勘探开发人工智能技术:机器学习(6)
0 提纲
7.1 循环神经网络RNN
7.2 LSTM
7.3 Transformer
7.4 U-Net
1 循环神经网络RNN
把上一时刻的输出作为下一时刻的输入之一.
1.1 全连接神经网络的缺点
现在的任务是要利用如下语料来给apple打标签:
- 第一句话:I like eating apple!(我喜欢吃苹果!)
- 第二句话:The Apple is a great company!(苹果真是一家很棒的公司!)
第一个apple是一种水果,第二个apple是苹果公司。
全连接神经网络没有利用上下文来训练模型,模型在训练的过程中,预测的准确程度,取决于训练集中哪个标签多一些,如果水果多,就打上水果的标签,如果苹果公司多,就打上苹果公司;显然这样的模型不能对未知样本进行准确的预测。
循环神经网络 (Recurrent Neural Network, RNN) 用于处理序列数据.
1.2 动机
序列数据中, 前后数据之间不是独立的, 而是会产生上下文影响. 如:
- 文本, 机器翻译一个句子的时候, 不是逐个单词的翻译 (你可以发现近 10 年机器翻译的质量大幅提升, 最近的 chatGPT 更是火得一蹋糊涂);
- 音频, 可以在微信中让机器把你讲的话转成文字;
- 投票, 虽然股价预测不靠谱, 但根据时序进行预测却是人们最喜欢干的事情。
1.3 RNN的结构
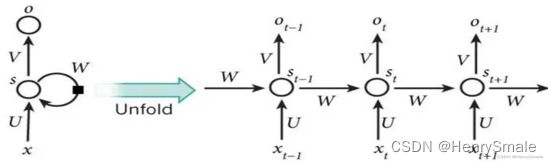
左图如果不考虑 W W W,就是一个全连接神经网络:
- 输入层:向量 x x x,假设维度为3;
- 隐藏层:向量 s s s,假设维度为4;
- 输出层:向量 o o o,假设维度为2;
- U U U:输入层到隐藏层的参数矩阵,维度为 3 × 4 3×4 3×4;
- V V V:隐藏层到输出层的参数矩阵,维度为 4 × 2 4×2 4×2。
左图如果考虑 W W W,可以展开为右图:
- x t − 1 x_{t−1} xt−1:表示 t − 1 t−1 t−1时刻的输入;
- x t x_t xt:表示 t t t时刻的输入;
- x t + 1 x_{t+1} xt+1:表示 t + 1 t+1 t+1时刻的输入;
- W W W:每个时间点的权重矩阵;
- o t o_t ot:表示 t t t时刻的输出;
- s t s_t st:表示 t t t时刻的隐藏层;
RNN 把前一时刻 (简便起见, 前一个单词我也称为前一时刻) 的输出, 当作本阶段输入的一部分. 这里 x t − 1 x_{t−1} xt−1为前一时刻的输入, 而 s t − 1 s_{t-1} st−1 为前一时刻的输出. 这样, 就把数据的前后联系体现出来了.
1.4 RNN的缺点
每一时刻的隐藏状态都不仅由该时刻的输入决定,还取决于上一时刻的隐藏层的值,如果一个句子很长,到句子末尾时,它将记不住这个句子的开头的内容详细内容。
2 长短期记忆网络LSTM
选择性的存储.
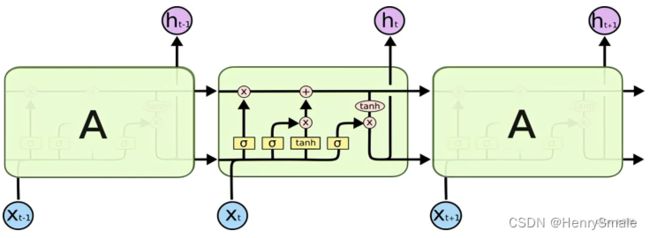
2.1 LSTM的原理
LSTM是高级的RNN,与RNN的主要区别在于:
- RNN每个时刻都会把隐藏层的值存下来,到下一时刻再拿出来使用,RNN没有挑选的能力;
- LSTM不一样,它有门控装置,会选择性的存储信息。既有记忆 (重要信息) 的功能, 也有遗忘 (不重要信息) 的功能.

LSTM多了三个门:
- 输入门:输入的信息经过输入门,输入门的开关决定这一时刻是否会将信息输入到Memory Cell;
- 输出门:每一时刻是否有信息从Memory Cell输出取决于这一道门;
- 遗忘门:每一时刻Memory Cell里的值都会经历一个是否被遗忘的过程.
2.2 讨论?
遗忘也是一种功能吗? 当然是了.
所谓好了伤疤忘了痛, 如果一个人不会遗忘, 很快就精神失常了.
详细分析见:
https://mp.weixin.qq.com/s?__biz=MzU0MDQ1NjAzNg==&mid=2247535325&idx=1&sn=7d805b06916a3da299e20c0445f59a07&chksm=fb3aefd6cc4d66c06b0f2d5779c83861474d2442f9b3387a4b87f45f3218efc92c3335602678&scene=27
3 变形金刚Transformer:注意力机制
定位到感兴趣的信息, 抑制无用信息 (怎么有点像 PCA).
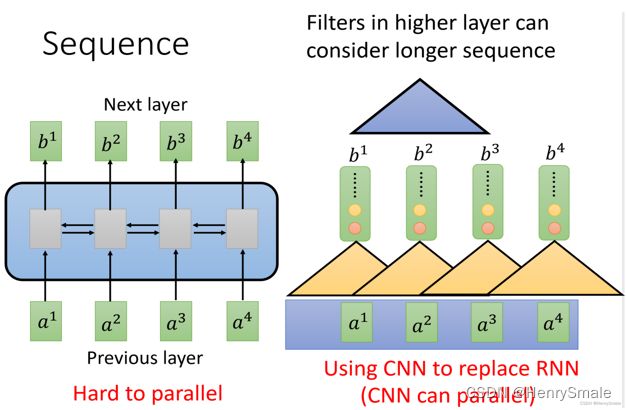
3.1 CNN及RNN的缺点
- RNN:很难实现并行(左图,计算 b 4 b^4 b4需要串行查询 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4);
- CNN:可以实现并行,需要堆叠多层的CNN才能学习到整个序列的特征(右图).
3.2 自注意力机制(self-attention)
采用自注意力机制层取代RNN来处理序列,同时实现序列的并行处理。
自注意力机制具体内容见https://blog.csdn.net/search_129_hr/article/details/129522922

3.3 注意力机制
数据有重要的数据和不重要的数据。在模型处理数据的过程中,如果只关注较为重要的数据部分,忽略不重要的部分,那训练的速度、模型的精度就会变得更好。
如果给你一张这个图,你眼睛的重点会聚焦在红色区域:
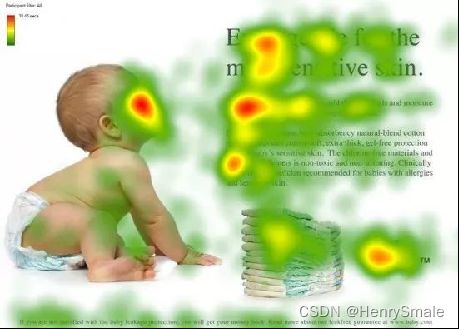
- 人看脸
- 文章看标题
- 段落看开头
在训练过程中,输入的权重也都是不同的,注意力机制就是学习到这些权重。
最开始attention机制在CV领域被提出来,后面广泛应用在NLP领域。
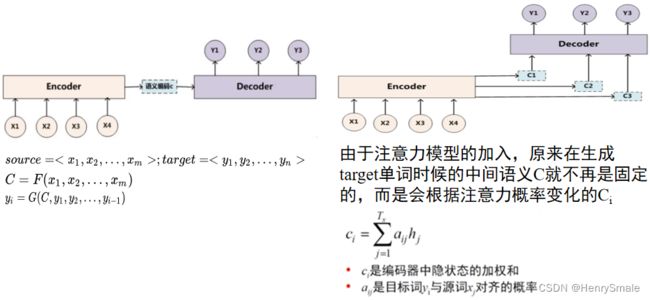
3.4 Tranformer的原理
Transformer 主要分为两部分:Encoder编码器 和 Decoder解码器
- Encoder:负责把输入(语言序列)隐射成隐藏层(图中第 2 步九宫格表示),即把自然语言序列映射为隐藏层的数学表达的过程;
- Decoder:把隐藏层映射为自然语言序列。
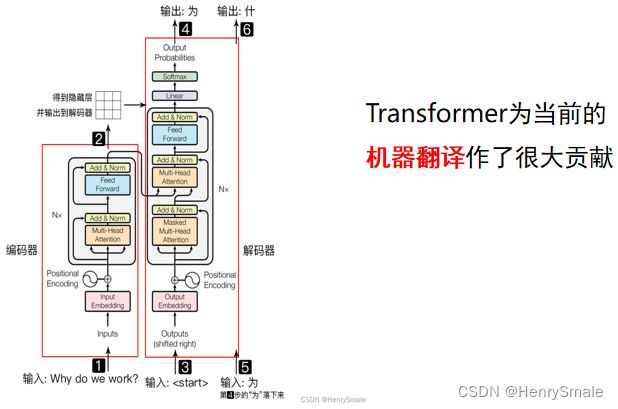
4 U-Net
先编码获得内部表示, 再解码获得目标数据 (怎么有点像矩阵分解).
4.1 U-Net核心思想
U-Net 集编码-解码于一体, 是一种常见的网络架构.
如图所示, U-Net 就是 U 形状的网络, 前半部分 (左边) 进行编码, 后半部分 (右边) 进行解码.
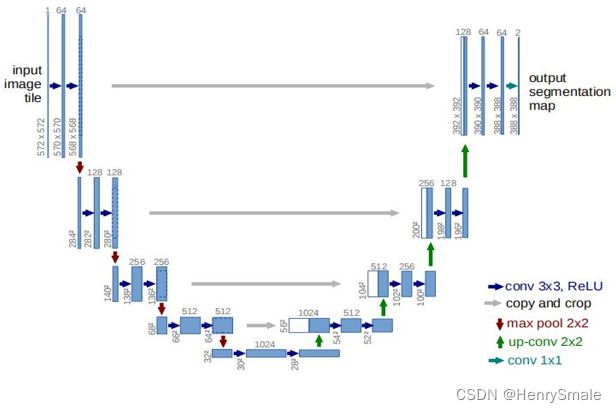
编码部分, 将一个图像经过特征提取, 变成一个小矩阵(28 × 28). 前面说过: 深度学习本质上只做一件事情, 就是特征提取.
解码部分, 将压缩表示解压, 又变回大矩阵,完成图像分割任务.
从思想上, 压缩与解压, 这与矩阵分解有几分类似, 都是把数据进行某种形式的压缩表示.
输入的是原始图像,通过网络结构后得到的是分割后的图像。
最特殊的部分是结构的后半部分,该网络结构没有全连接层,只采用了卷积层,每个标准的卷积层后面都紧跟着一个Relu激活函数层。
4.2 U-Net的应用
自编码器. 直接将输入数据作为标签, 看编码导致的损失 (更像矩阵分解了).
风格迁移:从一种风格转换为另一种风格. 如将自然照片转换成卡通风格, 将地震数据转换成速度模型 (2010年如果你这么做会被业内人士笑话的).
图像分割, 或提取图片的边缘. 嗯, 这个和转成卡通风格也差不多.
机器翻译. 把句子编码成机器内部的表示 (一种新的世界语言?), 然后转成其它语言的句子.
输入一个头, 输出多个头, 就可以做多任务. 如在速度模型反演的同时, 进行边缘提取, 这样导致反演的结果更丝滑.