困惑度、主题一致性,lda模型找出主题相关词
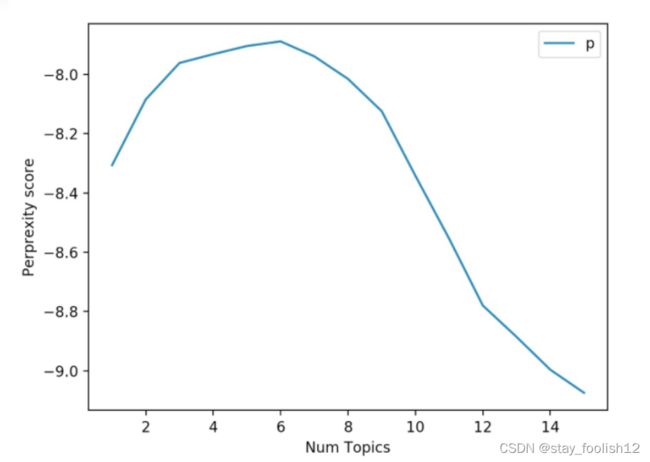
困惑度perplexity:句子的概率的倒数。如果句子的概率越大,说明这句话越符合人话的规律,即p(句子),pp困惑度越小。模型对该句子就越不困惑。


通俗一点解释下就是,困惑度表示的对于一篇文章来说,我们有多不确定它是属于某个主题的。即主题的个数越多,模型的困惑度就越低,但是注意一点,当主题数很多的时候,生成的模型往往会过拟合,所以不能单纯依靠困惑度来判断一个模型的好坏。这时候我们的另一个判断标准就有作用了。biubiu~一致性!
困惑度可视化:
def perplexity_visible_model(self, topic_num, data_num):
'''
@description: 绘制困惑度-主题数目曲线
@param {type}
@return:
'''
# texts = self.fenci_data()
_, corpus = self.weibo_lda()
x_list = []
y_list = []
for i in range(1,topic_num):
model_name = './lda_{}_{}.model'.format(i, data_num)
try:
lda = models.ldamodel.LdaModel.load(model_name)-
perplexity = lda.log_perplexity(corpus)
print(perplexity)
x_list.append(i)
y_list.append(perplexity)
except Exception as e:
print(e)
plt.xlabel('num topics')
plt.ylabel('perplexity score')
plt.legend(('perplexity_values'), loc='best')
plt.show()
主题一致性:coherence。更高的一致性分数表示更好的aspect可解释性,意味着更有意义,还有语义上更连贯。
def visible_model(self, topic_num, data_num):
'''
@description: 可视化模型
@param :topic_num:主题的数量
@param :data_num:数据的量
@return: 可视化lda模型
'''
dictionary, _ = self.weibo_lda()
texts = self.fenci_data()
x_list = []
y_list = []
for i in range(1,topic_num):
model_name = './lda_{}_{}.model'.format(i, data_num)
try:
lda = models.ldamodel.LdaModel.load(model_name)
cv_tmp = CoherenceModel(model=lda, texts=texts, dictionary=dictionary, coherence='c_v')
x_list.append(i)
y_list.append(cv_tmp.get_coherence())
except:
print('没有这个模型:{}'.format(model_name))
plt.plot(x_list, y_list)
plt.xlabel('num topics')
plt.ylabel('coherence score')
plt.legend(('coherence_values'), loc='best')
plt.show()

可借鉴网址:
https://zhuanlan.zhihu.com/p/106982034
实战:
#找到最佳k通过主题一致性得分去找
import tomotopy as tp
tp.isa
def find_k(docs,min_k=1,max_k=20,min_df=2):
#min_df 词语最少出现在两个文档中
import matplotlib.pyplot as plt
scores = []
for k in range(min_k,max_k):
mdl = tp.LDAModel(min_df = min_df,k = k,seed = 555)
#print("mdl",mdl)
for words in docs:
if words:
mdl.add_doc(words)
mdl.train(20)
coh = tp.coherence.Coherence(mdl)
scores.append(coh.get_score())
plt.plot(range(min_k,max_k),scores)
plt.xlabel("number of topics")
plt.ylabel("coherence")
plt.show()
find_k(docs =df['words'],min_k=1,max_k=40,min_df=2)
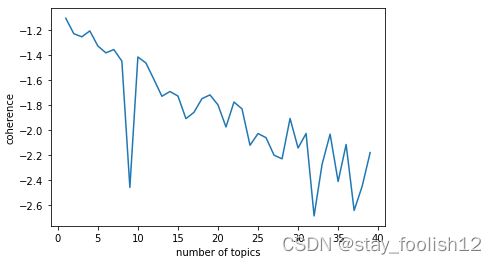
通过图形,我暂时将主题定为10个。其中的tomotopy可见网址:tomotopy | 速度最快的LDA主题模型