Java爬虫技术—入门秘籍之HTTP协议和robtos协议(一)
文章目录:
- 入门秘籍—Http协议与robots协议
- 内功修炼—深入理解网络爬虫概念,作用,原理和爬取方式及流程
- 山中奇遇—得授页面解析技术之Xpath
- 入驻兵器阁—获取爬虫神器之Jsoup
- 入驻兵器阁—获取爬虫神器之HttpClient
- 初出江湖路遇波折—常见反爬虫策略
- 伪装身份破入山门—反爬虫对策之模拟身份代理IP
- 修炼升级—htmlutil工具抓取ajax动态页面
- 升级进阶—Selenium自动化工具
- 化繁为简唯快不破—webmagic框架快速开发爬虫应用
引子
随着大数据技术兴起,互联网江湖再现波澜。数据采集这门一本万利的生意,一直被python这个门派所独揽,独步天下,无人能敌。然,天下熙熙,皆为利来;天下攘攘,皆为利往,曾经的web技术领域的江湖大佬,java岛亦有不甘,欲再现江湖,与之平分天下……
第一章 入门秘籍之Http协议和robots协议
爬虫元年,java岛欲重开山门,广招java弟子。
时年六月三十日,残阳如血。
小奇手握毕业证书,带着毕业聚餐之后的伤感和对未来之憧憬,意欲在互联网江湖中闯出一番天下,雄心勃勃果断上路,踏上了去往java岛修炼的征程。经过重重考验,过五关斩六将,终于如愿以偿的成为了java岛爬虫谷的入室弟子。
办完手续,了解了注意事项,领了服装,工具设备和两本小册子,小奇就一头扎进宿舍开始迫不及待的研究入门秘籍了。
首先是一本《HTTP协议》,HyperText Transfer Protocol也就是超文本传输协议。是因特网上应用最为广泛的一种网络传输协议,所有的WWW文件都必须遵守这个标准。HTTP是一个基于TCP/IP通信协议来传递数据(HTML文件, 图片文件, 查询结果等)。
看完概念,小奇若有所思,继续往下学习Http协议的工作原理:HTTP协议工作于客户端-服务端架构上,浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求,服务器端接到请求之后把相应的资源信息响应给客户端,从而完成一个请求响应的过程。
如图所示:

同时小奇也注意到,Http协议有以下特点:
1.HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
2.HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
3.HTTP是无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
了解了工作原理和特点之后,小奇又开始进行了深入的思考。在数据传输过程中它的数据报文格式是怎样的呢?秘籍中也给出了解释:
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:
请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。
如图所示:

请求行以一个请求符号开头,以空格分开,后面跟着请求的URI和协议的版本,格式如下:
Method Request-URI HTTP-Version CRLF
实例:GET /login.jsp HTTP/1.1
其中GET是本次请求所采用的请求方法,HTTP请求方法有七种:

请求头部信息:
请求头部由key/value键值对组成,每行一对。请求头部通知服务器有关于客户端请求的信息,典型的请求头有:
Accept: text/html,image/*
Accept-Charset: UTF-8
Accept-Encoding: gzip,compress
Accept-Language: en-us,zh-cn
Host: www.zhidisoft.com:80
If-Modified-Since: Tue, 11 Jul 2017 18:23:51 GMT
Referer: http://www.zhidisoft.com/index.jsp
User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0)
Connection: close/Keep-Alive
Date: Tue, 11 Jul 2017 18:23:51 GMT
HTTP响应(response):
服务器端对一个HTTP请求处理完毕之后,服务器会返回给客户端一些信息,这就是HTTP响应。一个HTTP响应代表服务器向客户端回送的数据,它也包括三个部分:一个状态行、若干消息头、以及实体内容 。其中的一些消息头和实体内容都是可选的,消息头和实体内容间要用空行隔开:

HTTP状态行格式如下:
HTTP-Version Status-Code Reason-Phrase CRLF
HTTP-Versio:表示服务器HTTP协议的版本
Status-Code:表示服务器发回的响应状态代码
Reason-Phrase:表示状态代码的文本描述
状态码用于表示服务器对请求的处理结果。响应状态码分为5类,如下所示:

消息报头:
与请求报头类似,不同在于请求报头附带的是关于请求的相关信息,而消息报头则附带的是服务端应答的相关信息。
常见的响应头:
Content-Encoding: gzip
Content-Type: text/html; charset=UTF-8
Last-Modified: Tue, 11 Jul 2017 18:23:51 GMT
Expires: -1
Cache-Control: no-cache
Pragma: no-cache
Connection: close/Keep-Alive
Date: Tue, 11 Jul 2017 18:23:51 GMT
通过以上内容的学习,小奇略有所得。实践才是检验真理的唯一标准,于是迫不及待的打开电脑连接上互联网,在浏览器中输入网址,通过HTTP协议访问互联网。看到响应的页面信息后,按F12键打开开发者工具,再刷新页面,点击一个请求连接,可以查看到部分该请求响应的报文信息:
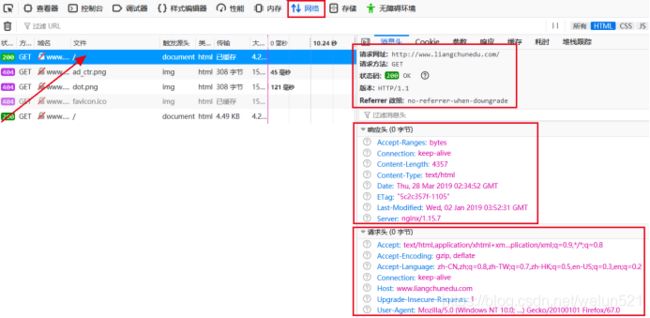
通过实践小奇对HTTP协议的请求响应模式又有了新的认识和感悟,果然是背靠大树好乘凉,以前虽然也是在使用互联网,但知其然而不知其所以然,现在终于搞明白怎么回事了。
接着又打开了另外一本小册子《robots协议》,Robots协议全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,也称为爬虫协议、机器人协议等。Robots协议可以屏蔽一些网站中比较大的文件,如:图片,音乐,视频等,节省服务器带宽;可以屏蔽站点的一些死链接。方便搜索引擎抓取网站内容;设置网站地图连接,方便引导蜘蛛爬取页面。
Robots协议的语法格式:
Disallow: /表示禁止访问,Allow: /表示允许访问。
在写robots.txt时需特别注意的是,/前面有一个英文状态下的空格(必须是英文状态下的空格)。
禁止搜索引擎访问网站中的某几个文件夹,以a、b、c为例,写法分别如下:
Disallow: /a/
Disallow: /b/
Disallow: /c/
禁止搜索引擎访问文件夹中的某一类文件,以a文件夹中的js文件为例,写法如下:
Disallow: /a/*.js
只允许某个搜索引擎访问,以Baiduspider为例,写法如下:
User-agent: Baiduspider
Disallow:
禁止访问网站中的动态页面
User-agent: *
Disallow: /*?*
只允许搜索引擎访问某类文件,以htm为例,写法如下:
User-agent: *
Allow: .htm$
Disallow: /
禁止某个搜索引擎抓取网站上的所有图片,以Baiduspider为例,写法如下:
User-agent: Baiduspider
Disallow: .jpg$
Disallow: .jpeg$
Disallow: .gif$
Disallow: .png$
Disallow: .bmp$
robots.txt文件存放在网站根目录下,并且文件名所有字母都必须小写。
看完robots协议的介绍之后,小奇发现这就是一个规范说明而已,不禁有些感叹,“就是一个防君子不防小人的行业规范嘛”。
“嗯,robots就是一个君子协定”,突然后面有人应声道。
小奇被这突然的声音吓了一跳,由于太过专注,没有发现后面有人在看自己。高高的个子,戴个黑框眼镜,一头短发,酷酷的感觉。小奇这才突然想起来,办理手续的时候,告诉过自己,是同宿舍的小酷师兄,于是连忙问好:“小酷师兄好!”
“你是新来的小奇师弟吧”。接着说道:“robots协议虽然平时与我们影响不大,但真正做项目的时候还是需要注意的。听说过2012年的时候的3百大战吗?那真是一场血雨腥风的大战,百度指责360不顾robots协议,非法抓取百度的信息,要求赔偿1亿元损失,360指责百度行业垄断,相互掐架,后来sogo,腾讯等公司相序加入战团,一片混乱。最后,工信部调解,双方才停止相互攻击。直到2013年4月27日,百度起诉360不正当竞争案今日宣判,北京一中院依据robots协议等相关规范判决360败诉,要求360停止不正当竞争行为、连续15日在首页道歉声明,赔偿损失45万元”,说起这件事小酷师兄满脸的悻悻之色。
小奇听完也是充满了震惊感叹道:“robots协议还是蛮重要的”。
“嗯,平时我们自己练练手之类的可以不用在意,在不影响宗门利益的情况下,也可以自由发挥的,以后你就会明白的。”,小酷师兄总结道。
“对了,明天早起别忘了去问道阁参加入门弟子的培训”,说完就呼呼睡去。
更多视频java爬虫视频课程:https://edu.csdn.net/course/detail/20623/258631