扩散模型(DDPM)介绍
文章目录
- 扩散模型
- 扩散过程
-
- 前向过程
- 逆向过程
- 网络结构
文章主要介绍了DDPM扩散模型,包含了详细的数学推导,可能公式有点多,但是只要能够耐心看完,相信会有一些收获的。好了下面进入正题。
扩散模型
扩散模型是一种新的生成模型,可以生成高分辨率、高质量的图像。目前像谷歌,OpenAI,Nvidia等大厂都在持续投入研究,并推出自家的扩散模型,包括谷歌的Imagen、OpenAI的DALLE-2等,还有像近期大热的Midjourney和StableDiffusion,背后的原理均是基于扩散模型。但是扩散模型背后的原理到底是什么呢?今天笔者将聚焦于Denoising Diffusion Probabilistic Models (DDPM)这篇文章,带大家一探扩散模型的原理。
扩散过程
扩散过程主要分为两个阶段,前向过程和反向过程。当给定一张图像 x 0 x_0 x0时,前向过程就是经过 T T T步,给输入图像 x 0 x_0 x0逐步加上高斯噪声,前向过程被用来生成训练过程中的目标数据;反向过程则与前向过程相反,是逐步去掉添加到 x 0 x_0 x0上的噪声,最后生成一张无噪声的图像。在实际操作中,我们通过一个神经网络(unet)来预测噪声。首先在训练阶段,通过前向过程我们知道了添加到图像上的噪声 s s s(因为 s s s是我们生成的),此噪声 s s s即作为unet的目标输出,输入则为在 x 0 x_0 x0上添加噪声后的图像 x s x_s xs,通过( x s x_s xs, s s s)数据对,我们可以训练一个具备预测噪声能力的unet,该unet具备能力:当输入含噪图像时,可以预测出该含噪图像上添加的噪声 s s s,这样就可以计算出不含噪的图像。当然这里只介绍了一步,实际上反向过程是反复执行上面预测噪声,去掉噪声的多步去噪的过程。
前向过程
扩散模型的前向过程其实就是一个马尔科夫链。马尔科夫链到底是什么,这里我们不必深究,只需要知道它有一个特性就是链上新产生的一个数只依赖于这个新产生数的前一个数。前向过程的理解可以结合下图: q ( x t ∣ x t − 1 ) = N ( x t ; μ t = 1 − β t x t − 1 , Σ t = β t I ) \begin{equation} q(x_t|x_{t-1})=\mathcal N(x_t;\mu_t=\sqrt{1-\beta_t}x_{t-1},\Sigma_t=\beta_t\bm{I}) \end{equation} q(xt∣xt−1)=N(xt;μt=1−βtxt−1,Σt=βtI)

x 0 x_0 x0是一张干净的没有噪声的图像,采样自真实的数据分布 q ( x ) ( x 0 ∼ q ( x ) ) q(x)(x_0\sim q(x)) q(x)(x0∼q(x)),在马尔科夫链的每一步我们将方差为 β t \beta_t βt的高斯噪声添加到 x t − 1 x_{t-1} xt−1上,得到了一个新的含噪图像 x t x_t xt,其分布满足 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)。最终经过 T T T步后,得到了一个纯噪声图像 x T x_T xT。公式(1)中, I \bm I I是一个单位矩阵。我们注意到, q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)是一个由均值 μ t \mu_t μt和方差 Σ t \Sigma_t Σt定义的正太分布。
由 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)可以推导出
q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) \begin{equation} q(x_{1:T}|x_0)=\textstyle\prod_{t=1}^{T}q(x_t|x_{t-1}) \end{equation} q(x1:T∣x0)=∏t=1Tq(xt∣xt−1)
上式中的 t t t表示时间戳, q ( x 1 : T ∣ x 0 ) q(x_{1:T}|x_0) q(x1:T∣x0)表示从1到 T T T,共应用 T T T次 q q q函数。那么;例如当 t = 500 < T t=500
重参数技巧就是将相邻的两个变量建模成一个线性关系:
x t = 1 − β t x t − 1 + β t ϵ t − 1 , 其中 ϵ t − 1 ∼ N ( 0 , I ) \begin{equation} x_t=\sqrt{1-\beta_t}x_{t-1}+\sqrt{\beta_t}\epsilon_{t-1}, 其中\epsilon_{t-1}\sim\mathcal N(0,\bm I) \end{equation} xt=1−βtxt−1+βtϵt−1,其中ϵt−1∼N(0,I)
这里我们设 α t = 1 − β t \alpha_t=1-\beta_t αt=1−βt,那么(3)式可写为:
x t = α t x t − 1 + 1 − α t ϵ t − 1 = α t ( α t − 1 x t − 2 + 1 − α t − 1 ϵ t − 2 ) + 1 − α t ϵ t − 1 = α t α t − 1 x t − 2 + α t ( 1 − α t − 1 ) ϵ t − 2 + 1 − α t ϵ t − 1 \begin{equation} \begin{split} x_t&=\sqrt{\alpha_t}x_{t-1}+\sqrt{1-\alpha_t}\epsilon_{t-1}\\ &=\sqrt{\alpha_t}(\sqrt{\alpha_{t-1}}x_{t-2}+\sqrt{1-\alpha_{t-1}}\epsilon_{t-2})+\sqrt{1-\alpha_t}\epsilon_{t-1}\\ &=\sqrt{\alpha_t\alpha_{t-1}}x_{t-2}+\sqrt{\alpha_t(1-\alpha_{t-1})}\epsilon_{t-2}+\sqrt{1-\alpha_t}\epsilon_{t-1} \end{split} \end{equation} xt=αtxt−1+1−αtϵt−1=αt(αt−1xt−2+1−αt−1ϵt−2)+1−αtϵt−1=αtαt−1xt−2+αt(1−αt−1)ϵt−2+1−αtϵt−1
由于多个高斯分布相加,结果还是高斯分布,所以(4)式的后两项可以进行合并,合并过程如下:
N ( 0 , σ 1 2 I ) + N ( 0 , σ 2 2 I ) ∼ N ( 0 , ( σ 1 2 + σ 2 2 ) I ) 1 − α t ϵ t − 1 ∼ N ( 0 , ( 1 − α t ) I ) α t ( 1 − α t − 1 ) ϵ t − 2 ∼ N ( 0 , α t ( 1 − α t − 1 ) I ) α t ( 1 − α t − 1 ) ϵ t − 2 + 1 − α t ϵ t − 1 ∼ N ( 0 , [ α t ( 1 − α t − 1 ) + ( 1 − α t ) ] I ) = N ( 0 , ( 1 − α t α t − 1 ) I ) \begin{align*} \mathcal N(0,\sigma_1^2\bm{I})+\mathcal N(0,\sigma_2^2\bm{I})&\sim\mathcal N(0,(\sigma_1^2+\sigma_2^2)\bm{I}) \\ \sqrt{1-\alpha_t}\epsilon_{t-1}&\sim\mathcal{N}(0,(1-\alpha_t)\bm{I})\\ \sqrt{\alpha_t(1-\alpha_{t-1})}\epsilon_{t-2}&\sim\mathcal{N}(0,\alpha_t(1-\alpha_{t-1})\bm{I})\\ \sqrt{\alpha_t(1-\alpha_{t-1})}\epsilon_{t-2}+\sqrt{1-\alpha_t}\epsilon_{t-1}&\sim\mathcal{N}(0,[\alpha_t(1-\alpha_{t-1})+(1-\alpha_t)]\bm{I})=\mathcal{N}(0,(1-\alpha_t\alpha_{t-1})\bm{I}) \end{align*} N(0,σ12I)+N(0,σ22I)1−αtϵt−1αt(1−αt−1)ϵt−2αt(1−αt−1)ϵt−2+1−αtϵt−1∼N(0,(σ12+σ22)I)∼N(0,(1−αt)I)∼N(0,αt(1−αt−1)I)∼N(0,[αt(1−αt−1)+(1−αt)]I)=N(0,(1−αtαt−1)I)
那么经过合并后(4)式变为:
x t = α t α t − 1 x t − 2 + 1 − α t α t − 1 ϵ ‾ t − 2 , 其中 ϵ ‾ t − 2 ∼ N ( 0 , I ) \begin{equation} x_t=\sqrt{\alpha_t\alpha_{t-1}}x_{t-2}+\sqrt{1-\alpha_t\alpha_{t-1}}{\overline \epsilon}_{t-2},其中 \overline\epsilon_{t-2}\sim\mathcal N(0,\bm I) \end{equation} xt=αtαt−1xt−2+1−αtαt−1ϵt−2,其中ϵt−2∼N(0,I)
以此类推,再将 x t − 2 = α t − 2 x t − 3 + 1 − α t − 2 ϵ t − 3 x_{t-2}=\sqrt{\alpha_{t-2}}x_{t-3}+\sqrt{1-\alpha_{t-2}}\epsilon_{t-3} xt−2=αt−2xt−3+1−αt−2ϵt−3继续带入,这样不断代入,最终我们可以得到
x t = α t α t − 1 . . . α 1 x 0 + 1 − α t α t − 1 . . . α 1 ϵ \begin{equation} x_t=\sqrt{\alpha_t\alpha_{t-1}...\alpha_1}x_0+\sqrt{1-\alpha_t\alpha_{t-1}...\alpha_1}\epsilon \end{equation} xt=αtαt−1...α1x0+1−αtαt−1...α1ϵ
另 α ‾ t = α t α t − 1 . . . α 1 \overline \alpha_t=\alpha_t\alpha_{t-1}...\alpha_1 αt=αtαt−1...α1,那么式(6)就会变成
x t = α ‾ t x 0 + 1 − α ‾ t ϵ = N ( x t ; α ‾ t x 0 , ( 1 − α ‾ t ) I ) \begin{equation} \begin{aligned} x_t&=\sqrt{\overline \alpha_t}x_0+\sqrt{1-\overline \alpha_t}\epsilon \\ &=\mathcal N(x_t;\sqrt{\overline \alpha_t}x_0,(1-\overline \alpha_t)\bm I) \end{aligned} \end{equation} xt=αtx0+1−αtϵ=N(xt;αtx0,(1−αt)I)
其中 ϵ \epsilon ϵ依然为一标准高斯分布。可以知道,当 t t t趋于无穷时,由于 α t = 1 − β t < 1 \alpha_t=1-\beta_t<1 αt=1−βt<1,因此 α ‾ t \overline \alpha_t αt趋近于0,此时 x t x_t xt趋向于一个标准的高斯分布,也就是纯噪声了。这也就是如此构造式(3)的原因。
逆向过程
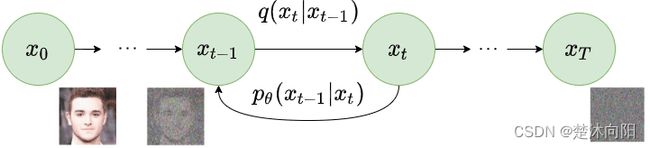
逆向过程就是逐步去噪的过程。在前向过程中我们要计算的是 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1),那么在逆向过程中就是要计算 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt)。因为我们无法直接得到 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt),但是加上 x 0 x_0 x0的后验分布 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)是可以计算的。根据贝叶斯公式
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) \begin{equation} q(x_{t-1}|x_t,x_0)=q(x_t|x_{t-1},x_0)\frac{q(x_{t-1}|x_0)}{q(x_t|x_0)} \end{equation} q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)
根据马尔科夫链特性,
q ( x t ∣ x t − 1 , x 0 ) = q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) (这里 x 0 是多余的) \begin{equation} q(x_t|x_{t-1},x_0)=q(x_t|x_{t-1})=\mathcal N(x_t;\sqrt{1-\beta_t}x_{t-1},\beta_t\bm I)(这里x_0是多余的) \end{equation} q(xt∣xt−1,x0)=q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)(这里x0是多余的)
由公式(7)可以直接计算出 q ( x t − 1 ∣ x 0 ) q(x_{t-1}|x_0) q(xt−1∣x0)和 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0),即
q ( x t − 1 ∣ x 0 ) = N ( x t − 1 ; α ‾ t − 1 x 0 , ( 1 − α ‾ t − 1 ) I ) q ( x t ∣ x 0 ) = N ( x t ; α ‾ t x 0 , ( 1 − α ‾ t ) I ) \begin{equation} \begin{aligned} q(x_{t-1}|x_0)&=\mathcal N(x_{t-1};\sqrt{\overline \alpha_{t-1}}x_0,(1-\overline \alpha_{t-1})\bm I)\\ q(x_t|x_0)&=\mathcal N(x_t;\sqrt{\overline \alpha_t}x_0,(1-\overline \alpha_t)\bm I) \end{aligned} \end{equation} q(xt−1∣x0)q(xt∣x0)=N(xt−1;αt−1x0,(1−αt−1)I)=N(xt;αtx0,(1−αt)I)
将公式(9),(10)代入公式(8)中,经过一系列推导(这里暂时省略),就可以得到 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)的均值和方差:
β ~ t = 1 − α ‾ t − 1 1 − α ‾ t β t μ ~ t ( x t , x 0 ) = α ‾ t − 1 β t 1 − α ‾ t x 0 + α t ( 1 − α ‾ t − 1 ) 1 − α ‾ t x t \begin{equation} \begin{aligned} \widetilde \beta_t&=\frac{1-\overline \alpha_{t-1}}{1-\overline \alpha_t}\beta_t \\ \widetilde \mu_t(x_t,x_0)&=\frac{\sqrt{\overline\alpha_{t-1}}\beta_t}{1-\overline\alpha_t}x_0+\frac{\sqrt{\alpha_t}(1-\overline\alpha_{t-1})}{1-\overline\alpha_t}x_t \end{aligned} \end{equation} β tμ t(xt,x0)=1−αt1−αt−1βt=1−αtαt−1βtx0+1−αtαt(1−αt−1)xt
根据前向过程的式(7),可以知道:
x 0 = 1 α ‾ t ( x t − 1 − α ‾ t ϵ ) \begin{equation} x_0=\frac{1}{\sqrt{\overline\alpha_t}}(x_t-\sqrt{1-\overline\alpha_t}\epsilon) \end{equation} x0=αt1(xt−1−αtϵ)
将式(12)和 β t = 1 − α t \beta_t=1-\alpha_t βt=1−αt代入式(11)中,那么
μ ~ t ( x t ) = α ‾ t − 1 β t 1 − α ‾ t 1 α ‾ t ( x t − 1 − α ‾ t ϵ ) + α t ( 1 − α ‾ t − 1 ) 1 − α ‾ t x t = α ‾ t − 1 β t 1 − α ‾ t 1 α ‾ t x t + α t ( 1 − α ‾ t − 1 ) 1 − α ‾ t x t − α ‾ t − 1 β t 1 − α ‾ t 1 − α ‾ t α ‾ t ϵ = β t 1 α t + α t − α t α ‾ t − 1 1 − α ‾ t x t − β t α t 1 − α ‾ t ϵ = β t + α t − α t α ‾ t − 1 α t ( 1 − α ‾ t ) x t − β t α t 1 − α ‾ t ϵ = 1 − α t + α t − α t α ‾ t − 1 α t ( 1 − α ‾ t ) x t − β t α t 1 − α ‾ t ϵ = 1 − α ‾ t α t ( 1 − α ‾ t ) x t − β t α t 1 − α ‾ t ϵ = 1 α t x t − β t α t 1 − α ‾ t ϵ = 1 α t ( x t − β t 1 − α ‾ t ϵ ) \begin{equation} \begin{aligned} \widetilde \mu_t(x_t)&=\frac{\sqrt{\overline\alpha_{t-1}}\beta_t}{1-\overline\alpha_t}\frac{1}{\sqrt{\overline\alpha_t}}(x_t-\sqrt{1-\overline\alpha_t}\epsilon)+\frac{\sqrt{\alpha_t}(1-\overline\alpha_{t-1})}{1-\overline\alpha_t}x_t\\ &=\frac{\sqrt{\overline\alpha_{t-1}}\beta_t}{1-\overline\alpha_t}\frac{1}{\sqrt{\overline\alpha_t}}x_t+\frac{\sqrt{\alpha_t}(1-\overline\alpha_{t-1})}{1-\overline\alpha_t}x_t-\frac{\sqrt{\overline\alpha_{t-1}}\beta_t}{1-\overline\alpha_t}\frac{\sqrt{1-\overline\alpha_t}}{\sqrt{\overline\alpha_t}}\epsilon\\ &=\frac{\beta_t\frac{1}{\sqrt\alpha_t}+\sqrt{\alpha_t}-\sqrt{\alpha_t}\overline\alpha_{t-1}}{1-\overline\alpha_t}x_t-\frac{\beta_t}{\sqrt{\alpha_t}\sqrt{1-\overline\alpha_t}}\epsilon\\ &=\frac{\beta_t+\alpha_t-\alpha_t\overline\alpha_{t-1}}{\sqrt{\alpha_t}(1-\overline\alpha_t)}x_t-\frac{\beta_t}{\sqrt{\alpha_t}\sqrt{1-\overline\alpha_t}}\epsilon\\ &=\frac{1-\alpha_t+\alpha_t-\alpha_t\overline\alpha_{t-1}}{\sqrt{\alpha_t}(1-\overline\alpha_t)}x_t-\frac{\beta_t}{\sqrt{\alpha_t}\sqrt{1-\overline\alpha_t}}\epsilon\\ &=\frac{1-\overline\alpha_t}{\sqrt{\alpha_t}(1-\overline\alpha_t)}x_t-\frac{\beta_t}{\sqrt{\alpha_t}\sqrt{1-\overline\alpha_t}}\epsilon\\ &=\frac{1}{\sqrt{\alpha_t}}x_t-\frac{\beta_t}{\sqrt{\alpha_t}\sqrt{1-\overline\alpha_t}}\epsilon\\ &=\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{\beta_t}{\sqrt{1-\overline\alpha_t}}\epsilon) \end{aligned} \end{equation} μ t(xt)=1−αtαt−1βtαt1(xt−1−αtϵ)+1−αtαt(1−αt−1)xt=1−αtαt−1βtαt1xt+1−αtαt(1−αt−1)xt−1−αtαt−1βtαt1−αtϵ=1−αtβtαt1+αt−αtαt−1xt−αt1−αtβtϵ=αt(1−αt)βt+αt−αtαt−1xt−αt1−αtβtϵ=αt(1−αt)1−αt+αt−αtαt−1xt−αt1−αtβtϵ=αt(1−αt)1−αtxt−αt1−αtβtϵ=αt1xt−αt1−αtβtϵ=αt1(xt−1−αtβtϵ)
这个时候,我们就可以知道,在每一个时间戳都会有一个均值 μ ~ t ( x t ) \widetilde \mu_t(x_t) μ t(xt)依赖于 x t x_t xt和 ϵ \epsilon ϵ,这里 x t x_t xt是网络的输入,所以只要能够知道 ϵ \epsilon ϵ,那么我们就能得到 μ ~ t ( x t , x 0 ) \widetilde \mu_t(x_t,x_0) μ t(xt,x0),在DDPM论文中,作者为了简化优化过程,保持方差固定,仅仅让网络学习均值,在有了均值 μ ~ t ( x t , x 0 ) \widetilde \mu_t(x_t,x_0) μ t(xt,x0)和方差 β ~ t \widetilde\beta_t β t后,我们就可以得到 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0),那么一步逆向过程就完成了。因此损失函数为
L t = E x 0 , t , ϵ [ 1 2 ∣ ∣ Σ θ ( x t , t ) ∣ ∣ 2 2 ∣ ∣ μ ~ t − μ θ ( x t , t ) ∣ ∣ 2 2 ] = E x 0 , t , ϵ [ β t 2 2 α t ( 1 − α ‾ t ) ∣ ∣ Σ θ ∣ ∣ 2 2 ∣ ∣ ϵ t − ϵ θ ( α ‾ t x 0 + 1 − α ‾ t ϵ , t ) ∣ ∣ 2 ] \begin{equation} \begin{aligned} \bm L_t&=\mathbb E_{x_0,t,\epsilon}\left[\frac{1}{2||\Sigma_{\theta}(x_t,t)||_2^2}||\widetilde\mu_t-\mu_\theta(x_t,t)||_2^2\right] \\ &=\mathbb E_{x_0,t,\epsilon}\left[\frac{\beta_t^2}{2\alpha_t(1-\overline\alpha_t)||\Sigma_\theta||_2^2}||\epsilon_t-\epsilon_\theta(\sqrt{\overline\alpha_t}x_0+\sqrt{1-\overline\alpha_t}\epsilon,t)||^2\right] \end{aligned} \end{equation} Lt=Ex0,t,ϵ[2∣∣Σθ(xt,t)∣∣221∣∣μ t−μθ(xt,t)∣∣22]=Ex0,t,ϵ[2αt(1−αt)∣∣Σθ∣∣22βt2∣∣ϵt−ϵθ(αtx0+1−αtϵ,t)∣∣2]
式(14)等效于网络直接预测噪声 ϵ \epsilon ϵ,我们用神经网络 ϵ θ ( x t , t ) \epsilon_\theta(x_t,t) ϵθ(xt,t)来近似噪声 ϵ \epsilon ϵ,因此简化后的损失函数为:
L t s i m p l e = E x 0 , t , ϵ [ ∣ ∣ ϵ − ϵ θ ( α ‾ t x 0 + 1 − α ‾ t ϵ , t ) ∣ ∣ 2 ] \begin{equation} \bm L_t^{simple}=\mathbb E_{x_0,t,\epsilon}\left[||\epsilon-\epsilon_{\theta}(\sqrt{\overline\alpha_t}x_0+\sqrt{1-\overline\alpha_t}\epsilon,t)||^2\right] \end{equation} Ltsimple=Ex0,t,ϵ[∣∣ϵ−ϵθ(αtx0+1−αtϵ,t)∣∣2]
下图是DDPM中训练和采样的整体过程

在训练过程中,DDPM的过程为:
1、取一张无噪声图像 x 0 x_0 x0,在 0 − T 0-T 0−T范围内随机选择一个采样时间戳 t t t
2、采样一个标准高斯分布 ϵ \epsilon ϵ作为噪声,将噪声 ϵ \epsilon ϵ加到时间戳 t t t上,得到 x t x_t xt
3、2中采样的噪声为网络的目标输出, x t x_t xt为网络输入,计算网络预测噪声和目标噪声之间的loss和梯度
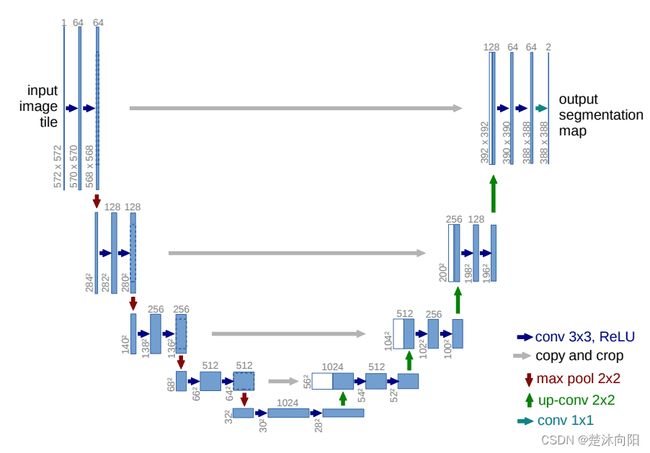
网络结构
前面我们说过,用来预测噪声的是一个神经网络(unet),unet的特点是输出与输入具有相同的形状,unet是一个encoder-decoder结构,encoder和decoder中间用skip connection相连。结构如下图: