ES7.10集群搭建及EFK搭建教程
本文主要介绍 Elasticsearch 集群的搭建。通过在一台服务器上创建 3 个 ES 实例来创建一个ES 集群。
以下内容参考详尽的 Elasticsearch7.X 安装及集群搭建教程,
ES7集群安装、配置、卸载,进行再次整理。
简介
官方的Elasticsearch Reference 提供了不同版本的文档连接。

Elasticsearch 7.x 包里自包含了 OpenJDK 的包。如果你想要使用你自己配置好的 Java 版本,需要设置 JAVA_HOME 环境变量 —— 参考

官方文档 Set up Elasticsearch有各个 OS 的安装指导,页面 Installing Elasticsearch 中提供了多种安装包对应的指导链接!


本文选择绿色安装包的的方式(tar.gz)安装。
Elasticsearch7.10 安装及集群搭建教程
- 简介
- 一、安装ES
-
- 1、准备工作
-
- 环境准备
- 创建启动es的账号
- 2、安装单机版测试
-
- 单机简单安装
- 运行Elasticsearch
- 检查运行状态
- 设置es密码
-
- 重置密码
- 修改密码
- 3、安装ES集群
- 4、优化配置
-
- 1、内存优化
- 2、修改vi /etc/security/limits.conf
- 3、修改/etc/security/limits.d/90-nproc.conf
- 5、ES 配置相关
-
- JVM 配置
- elasticsearch.yml 配置
-
- 创建集群
- 集群配置预览
- 重点参数释义
- 6、启动ES集群
- 7、集群验证
- 二、ES可视化插件ES-HEAD安装
-
- 修改设置系统参数
- node环境配置
- 安装ES-HEAD
- 安装grunt
- 三、ik分词器安装
- 四、部署 kibana
- 五、部署 filebeat
-
-
- 带密码采集一台服务器中的不同日志
- kibana页面配置
-
一、安装ES
1、准备工作
环境准备
centos8
es7.10.0
ES安装包下载地址:
官方 官网的下载速度龟速
华为镜像站下载速度不错,推荐
jdk11(本次安装使用es自带jdk,不再单独下载jdk及Java_home环境配置)
创建启动es的账号
具体如何在Linux上创建新用户,可参考linux创建新用户并将为其赋予权限
具体操作:
adduser es
passwd es
2、安装单机版测试
单机简单安装
#解压
tar -xvf elasticsearch-7.10.0-linux-x86_64.tar.gz -C /usr/local
解压后的目录如下:
├── bin # 二进制脚本存放目录,包括 elasticsearch 来指定运行一个 node,包括 elasticsearch-plugin 来安装 plugins
├── config # 包含了 elasticsearch.yml 配置文件
├── data # 节点上分配的每个 index/分片 的数据文件
├── jdk # 内置的 JDK
├── lib
├── LICENSE.txt
├── logs
├── modules
├── NOTICE.txt
├── plugins # 插键文件存放的位置
└── README.textile
#拷贝一份作为测试使用
cp /usr/local/elasticsearch-7.10.0 -R /usr/local/es-7.10.0-node01
#备份yml
cp /usr/local/elasticsearch-7.10.0/config/elasticsearch.yml /usr/local/elasticsearch-7.10.0/config/elasticsearch.yml.bak
#备份环境配置
cp /usr/local/elasticsearch-7.10.0/bin/elasticsearch-env /usr/local/elasticsearch-7.10.0/bin/elasticsearch-env-bak
#指定es使用自带的jdk
vi /usr/local/elasticsearch-7.10.0/bin/elasticsearch-env
找到Java相关配置,将相关内容注释
# now set the path to java
#if [ ! -z "$JAVA_HOME" ]; then
# JAVA="$JAVA_HOME/bin/java"
# JAVA_TYPE="JAVA_HOME"
#else
# if [ "$(uname -s)" = "Darwin" ]; then
# macOS has a different structure
# JAVA="$ES_HOME/jdk.app/Contents/Home/bin/java"
# else
JAVA="$ES_HOME/jdk/bin/java"
# fi
JAVA_TYPE="bundled jdk"
#fi
运行Elasticsearch
#为es账号设置权限
#文件夹归属组
chown -R [用户]:目录
chown -R es: /usr/local/es-*
#调试启动
su es - l -c "/usr/local/es-7.10.0-node01/bin/elasticsearch"
#后台启动
su es - l -c "/usr/local/es-7.10.0-node01/bin/elasticsearch -d"
检查运行状态
命令行模式
curl -X GET "localhost:9200/?pretty"
或者在浏览器中访问 ip:9200 都可以
注意关闭防火墙
systemctl status firewalld
systemctl disable --now firewalld
[root@siyuan ~]# curl -X GET "localhost:9200/?pretty"
{
"name" : "siyuan",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "iQk5Vl5SS86LpSbeHLKyuw",
"version" : {
"number" : "7.10.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "51e9d6f22758d0374a0f3f5c6e8f3a7997850f96",
"build_date" : "2020-11-09T21:30:33.964949Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
如果你是在远端服务器上部署的 ES,那么,此时在你本地的工作机上还无法调通 :9200,需要对 ES 进行相关配置才能访问。
解决办法:vim config/elasticsearch.yml
增加:network.host: 0.0.0.0
把注释放开改为:bootstrap.memory_lock: false
在其后添加: bootstrap.system_call_filter: false
修改
vi /etc/security/limits.conf
或
vim /etc/security/limits.d/90-nproc.conf
# 配置进程 和线程数
* soft nproc 131072
* hard nproc 131072
#配置 文件句柄数
* soft nofile 65536
* hard nofile 131072
#配置 内存锁定交换
* soft memlock unlimited
* hard memlock unlimited
再次重启会抛出以下错误:
java.lang.IllegalStateException: failed to obtain node locks, tried [[/usr/local/es-7.10.0-node01/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?

解决:删除/usr/local/es-7.10.0-node01/data的node文件【安装目录下的data下的node文件】
原因:可能node是原先es被占用,导致启动异常
重启报错:
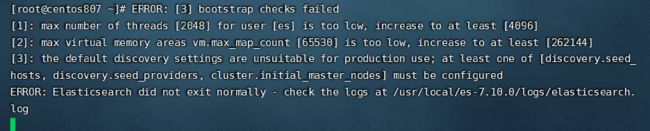
解决办法:
vi /etc/sysctl.conf
#禁用内存与磁盘交换
vm.swappiness=1
#设置虚拟机内存大小
vm.max_map_count=655360
保存后 执行 sysctl -p 使用配置生效
sysctl -p
我这里提供一份我自己的config/elasticsearch.yml配置可以参考以下
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
cluster.name: my-es
node.name: node01
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.type: single-node
xpack.security.enabled: false
discovery.seed_hosts: ["127.0.0.1:9300"]
设置es密码
参考elasticSearch 设置用户名密码 && 查询
- 进入ES的安装目录修改
elasticsearch.yml文件在最后添加
xpack.security.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
-
切换到es账号,重新启动ES:
/usr/local/es-7.10.0-node01/bin/elasticsearch -d(这一步非常重要,必须启动才能新增用户名和密码) -
以交互的方式设置用户名和密码:(记住你所设置的密码)
/usr/local/es-7.10.0-node01/bin/elasticsearch-setup-passwords interactive

-
到此已经完成ES及相关组件的加密了,后续访问和使用相关组件都需要验证用户名和密码了
访问:
curl --user elastic:123456 -XGET 'localhost:9200/_cat/health?v’
注意
Elasticsearch设置用户名密码之后,不能再直接使用Elasticsearch head 访问,可以在查询等API上加上用户等参数:
修改配置文件elasticsearch.yml, 并重启ES
config/elasticsearch.yml
增加如下内容:
http.cors.allow-headers: Authorization
注意: 重启ES后,若head显示 '集群健康值:未连接' 就换成下面的内容,再重启ES
重置密码
- 如果忘记之前elastic用户的密码,这个时候又要用到ES的加密功能,那需要重置ES的密码认证
修改
config/elasticsearch.yml;注释掉xpack.security.enabled: true这一行;
重启ES,
/usr/local/es-7.10.0-node01/bin/elasticsearch -d
查看下索引
curl -X GET "localhost:9200/_cat/indices",发现多了一个.security-7
删除掉.security-7索引:
curl -X DELETE "localhost:9200/.security-7"
修改密码
curl -XPOST -u elastic "localhost:9200/_security/user/elastic/_password" -H 'Content-Type: application/json' -d'{"password" : "test"}'
3、安装ES集群
由于实验机器有限,可以在同一台机器上模拟出 3 个节点,安装 ES 集群。
#将目录复制三份,作为三个节点,后面配置 ES 集群时,对应了三个 ES 实例
cp -R /usr/local/es-7.10.0-node01 /usr/local/es-7.10.0-node02
cp -R /usr/local/es-7.10.0-node01 /usr/local/es-7.10.0-node03
#创建数据存储目录
mkdir /var/lib/es-7.10.0-node01
mkdir /var/lib/es-7.10.0-node02
mkdir /var/lib/es-7.10.0-node03
#创建日志存储目录
mkdir /var/log/es-7.10.0-node01
mkdir /var/log/es-7.10.0-node02
mkdir /var/log/es-7.10.0-node03
#为es账号设置权限
#文件夹归属组
#chown -R [用户]:目录
chown -R es: /usr/local/es-*
chown -R es: /var/lib/es-*
chown -R es: /var/log/es-*
4、优化配置
1、内存优化
在/etc/sysctl.conf添加如下内容
vi /etc/sysctl.conf
fs.file-max=655360
vm.max_map_count=655360
#执行以下命令使其生效
sysctl -p
解释:
(1)vm.max_map_count=655360
系统最大打开文件描述符数
(2)vm.max_map_count=655360
限制一个进程拥有虚拟内存区域的大小
2、修改vi /etc/security/limits.conf
*代表所有用户
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
* soft memlock unlimited
* hard memlock unlimited
*
解释:
(nofile)最大开打开文件描述符
(nproc)最大用户进程数
(memlock)最大锁定内存地址空间
3、修改/etc/security/limits.d/90-nproc.conf
vi /etc/security/limits.d/90-nproc.conf
#将1024修改为65536
* soft nproc 65536
#查看
ulimit -a
5、ES 配置相关
官网关于配置的内容主要有两处:
- Configuraing Elasticsearch
- Important Elasticsearch configuration
Elasticsearch 主要有三个配置文件:
- jvm.options ES JVM 配置,more
- elasticsearch.yml ES 的配置,more
- log4j2.properties ES 日志配置,more
JVM 配置
JVM 参数设置可以通过 jvm.options文件(推荐方式)或者 ES_JAVA_OPTS环境变量来修改。
jvm.options位于
$ES_HOME/config/jvm.options当通过 tar or zip 包安装/etc/elasticsearch/jvm.options当通过 Debian or RPM packages
官网也介绍了如何设置堆大小。
默认情况,ES 告诉 JVM 使用一个最小和最大都为 1GB 的堆。但是到了生产环境,这个配置就比较重要了,确保 ES 有足够堆空间可用。
ES 使用 Xms(minimum heap size)和 Xmx(maxmimum heap size)设置堆大小。你应该将这两个值设为同样的大小。
Xms和 Xmx不能大于你物理机内存的 50%。
设置的示例:
vi /usr/local/es-7.10.0-node01/config/jvm.options
-Xms1g
-Xmx1g
elasticsearch.yml 配置
创建集群
实验机器有限,我们在同一台机器上创建三个 ES 实例来创建集群,分别明确指定了这些实例的 http.port和 transport.port。
discovery.seed_hosts明确指定实例的端口对测试集群的高可用性很关键。
如果后期有新节点加入,新节点的 discovery.seed_hosts 没必要包含所有的节点,只要它里面包含集群中已有的节点信息,新节点就能发现整个集群了。
集群配置预览
分别进入es-7.10.0-node01、es-7.10.0-node02和 es-7.10.0-node03文件夹,config/elasticsearch.yml 设置如下:
# es-7.10.0-node01
vi /usr/local/es-7.10.0-node01/config/elasticsearch.yml
cluster.name: my-es
node.name: node01
node.master: true
node.data: false
node.ingest: false
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
cluster.initial_master_nodes: ["node01"]
path.data: /var/lib/es-7.10.0-node01
path.logs: /var/log/es-7.10.0-node01
# 增加参数,使head插件可以跨域访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
# es-7.3.0-node-2
vi vi /usr/local/es-7.10.0-node01/config/elasticsearch.yml
cluster.name: my-es
node.name: node02
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9201
transport.port: 9301
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
path.data: /var/lib/es-7.10.0-node02
path.logs: /var/log/es-7.10.0-node02
# 增加参数,使head插件可以跨域访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
# es-7.10.0-node03
vi /usr/local/es-7.10.0-node03/config/elasticsearch.yml
cluster.name: my-es
node.name: node03
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9202
transport.port: 9302
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
path.data: /var/lib/es-7.10.0-node03
path.logs: /var/log/es-7.10.0-node03
# 增加参数,使head插件可以跨域访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
重点参数释义
(1)cluster.name
集群名字,三台集群的集群名字都必须一致
(2)node.name
节点名字,三台ES节点字都必须不一样
(3)node.master
该节点是否有资格选举为master,只要配了node master为true的ES服务器数正在运行的数量不少于master_node的配置数,则整个集群继续可用。master服务器主要管理集群状态,负责元数据处理,比如索引增加删除分片分配等,数据存储和查询都不会走主节点,压力较小,jvm内存可分配较低一点
(4)node.data
存储索引数据,三台都设为true即可
(5)network.host
network.host:设置访问的地址。默认仅绑定在回环地址 127.0.0.1和 [::1]。如果需要从其他服务器上访问以及多态机器搭建集群,我们需要设定 ES 运行绑定的 Host,节点需要绑定非回环的地址。建议设置为主机的公网 IP 或0.0.0.0:
network.host: 0.0.0.0
更多的网络设置可以阅读 Network Settings
(6)http.port
http.port 默认端口是 9200 :
http.port: 9200
注意:这是指 http 端口,如果采用 REST API 对接 ES,那么就是采用的 http 协议
(7)transport.port
REST 客户端通过 HTTP 将请求发送到您的 Elasticsearch 集群,但是接收到客户端请求的节点不能总是单独处理它,通常必须将其传递给其他节点以进行进一步处理。它使用传输网络层(transport networking layer)执行此操作。传输层用于集群中节点之间的所有内部通信,与远程集群节点的所有通信,以及 Elasticsearch Java API 中的 TransportClient。
transport.port 绑定端口范围。默认为 9300-9400
transport.port: 9300
因为要在一台机器上创建是三个 ES 实例,这里明确指定每个实例的端口。
(8)discovery.seed_hosts
discovery.seed_hosts:发现设置。有两种重要的发现和集群形成配置,以便集群中的节点能够彼此发现并且选择一个主节点。
discovery.seed_hosts是组件集群时比较重要的配置,用于启动当前节点时,发现其他节点的初始列表。
开箱即用,无需任何网络配置, ES 将绑定到可用的环回地址,并将扫描本地端口 9300 - 9305,以尝试连接到同一服务器上运行的其他节点。 这无需任何配置即可提供自动群集的体验。
如果要与其他主机上的节点组成集群,则必须设置 discovery.seed_hosts,用来提供集群中的其他主机列表(它们是符合主机资格要求的master-eligible并且可能处于活动状态的且可达的,以便寻址发现过程)。此设置应该是群集中所有符合主机资格的节点的地址的列表。 每个地址可以是 IP 地址,也可以是通过 DNS 解析为一个或多个 IP 地址的主机名(hostname)。
当一个已经加入过集群的节点重启时,如果他无法与之前集群中的节点通信,很可能就会报这个错误 master not discovered or elected yet, an election requires at least 2 nodes with ids from。
因此,我在一台服务器上模拟三个 ES 实例时,这个配置我明确指定了端口号。
配置集群的主机地址,配置之后集群的主机之间可以自动发现(可以带上端口,例如 127.0.0.1:9300):
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301"]
the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
必须至少配置[discovery.seed_hosts,discovery.seed_providers,cluster.initial_master_nodes]中的一个。
(9)cluster.initial_master_nodes
cluster.initial_master_nodes:初始的候选 master 节点列表。初始主节点应通过其node.name标识,默认为其主机名。确保 cluster.initial_master_nodes中的值与 node.name完全匹配。
首次启动全新的 ES 集群时,会出现一个集群引导/集群选举/cluster bootstrapping步骤,该步骤确定了在第一次选举中的符合主节点资格的节点集合。在开发模式下,如果没有进行发现设置,此步骤由节点本身自动执行。由于这种自动引导从本质上讲是不安全的,因此当您在生产模式下第一次启动全新的群集时,你必须显式列出符合资格的主节点。也就是说,需要使用 cluster.initial_master_nodes 设置来设置该主节点列表。重新启动集群或将新节点添加到现有集群时,你不应使用此设置。
在新版 7.x 的 ES 中,对 ES 的集群发现系统做了调整,不再有 discovery.zen.minimum_master_nodes 这个控制集群脑裂的配置,转而由集群自主控制,并且新版在启动一个新的集群的时候需要有 cluster.initial_master_nodes 初始化集群主节点列表。如果一个集群一旦形成,你不该再设置该配置项,应该移除它。该配置项仅仅是集群第一次创建时设置的!集群形成之后,这个配置也会被忽略的!
cluster.initial_master_nodes 该配置项并不是需要每个节点设置保持一致,设置需谨慎,如果其中的主节点关闭了,可能会导致其他主节点也会关闭。因为一旦节点初始启动时设置了这个参数,它下次启动时还是会尝试和当初指定的主节点链接,当链接失败时,自己也会关闭!
因此,为了保证可用性,预备做主节点的节点不用每个上面都配置该配置项!保证有的主节点上就不设置该配置项,这样当有主节点故障时,还有可用的主节点不会一定要去寻找初始节点中的主节点!
关于 cluster.initial_master_nodes 可以查看如下资料:
- Bootstrapping a cluster
- Discovery and cluster formation settings
(10)其他配置项介绍
- Elasticsearch 集群中节点角色的介绍 对上文中的
node.master等配置做了介绍。如果本地仅是简单测试使用,上文中的node.master/node.data/node.ingest不用配置也没影响。
6、启动ES集群
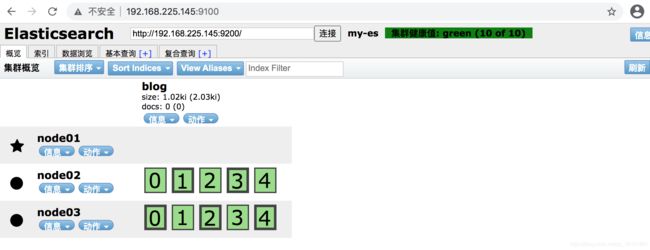
先启动 node01 节点,因为它设置了初始主节点的列表。这时候就可以使用 http://看到结果了。然后逐一启动 node02 和 node03。通过访问http://192.168.225.145:9200/_cat/nodes查看集群是否 OK,http://192.168.225.145:9200/_nodes将会显示节点更多的详情信息。
su es - l -c "/usr/local/es-7.10.0-node01/bin/elasticsearch -d"
su es - l -c "/usr/local/es-7.10.0-node02/bin/elasticsearch -d"
su es - l -c "/usr/local/es-7.10.0-node03/bin/elasticsearch -d"
7、集群验证
参考
ps -ef | grep elasticsearch
curl -X GET "localhost:9200/?pretty"
curl -X GET "localhost:9201/?pretty"
curl -X GET "localhost:9202/?pretty"
查看集群节点:
http://192.168.225.145:9200/_cat/nodes?v

验证集群磁盘分配情况:
http://192.168.225.145:9200/_cat/allocation?v

验证集群健康状况:
http://192.168.225.145:9200/_cat/health?v

查看集群的索引数:
http://192.168.225.145:9200/_cat/indices?v

手动添加一个blog索引,继续观察

注意: 如果集群节点只显示一个,则进到节点2、3的/usr/local/es-7.10.0-node01/data/目录下删除nodes文件,之后重启节点2、3的es进程即可
二、ES可视化插件ES-HEAD安装
参考ES可视化插件ES-HEAD安装
修改设置系统参数
#查看系统文件进程的打开数
ulimit -Hn
ulimit -Sn
#设置最大文件打开数
ulimit -n 65536
#修改系统限制的配置文件
/etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
/etc/sysctl.conf
* vm.max_map_count=262144
node环境配置
由于es-head需要node环境,所以需要安装node
下载node
解压
tar -xvf node-v4.4.7-linux-x64.tar.gz -C /usr/local/
vi /etc/profile
export NODE=/usr/local/node-v4.4.7-linux-x64
export PATH=$PATH:$NODE/bin
生效
source /etc/profile
查看
echo $PATH
node -v
安装ES-HEAD
下载head插件
下载
wget https://github.com/mobz/elasticsearch-head/archive/master.zip
安装zip和unzip命令:
yum list | grep zip/unzip
yum install zip -y
yum install unzip -y
解压
unzip elasticsearch-head-master.zip -d /usr/local
修改elasticsearch.yml的配置
增加参数,使head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
安装grunt
grunt是基于Node.js的项目构建工具,可以进行打包压缩、测试、执行等等的工作,head插件就是通过grunt启动。
进入到插件目录下面
cd /usr/local/elasticsearch-head-master
#安装npm命令
yum install npm -y
##下载安装grunt
npm install -g grunt-cli
#注意如果下载很慢,可以修改npm仓库地址
#显示当前的镜像网址
npm get registry
#https://registry.npmjs.org/
#使用淘宝的镜像网址
npm config set registry http://registry.npm.taobao.org
#npm config set registry https://registry.cnpmjs.org
#npm config set registry https://registry.npmjs.org
#清缓存
npm cache clean --force
##检测是否安装成功,如果执行命令后出现版本号就表明成功
grunt -version
#移除grunt-cli 命令
npm uninstall grunt-cli -g
##修改源码
Gruntfile.js,添加host正则匹配项
connect: {
server: {
options: {
port: 9100,
base: '.',
keepalive: true,
host: '*'
}
}
}
_site/app.js,修改es的链接地址
var ui = app.ns("ui");
var services = app.ns("services");
app.App = ui.AbstractWidget.extend({
defaults: {
base_uri: null
},
init: function(parent) {
this._super();
this.prefs = services.Preferences.instance();
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://192.168.225.145:9200";
##安装npm的服务,然后再head目录下面启动插件,特别注意的是es的地址不要写错。
npm install
grunt server
后台启动方式
grunt server &
然后执行命令
exit
如果elasticsearch设置的有密码:
则需要对elasticsearch.yml做以下配置后重启:
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-credentials: true
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
http.cors.allow-headers: Content-Type,X-Requested-With, X-Auth-Token, Content-Type, Content-Length, Authorization, Access-Control-Allow-Headers, Accept
完整配置如下:
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
cluster.name: my-es
node.name: node01
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.type: single-node
discovery.seed_hosts: ["127.0.0.1:9300"]
xpack.security.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-credentials: true
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
http.cors.allow-headers: Content-Type,X-Requested-With, X-Auth-Token, Content-Type, Content-Length, Authorization, Access-Control-Allow-Headers, Accept
访问时记得带上用户名和密码,如下:
http://192.168.76.134:9100/?auth_user=elastic&auth_password=123456

三、ik分词器安装
下载地址,如下版本对照:

#解压
unzip elasticsearch-analysis-ik-7.10.0.zip -d /usr/local/es-ik
#然后将所有内容复制到es的plugins下
cp -r /usr/local/es-ik/* /usr/local/es-7.10.0-node01/plugins/es-ik
cp -r /usr/local/es-ik/* /usr/local/es-7.10.0-node02/plugins/es-ik
cp -r /usr/local/es-ik/* /usr/local/es-7.10.0-node03/plugins/es-ik
#重启es即可
查看es
ps -ef | grep elasticsearch
四、部署 kibana
kibana下载地址
#解压
tar -xvf kibana-7.10.0-linux-x86_64.tar.gz -C /usr/local/
cd /usr/local/kibana-7.10.0-linux-x86_64/
vim config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.225.145:9200"]
kibana.index: ".kibana"
注: kibana.index,Kibana 在 Elasticsearch 中使用一个索引来存储保存的搜索、可视化效果和仪表盘。如果该索引不存在,Kibana会创建一个新的索引,默认 .kibana;
启动 kibana:
#设置权限
chown -R es: /usr/local/kibana-*
#后台启动
su es - l -c "nohup /usr/local/kibana-7.10.0-linux-x86_64/bin/kibana &"
#然后执行退出命令
exit
启动报错:

查看日志:
"tags":["error","elasticsearch","data"],"pid":230738,"message":"[resource_already_exists_exception]: index [.kibana_1/dB_2Qp0URLeN7ZFUeW96hg] already exists"}
查看索引:
curl ‘localhost:9200/_cat/indices?v’
删除对应的索引:
curl -XDELETE http://localhost:9200/.kibana
再次启动:
nohup: 打开'nohup.out' 失败: Permission denied
nohup: 打开'/home/es/nohup.out' 失败: No such file or directory
授权:
chown -R es: /home/es
再次启动报错:
FATAL Error: EACCES: permission denied, stat '*/.i18nrc.json'
授权:
[root@centos807 ~]# cd /usr/local/kibana-7.10.0-linux-x86_64
[root@centos807 kibana-7.10.0-linux-x86_64]# chmod a+w .i18nrc.json
使用密码方式配置:
kibana.yml完整配置如下:
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.76.134:9200"]
kibana.index: ".kibana"
elasticsearch.username: "kibana_system"
elasticsearch.password: "123456"
xpack.encryptedSavedObjects.encryptionKey: encryptedSavedObjects12345678909876543210
xpack.security.encryptionKey: encryptionKeysecurity12345678909876543210
xpack.reporting.encryptionKey: encryptionKeyreporting12345678909876543210

五、部署 filebeat
下载地址
部署一个测试用的nginx,用来作为filebeat的日志收集对象,观察一下效果。
tar -xvf filebeat-7.10.0-linux-x86_64.tar.gz -C /usr/local/
cd /usr/local/filebeat-7.10.0-linux-x86_64/
vi filebeat.yml
filebeat.inputs:
- type: log
enabled: true
#找一个日志路径即可
paths:
- /usr/local/nginx/logs/*.log
setup.kibana:
host: "192.168.225.145:5601"
output.elasticsearch:
hosts: ["192.168.225.145:9200"]
后台启动
chown -R es: /usr/local/filebeat*
su es - l -c "nohup /usr/local/filebeat-7.10.0-linux-x86_64/filebeat -c /usr/local/filebeat-7.10.0-linux-x86_64/filebeat.yml &"
具体配置可查看官方文档
带密码采集一台服务器中的不同日志
# ============================== Filebeat inputs ===============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /usr/local/app/rabbitmqlearn/logs/*.log
tags: ["rabbitmqlearn"]
fields:
index: "rabbitmqlearn_log"
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /usr/local/nginx/logs/*.log
tags: ["nginx"]
fields:
index: "nginx_log"
# =================================== Kibana ===================================
# Starting with Beats version 6.0.0, the dashboards are loaded via the Kibana API.
# This requires a Kibana endpoint configuration.
setup.kibana:
# Kibana Host
# Scheme and port can be left out and will be set to the default (http and 5601)
# In case you specify and additional path, the scheme is required: http://localhost:5601/path
# IPv6 addresses should always be defined as: https://[2001:db8::1]:5601
host: "localhost:5601"
username: "kibana"
password: "123456"
# ================================== Outputs ===================================
# Configure what output to use when sending the data collected by the beat.
# ---------------------------- Elasticsearch Output ----------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["localhost:9200"]
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
username: "elastic"
password: "123456"
indices:
- index: "filebeat-rabbitmqlearn_log-%{+YYYY-MM}"
when.contains:
fields:
index: "rabbitmqlearn_log"
- index: "nginx_log-%{+YYYY-MM}"
when.contains:
fields:
index: "nginx_log"
kibana页面配置


