ApacheCon - 云原生大数据上的 Apache 项目实践
Apache 软件基金会的官方全球系列大会 CommunityOverCode Asia(原 ApacheCon Asia)首次中国线下峰会将于 2023 年 8 月 18-20 日在北京丽亭华苑酒店举办,大会含 17 个论坛方向、上百个前沿议题。
字节跳动云原生计算团队在此次 CommunityOverCode Asia 峰会中深度参与并进行相关主题演讲,由 8 位同学围绕 4 个专题下的 6 个议题,分享 Apache 开源项目在字节跳动业务中的实践经验。此外,Apache Calcite PMC Member、Apache Flink Committer 李本超将参与 Keynote 演讲,分享参与开源贡献的经验与收获。
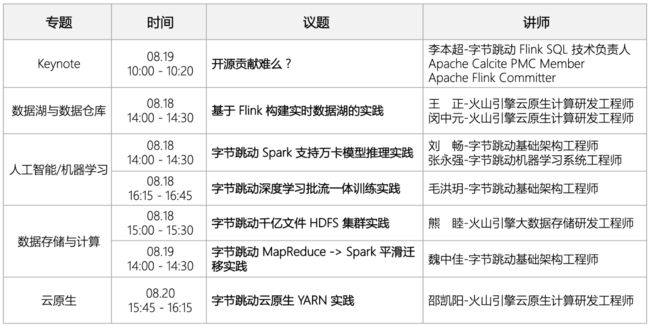
主题演讲
开源贡献难吗?
也许很多同学都有想过参与一些开源贡献,来提升自己的技术能力和影响力。但是理想跟现实之间通常有一些距离:因为工作太忙,没有时间参与;开源项目门槛太高,不知道怎么入门;尝试过一些贡献,但是社区响应度不高,没有坚持下去。本次 keynote,李本超会结合自己的经历,分享他在贡献开源社区过程中的一些小故事和思考,如何克服这些困难,最终在开源社区取得突破,并且在工作和开源贡献之间取得平衡。
李本超
字节跳动,Flink SQL 技术负责人
Apache Calcite PMC Member,Apache Flink Committer,毕业于北京大学,目前就职于字节跳动流式计算团队,Flink SQL 技术负责人。
专题演讲
专题:数据湖与数据仓库
基于 Flink 构建实时数据湖的实践
王正 火山引擎云原生计算研发工程师
闵中元 火山引擎云原生计算研发工程师
演讲简介:实时数据湖是现代数据架构的核心组成部分,它允许企业实时分析和查询大量数据。在这场分享中,我们将首先介绍实时数据湖目前存在的痛点,比如数据的高时效性,多样性,一致性和准确性等。然后介绍我们如何基于 Flink 和 Iceberg 构建实时数据湖,主要通过如下两部分展开:如何将数据实时入湖、如何使用 Flink 进行 OLAP 临时查询。最后介绍一下字节跳动在实时数据湖中的一些实践收益。
讲师简介:王正,于 2021 年加入字节跳动,就职于基础架构开放平台团队,主要负责 Serverless Flink 等方向研发;
闵中元,于 2021 年加入字节跳动,就职于基础架构开放平台团队,主要负责 Serverless Flink ,Flink OLAP 等方向研发。
专题:人工智能 / 机器学习
字节跳动深度学习批流一体训练实践
毛洪玥 字节跳动基础架构工程师
演讲简介:随着公司业务发展,算法复杂度不断提升,越来越多的算法模型在离线更新的基础上探索实时训练以提升模型效果。为实现复杂的离线和实时训练灵活编排、自由切换,能在更大范围内调度在离线计算资源,机器学习模型训练逐渐趋于批流一体化.本次将分享包括字节跳动机器学习训练调度框架的架构演进、批流一体实践、异构弹性训练等部分内容。并着重介绍在 MFTC(批流一体协同训练)场景下,多阶段多数据源混合编排、流式样本全局 Shuffle、全链路 Native 化,训练数据洞察等实践经验。
讲师简介:于 2022 年加入字节跳动,从事机器学习训练研发工作,主要负责大规模云原生批流一体 AI 模型训练引擎,支撑了包括抖音视频推荐、头条推荐、穿山甲广告、千川图文广告等业务。
字节跳动 Spark 支持万卡模型推理实践
刘畅 字节跳动基础架构工程师
张永强 字节跳动机器学习系统工程师
演讲简介:随着云原生的发展,Kubernetes 由于其强大的生态构建能力和影响力,使得包括大数据、AI 在内越来越多类型的负载应用开始向 Kubernetes 迁移,字节内部探索 Spark 从 Hadoop 迁移到 Kubernetes,使得作业云原生化运行。同时搜索有大量 GPU 需求量极大的离线批处理任务,随着潮汐任务上量,发现一系列问题:GPU 算力供给(卡时数)仍有较大缺口、单机房资源池规模无法匹配业务单位任务计算量增长、在线资源池算力浪费问题、缺乏统一平台入口。Spark 和 AML(应用机器学习)合作,通过 GPU 共享技术、混部 GPU 调度、Spark 引擎增强,平台及周边生态完善等途径,支持万张卡混部 GPU 模型推理离线计算,支持作业 80 亿多模态训练数据使用混部 GPU 7k 卡 7.5h 完成模型打分数据清洗,并且资源使用效率、稳定性均得到了显著提升。
讲师简介:刘畅,于 2020 年加入字节跳动,就职于基础架构批式计算团队,主要负责 Spark 云原生方向工作,Spark On Kubernetes 等方向研发;
张永强,于 2022 年加入字节跳动,就职于 AML 机器学习系统团队,参与构建大规模机器学习平台。
专题:数据存储与计算
字节跳动 MapReduce -> Spark 平滑迁移实践
魏中佳 字节跳动基础架构工程师
演讲简介:随着业务发展,字节跳动内部每天线上约运行 120 万 个 Spark 作业,与之相对比的是,线上每天依然约有两万到三万个 MapReduce 任务。作为一个历史悠久的批处理框架,从大数据研发的角度来看,MapReduce 引擎的运维面临了一系列问题。例如,框架更新迭代的的 ROI 较低,对于新的计算调度框架适配性较差等等。而从用户的角度来看, MapReduce 引擎的使用也存在一系列的问题。例如,计算性能不佳,需要额外的 Pipeline 工具管理串行运行的 Job,希望迁移 Spark 但是存量作业数量多且大量作业使用了 Spark 本身不支持的各种脚本。在此背景下,字节跳动 Batch 团队设计并实现了一套 MapReduce 任务平滑迁移 Spark 的方案,该方案使用户仅需对存量作业增加少量的参数或环境变量即可完成从 MapReduce 到 Spark 的平缓迁移,大大降低了迁移成本,并且取得了不错的成本收益。
讲师简介:2018 年加入字节跳动,现任字节跳动基础架构大数据开发工程师,专注大数据分布式计算领域,主要负责 Spark 内核开发、字节自研 Shuffle Service 开发。
字节跳动千亿文件 HDFS 集群实践
熊睦 火山引擎大数据存储研发工程师
演讲简介:随着大数据技术的深入发展,数据规模和使用复杂度越来越高,Apache HDFS 面临着新的挑战。在字节跳动,HDFS 即是传统 Hadoop 数仓业务的存储,也是存算分离架构计算引擎的底座,还是机器学习模型训练的存储底座。在字节跳动,HDFS 既搭建了服务于大规模计算资源调度跨多地区的存储调度能力提升计算任务稳定性;也提供了统合用户侧缓存、常规三副本、冷存的数据识别和冷热调度能力。本次分享介绍字节跳动内部如何认识新兴场景对传统大数据存储的新要求,并通过技术演进和运维体系建设,支持不同场景下的系统稳定。
讲师简介:主要负责大数据存储 HDFS 元数据服务演进和上层计算生态支持。
专题:云原生
字节跳动云原生 YARN 实践
邵凯阳 火山引擎云原生计算研发工程师
演讲简介:字节跳动内部离线业务具有庞大的规模,线上每天有数十万节点、数百万任务运行,每天使用的资源量达千万量级,内部由离线调度系统和在线调度系统分别负责离线业务和在线业务的调度管理。但随着业务规模发展,这一套系统暴露了一些短板:在离线属于两套系统,一些重大活动场景需要通过运维方式进行在离线资源转换,运维负担繁重,转换周期长;资源池不统一使得整体资源利用率不高,配额管控、机器运维等无法复用;大数据作业无法享受到云原生的各种好处,例如:可靠稳定的隔离能力、便捷的运维能力等。在离线系统亟待统一,而传统大数据引擎不是针对云原生设计难以直接云原生部署,各计算引擎和任务需要进行深度改造才能支持原先在 YARN 上的各种特性,改造成本巨大。基于此背景,字节跳动提出基于云原生的 YARN 解决方案 —— Serverless YARN,其 100% 兼容 Hadoop YARN 协议, Hadoop 生态下的大数据作业无需修改即可透明迁移到云原生系统上,在线资源和离线资源间可以高效灵活转换、分时复用,集群整体资源利用率得到显著提升。
讲师简介:在字节跳动基础架构负责离线调度相关工作,具有多年工程架构经验。
