号 liuaustin3 ,在新加的朋友会分到3(共1130人左右 1 + 2 + 3)
在上周3分享完后,有些同志直接找到我,问能不能分享相关的PPT内容,今天就将相关的内容进行分享,同时视频可以去盘古云课堂查看当天视频记录,不清楚的同学可以加 hh18500689520 微信号,询问如何观看。

大家好,非常感谢今天进入直播间的老师们,同学们,同时也非常感谢两个平台给与此次分享的支持,盘古云课堂和POSTGRESQL分会。
今天要和大家分享的是一年多不到两年对于POLARDB 的一段学习和使用的经验,题目是POLARDB 打败了谁,基于我们现在时代快速的发展,打败这个词经常被用到,基于逻辑惯性的思维模式,一般打败康师傅方便面的不在是统一干脆面,而是外卖,打败诺基亚的,不是苹果,而是手机操作系统。
而基于数据库,也早已不是打败MYSQL的可能是POSTGRESQL,打败这个词更加的综合了,更不按逻辑出牌了。

大家好,非常感谢今天进入直播间的老师们,同学们,同时也非常感谢两个平台给与此次分享的支持,盘古云课堂和POSTGRESQL 分会。
今天要和大家分享的是一年多不到两年对于POLARDB 的一段学习和使用的经验,题目是POLARDB 打败了谁,基于我们现在时代快速的发展,打败这个词经常被用到,基于逻辑惯性的思维模式,一般打败康师傅方便面的不在是统一干脆面,而是外卖,打败诺基亚的,不是苹果,而是手机操作系统。
而基于数据库,也早已不是打败MYSQL的可能是POSTGRESQL,打败这个词更加的综合了,更不按逻辑出牌了。
在分享之前,这里做一个免费的公益广告,如同POSTGRESQL 业界的大佬 “德哥”的标签,公益是一辈子的事情,基于德哥一直在为POLARDB开源版本工作,这里我们有一个POALRDB 开源方面的认证,,如果大家有兴趣可以参加。

在开始今天的分享我们先需要了解今天主要的分享的内容,主要分为4个部分,分别为 POLARDB 是什么,POLARDB 怎么改变了开发人员对于使用数据库的习惯,POALRDB 从成本的角度征服了谁 以及POALRDB 实际的使用中的解决问题的案例。
基于今天时间的问题,我们马上开始,首先POLARDB 是什么,实际上从我了解的状态上来说,大部分包含专业的人士,都可能没有彻底的完全的了解POLARDB是什么?
为什么这样说,基于我们数据库分享群中以及在其他的一些比较大的群中,对于POLARDB 是什么的一些回答,我们也可以看出,的确是很又意思,基本上都在摸大象,众人摸POLARDB 就是这样来的。基本上没有说稍微完整的。

到底什么是POLARDB, POLARDB 是一个数据库的名词,还是一个品牌,这是我们需要搞清楚的。下面是一张我绘制的POLARDB 的体系图,从图中可以看出,POALRDB 本身不是一个数据库,是一个群体数据库的统称,或者可以称之为一个体系,所以把POLOARDB 单独认为是一个数据库的看法,想法,认知是不完整的。
基于POLARDB打败了谁,首先我们需要先把POLARDB 是什么搞清楚?在我了解的POALRDB 本身他不是一个数据库,他是一个数据库产品体系的总名称,以北京紫禁城为例,皇帝住在紫禁城,但是具体皇帝住在哪个宫殿,也是有宫殿的名字的,POLARDB 相当于紫禁城,但是实际的数据库确实里面一座座的宫殿集合组成后的紫禁城,而简简单单的把一个体系认为是一个数据库本身,是欠缺的。
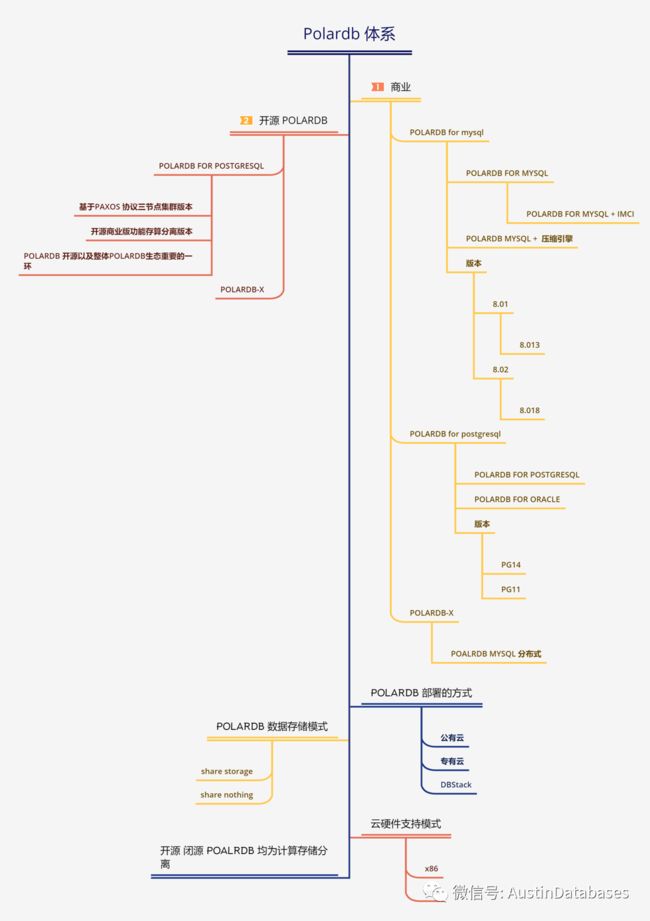
这里我放大一下图片,实际上POALRDB 可以通过不同的维度来切分出很多的维度
1 从开源和闭源切
2 从数据库兼容性切
3 从版本切
4 从部署的方式来切
5 从硬件结构切
6 从数据存储使用的方式来切
7 从单体和分布式数据库形成方式上切
8 从内部的数据库引擎来切
基于个人能力和时间的关系,今天仅仅能从POLARDB FOR MYSQL 这个体系来去说,即使是这样,这样单独的一个分之,单独挑出来POLARDB for mysql 本身也可以切出很多部分,如 列式,归档引擎,ARM,X86 ,8.01 ,8.02 ,5.X 。
如果用一句话来描述POLARDB 是什么,可以简单概括,POALRDB 是一组数据库产品的统称,其中基于商业版本的POALRDB 主要以 POLARDB FOR MYSQL ,POLARDB FOR POSTGRESQL , POLARDB FOR ORACLE 以及POLARDB -X 组成,开源数据库是基于POSTGRESQL 为原型的兼容的POLARDB FOR POSTGRESQL 为主题的,数据库产品的集合。
那么今天我们要和大家拿出来分享的是 POLARDB FOR MYSQL 这样一款POLARDB 体系里面的产品,基于阿里云POALRDB 商业板块的一部分。

从上图中我们可以看到简易的POLARDB 的架构图,实际上POLARDB对于开发者和DBA 来说,他并不是一个需要全部从新学习的数据库,如果你是 MYSQL ,POSTGRESQL, ORACLE 的DBA ,如果你不想理解他的架构,他在使用上,是可以和原有的知识相互补偿的。
为后面我讲授的简单,这里后面所有的讲授将基于POLARDB FOR MYSQL 来进行,并且为了简单,这里称呼POLARDB FOR MYSQL 为POLARDB ,特此声明。
在我们看到的简易架构图本身,和其他的一些数据库看似并无太大的区别,实际上POLARDB 在和其他的数据库有根本性的不同。
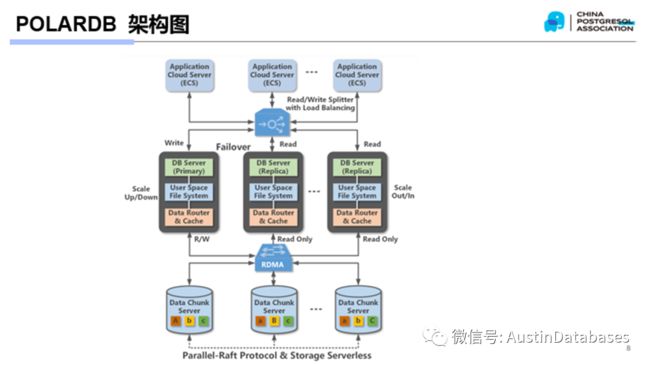
从架构图上看,POALRDB FOR MYSQL ,简称POLARDB ,本身是基于一个硬件体系而变换而来的数据库产品,也就是说,POLARDB 本身的硬件与我们传统的硬件是不一样的。
其中一个重要的特性是 RDMA ,REMOTE DIRECT MEMORY ACCESS
我们从相关POLARDB的白皮书中获得如下信息
1 通过硬件来优化全局闩锁的问题,提高了并发的访问性
2 允许脏页刷新出内存,但一段时间不需要刷新到存储中
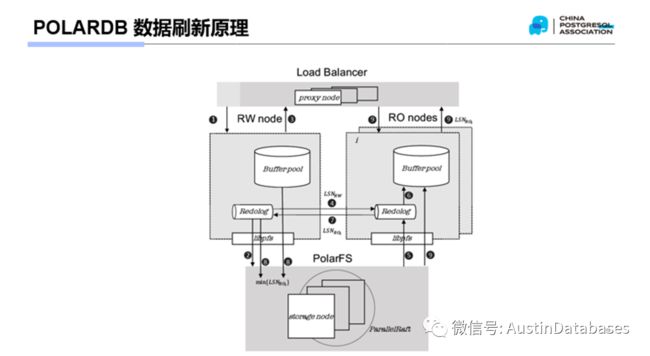
说到存储,POALRDB本身对于存储采用了非常规的方式,采用了自研的POLARDBFS 作为存储对外的服务对象,这里POLARDBFS 本身是具有副本的,也就是在存储硬件和数据存储格式上,完全支持数据不丢失和数据冗余存储,实际上他是1写三采用了 parallel raft 并行RAFT的协议,数据库本身是不负责数据高可用的,高可用在数据存储池进行。从上图看,POALRDB的REDO LOG 本身并不直接通过存储来实现同步,而是在内存中进行了进行了REDO状态的同步,基于所有节点共享一个存储设备的基础上,数据的同步基本上抛弃了通过缓慢网络的方式进行节点之间信息传递的方式。
从这里看出,POALRDB FOR MYSQL 在底层的结构中无论从硬件还是数据库基础结构上来说,和MYSQL没有半毛钱关系。
如果对此部分感兴趣,可以参考
MYSQL POLARDB 学习系列之 拆解 POLARDB 2 原理与实现(翻译)
https://mp.weixin.qq.com/s?__biz=Mzg4NDA0NTEwNA==&mid=2247495817&idx=1&sn=60fe109de99ab6f391b5e255fa50ba16&chksm=cfbc94d6f8cb1dc0b32831d6f641a6239ff484a53c103198068987596d87ac845dfb5dadcb14&scene=21#wechat_redirect
在粗略的分享了相关的什么是POLARDB 和 POALRDB FOR MYSQL 的部分内容后,我们下一步需要看看POLARDB 到底打败了什么
实际上如同我前面提到的,打败康师傅的不是统一,是外卖,POALRDB 打败的可能也不是一个具体的数据库,而是一种数据库的使用习惯。我们以我们习以为常的开发中,经常DISS MYSQL的读写分离实现困难的问题来说。因为什么,因为异步,因为你不知道你任何一刻的主库和从库的数据是否是一致的,应用程序必须通过业务的逻辑判断,这就导致应用程序还要承担一部分基础设施需要的工作,所以这样的结构,必然是遭人嫌弃。

MYSQL 的异步复制传统结构
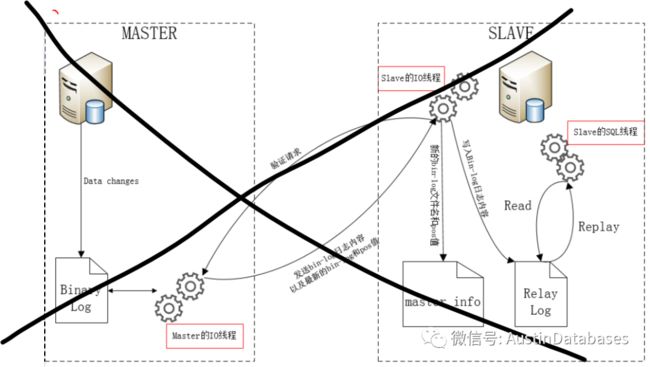
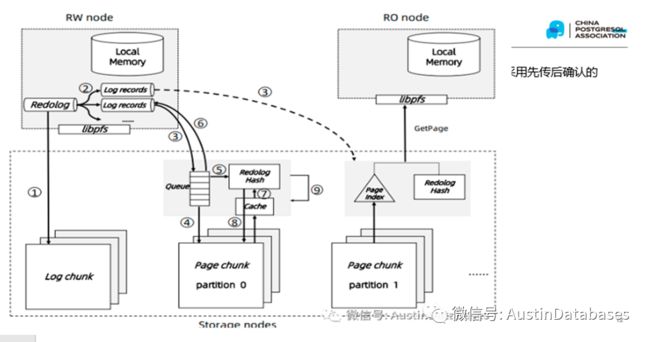
那么我们反过来看一张POLARDB 的读写节点分享数据的方式,在其中我们并未有发现通过网络来进行数据分享的传统方式,实际上POLARDB 本身是不需要进行传统MYSQL的 BINLOG 模式的信息传递放方式,通过重放relay log的模式来进行,而是很直接的物理数据块填补到内存的方式
所以MYSQL 的问题,在POALRDB 是不会存在的,可以说硬件+新的架构 = 数据主从节点数据基本同步的 MYSQL
当然这里对于原理有更多需要解释的部分,但在我们使用的1年多的时间,数据主从节点异步的问题,在使用POLARDB 开发的脑子里面消失了。
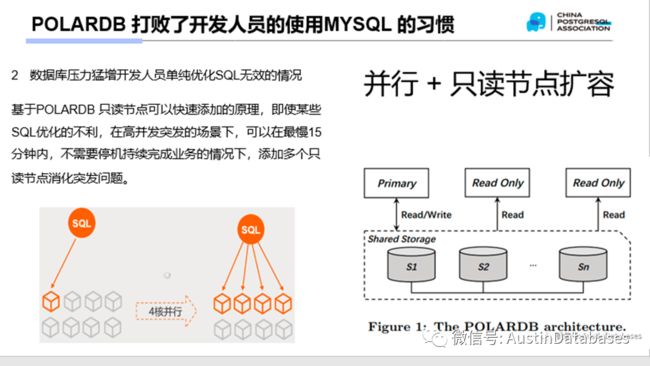
针对开发和系统的稳定性,这一直是一个成本的问题,系统的稳定性和投入是有性价比的,如果投入是1,得到是0.5 那么必然是一个失败的投入。
我们还以开源MYSQL为例,MYSQL 本身是无法完全榨取现在硬件的资源的,这主要基于数据计算的并行,一个无法完全利用数据库硬件的数据库,本来就是有问题的,所以并行的能力在商业数据库是一个 潜规则,没有并行的商业数据库注定是要被淘汰的。
POALRDB 本身是原生支持并行的计算,也就是POLARDB 本身在设计之初就是为了榨取硬件的能力而设计的,无论是超高速的磁盘,还是多核心的CPU ,对于POLARDB 是越快越好,越多越好。最终决定了POALRDB 本身是适合在更大型的应用程序去使用的数据库产品,比如ORACLE TO MYSQL ,不如ORACLE TO POLARDB 更实在更稳定更让人放心。
1 基于只要硬件充足就可以并行SQL的能力
2 基于读写多节点的设定
3 基于数据读写节点数据基本同步的设计
4 数据在存储层解决数据高可用的特点
开发人员不在考虑,应用程序面对MYSQL 那堆的问题,只需要写好自己的程序逻辑,注意事务的拆分即可

在此基础上,POALRDB还是没有放过传统的数据库,将现在大家都知道,但是没有怎么用过的HTAP技术融入到数据库本身,基于MySQL人尽皆知的OLAP 肌无力的问题,一般我们都是通过CLICKHOUSE 等数据库来弥补MySQL天生的问题,但是随之带来的结构复杂化的问题,让整体的系统充满了不确定性,同时还是存在数据延迟不同步的问题。
POALRDB IMCI 技术的加入,让”POLARDB FOR MYSQL “ 变成了一个,可以和一些传统其他数据库如ORACLE ,PostgreSQL 在大SQL处理中的能力可以进行PK的产品,让这个看着像MYSQL的数据库并不输给曾经的MYSQL 惧怕的那些对手一个短板又被弥补了。
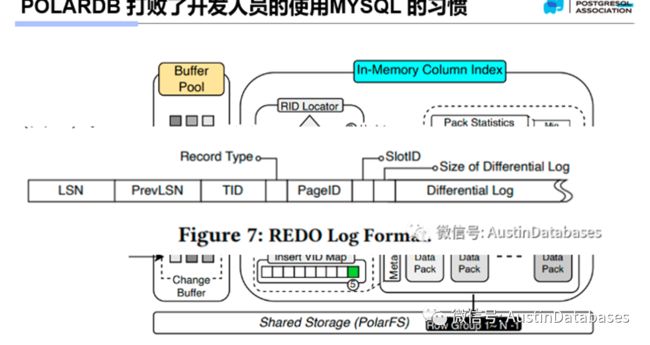
IMICI 功能并不是和某些数据库一样,臃肿的东西,他是一个灵活的,同时并不假大空的说自己是一个 OLAP + OLTP 的完美数据库,因并不定位与纯OLAP 的功能PK的产品,而是解决我们目前,MYSQL 解决不了问题的解决方案,本身IMCI 基本数据与行式是同步的,所以也不存在 MYSQL CLICKHOUSE的数据同步问题,同时,基于你要那个表有OLAP的功能的定义,IMCI 并不是对整个库进行复制,而是列级别的复制,所以数据量小了,自然复制同步以及性能的问题就不存在了。


那么我们在通过POALRDB打败了开发人员使用传统数据库的习惯后,让其依赖了POALRDB 的舒适性功能,剩下的POLARDB 要打败的就是老板 BOSS。因为老板是不会关心你什么你,他什么他, 什么ORACLE , PG ,MYSQL ,那个成本最低,我要那个,技术问题你们解决。

POALRDB 上来可以放一个大招,空间收缩透明化,数据库在用时间长了,最大的问题就是存储的问题,存储无限的上涨,而数据库的磁盘空间无法释放给系统,这是一个看似无法解决的问题。
基于POALRDB 的POLARFS 的存储结构,页面变为了4KB 一个,同时基于存储符合云计算的,用多少,花多少钱的设计原理,基于POALRDB 的解决方案,将看重成本的以及数据库性能,注重成本费用核算的老板们,深深的被吸引住,从他们之前对于POALRDB 的不信任,到后来催促将 MYSQL 数据库产品更换为POALRDB 的急迫性,因为每月的账单已经说服了老板。

除此之外,关于数据误删除 修改后,基于POLARDB 可以快速的进行单表恢复到发生数据删除前。这个问题也是传统 RDS 产品没有相关的的功能。
你可以随时提出,误删除一个表后,恢复到删除前一刻的表的状态的需求,并且这些都不需要做复杂的整体数据库的恢复操作,在从中找到数据,而是单表恢复,你只需要告诉他你要那个表回到什么状态,此时你就得到一个另一个历史时刻的表,彻底的将那些 传统的理念 和 DBA 的复杂的工作,打的稀碎。

从业务的角度,产生一个节点在传统RDS 产品中是一个很慢的工作,这与数据库的体量有关,但是在POALRDB 中,产生一个从节点本身与数据库体量并无直接关系,所以产生一个节点的时间成本非常低。
在POALRDB中 纵向 横向 ,IMCI 等节点的添加的速度在我们实际工作中,最慢的产生一个1T 可以立即投入工作,接受访问的,实测在8分钟。从时间的角度 就打败了传统的RDS 工作的流程和方式。

最后我们说说数据归档的问题,在我们传统的数据库归档中都是将数据抽离,然后形成文件来进行数据的保存,但是在有些场景下,数据是冷数据,但并不是不读取,怎么办,或者数据库有时候会进行查询,为客户相关的一些诉求,传统的归档很难解决问题,同时如果恢复归档的数据还原,将是人力物力最大的浪费。
POALRDB 在具有INNODB 引擎的之外还有 X-ENGINE 的引擎,这个引擎支持数据查询的基础上,将数据压缩原有大小的50% - 30% 的大小。问题解决了,还没花几个钱,老板, 笑哈哈。





写到最后,在当前国内数据库行业卷的出圈的情况下,数据库打败数据库的新闻经常见,但是如果数据库打败的对象,不是另一个数据库,而是使用数据库的习惯,使用者根本不用关心他是什么,用原来MYSQL的一切习惯经验不改变,但是就是比原来的感受要好,那么这倒是有点意思 !!!!
