【深度学习MOT】SMILEtrack SiMIlarity LEarning for Multiple Object Tracking,论文
论文:https://arxiv.org/abs/2211.08824
文章目录
- Abstract
- Introduction
- 2. 相关工作
-
- 2.1 基于检测的跟踪
-
- 2.1.1 检测方法
- 2.1.2 数据关联方法
- 2.2 基于注意力的跟踪
- 3. 方法
-
- 3.1 架构概述
- 3.2 用于重新识别的相似性学习模块(SLM)
- Experimental Results
Abstract
多目标跟踪(MOT)在计算机视觉领域得到广泛研究,具有许多应用。基于检测的跟踪(TBD)是一种流行的多目标跟踪范式。TBD包括首先进行目标检测,然后进行数据关联、轨迹生成和更新的步骤。我们提出了一种受Siamese网络启发的相似性学习模块(SLM),用于提取重要的目标外观特征,并提出一种有效结合目标运动和外观特征的方法。
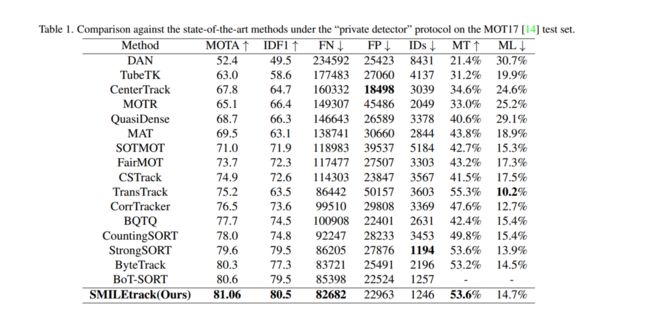
这种设计加强了目标运动和外观特征的建模,用于数据关联。我们为我们的SMILEtrack跟踪器设计了相似性匹配级联(SMC)以进行数据关联。SMILEtrack在MOTChallenge和MOT17测试集上分别达到了81.06的MOTA和80.5的IDF1。
Introduction
MOT是计算机视觉中的热门课题,在视频理解中起着重要作用。MOT的目标是估计每个目标的轨迹,并尝试将它们与视频序列中的每一帧关联起来。随着MOT的成功,它可以在社会中被广泛应用,例如车辆计算、计算机交互[25] [12]、智能视频分析和自动驾驶。在过去的几年里,主要和高效的MOT策略[1] [27] [26]基于基于检测的跟踪(TBD)范式方法。它根据检测结果进行跟踪,将问题分解为检测和关联两个步骤。在检测步骤中,我们需要在单个视频帧中定位感兴趣的物体,在关联步骤中将每个物体与现有轨迹连接或创建新的轨迹。然而,由于模糊的物体、遮挡和复杂的场景,它仍然面临挑战。
为了实现跟踪系统,解决方案模型可以分为分离检测和嵌入模型(SDE)以及联合检测和嵌入模型(JDE)。我们的方法属于SDE,其架构如图1所示。SDE至少需要两个功能组件:一个检测器和一个重新识别模型。
首先,检测器通过边界框定位单帧中的所有物体。然后,重新识别模型将从每个边界框中提取物体的特征以生成嵌入。最后,将每个边界框与现有轨迹中的一个关联,或创建一个新的轨迹。然而,SDE方法无法实现实时推断速度,因为当使用两个单独的模型来检测物体和提取嵌入时,需要进行多次计算。检测器和重新识别模型之间的特征无法共享,而SDE方法需要在推断时间内将重新识别模型应用于每个边界框以提取嵌入。面对这个问题,一个可行的解决方案是集成检测器和重新识别模型。JDE类别[26] [32]将检测器和嵌入模型组合在一个单次深度网络中。它可以通过仅推断一次模型同时输出检测结果和检测到的边界框的相应外观嵌入。
尽管JDE的成功使得MOT任务在精度方面取得了巨大的成果,但我们认为JDE仍然存在一些问题。例如,不同组件之间的特征冲突。我们认为用于目标检测任务和目标重新识别任务的特征是完全不同的。目标检测任务的特征需要高级特征来识别物体属于哪个类别,但重新识别任务的特征需要更多的低级特征来区分同一类别中的不同实例。因此,JDE中的共享特征模型可能会降低每个任务的性能。然而,正如我们上面提到的JDE的缺点,SDE可以克服这些缺点,仍然在MOT方面具有出色的潜力。
近年来,基于注意力机制的Transformer [24] 已被引入到计算机视觉领域,并取得了出色的结果。在多目标跟踪问题中,大部分基于Transformer的方法采用了CNN + Transformer的框架。这意味着模型首先通过CNN架构提取输入图像特征,然后将这些特征映射作为输入传递到Transformer中。与基于检测的跟踪方法不同,基于Transformer的方法通过将检测和数据关联部分结合在一起来实现跟踪结果。它可以通过单一模型直接输出轨迹的身份和位置,而无需使用任何额外的轨迹匹配技巧。尽管基于Transformer的方法在特征注意力方面取得了出色的结果,但在将整个图像输入到Transformer架构中时,推断速度仍然存在一定限制。
为了生成高质量的检测和目标外观,我们选择了SDE作为TBD模型,以解决JDE中的特征冲突问题。然而,我们认为大多数特征描述符无法清楚地区分不同对象之间的外观特征。
为了解决这个问题,我们提出了SMILEtrack,它结合了一个检测器和类似Siamese网络的相似性学习模块(SLM)。受到视觉Transformer [6] 的启发,我们创建了一个图像分割注意块(ISA),它使用了SLM中的注意力机制和图像分割机制。此外,我们还为视频中每个帧之间的对象匹配构建了一个相似性匹配级联(SMC)。我们跟踪系统的大致过程如下:首先,我们通过一个名为PRB [4] 的检测器预测目标边界框的位置。在获得物体边界框后,我们通过SMC将边界框与轨迹关联起来。
我们工作的贡献总结如下:
我们引入了一个名为SMILEtrack的分离检测和嵌入模型,以及相似性学习模块(SLM),该模块使用类似Siamese网络的架构来学习每个对象之间的相似性。
在SLM的特征提取部分,我们构建了一个图像分割注意块(ISA),它使用了Transformer的图像分割方法和注意力机制来学习对象特征。
为了完成轨迹匹配部分,我们为每个帧中的每个边界框构建了一个相似性匹配级联(SMC)来实现关联步骤。
2. 相关工作
2.1 基于检测的跟踪
基于检测的(TBD)算法在MOT问题中取得了显著的成功,已经成为MOT框架中最受欢迎的方法。TBD方法的主要任务是在视频的每一帧之间关联检测结果,以实现MOT系统。整个工作可以大致分为两部分。
2.1.1 检测方法
Faster R-CNN [18] 是一种两阶段检测器,它使用VGG-16作为主干网络,使用区域建议网络(RPN)来检测边界框。SSD [11] 使用锚点机制来取代RPN,在每个特征图上设置不同大小的锚点,以增强检测质量。YOLO系列 [15] [16] [17] [2] 是一种一阶段方法,它使用特征金字塔网络(FPN)来解决目标检测中的多尺度问题,速度和精度表现出色。尽管基于锚点的检测器可以取得出色的性能,但仍存在一些由锚点引起的问题。例如,基于锚点的检测器很难根据情况调整一些锚点的超参数,而在训练过程中计算锚点的交并比(IOU)需要大量时间和内存。为了克服这些问题,无锚点检测器是另一种选择。CornerNet [9] 是一种无锚点方法,它利用热图和角点池化代替锚点来预测目标的左上角和右下角,然后将这两个点匹配以生成物体的边界框。与CornerNet相比,CenterNet [34] 通过中心池化和级联角点池化直接预测目标的中心点。YOLOX将YOLO系列从基于锚点的检测器转变为无锚点检测器。此外,它使用解耦的头部来提高检测的准确性。
2.1.2 数据关联方法
在MOT系统中,必须克服许多挑战,如物体遮挡、拥挤的场景和运动模糊。因此,数据关联方法需要小心处理。SORT [1] 首先使用卡尔曼滤波器根据当前帧的物体位置预测对象的未来位置,然后通过计算现有目标的检测和预测边界框之间的IOU距离生成分配成本矩阵。最后,通过匈牙利算法匹配分配成本矩阵。尽管SORT在推断时间方面具有较高的速度,但由于它不涉及对象外观信息,因此无法处理长时间遮挡问题或快速运动的对象。
为了解决遮挡问题,Deep SORT [27] 使用预训练的CNN模型提取边界框外观特征,然后使用外观特征计算轨迹和检测之间的相似性。最后,使用匈牙利算法完成分配。
这种方法可以有效减少ID切换的次数,但Deep SORT中的检测模型和特征提取模型是分开的,这导致推断速度远低于实时。面对这个问题,JDE [26] 将检测器和嵌入模型组合成一个单次网络,它可以实时运行,并且在准确性上与两阶段方法相当。FairMOT [32] 展示了锚点带来的不公平问题,它采用了一种基于CenterNet的无锚点方法,在多个数据集中(如MOT17 [14])的性能大幅提升。然而,我们认为JDE模型存在一些问题,比如不同组件之间的特征冲突。
与此同时,一些MOT跟踪方法 [21] [22] 放弃了物体外观特征,仅通过应用高性能的检测器和运动信息来完成跟踪系统。尽管这些方法在MOTChallenge基准测试中可以达到最先进的性能和高推断速度,但我们认为这部分是因为MOTChallenge基准数据集中的运动模式相对简单。
此外,不考虑物体外观特征可能导致在更拥挤的场景中,物体跟踪的准确性和鲁棒性较差。
2.2 基于注意力的跟踪
在使用Transformer进行目标检测取得成功后,Trackformer [13] 将MOT视为一种集合预测问题,基于DETR构建,添加了对象查询和自回归轨迹查询来进行目标跟踪。
TransTrack [23] 基于可变形DETR构建,并具有两个解码器,一个用于当前帧检测,另一个用于先前帧检测。它通过在两个解码器之间匹配检测框来解决跟踪问题。TransCenter [29] 是基于点的跟踪方法,提出了一个密集的查询特征图,使用多尺度的输入图像来实现基于Transformer的MOT。
3. 方法
在本节中,我们介绍SMILEtrack模型的细节,包括相似性学习模块(SLM)以及用于每一帧中的框关联的相似性匹配级联(SMC)。
3.1 架构概述
SMILEtrack的整体架构如图2所示。我们的框架可以分为以下几个步骤:(1)检测目标位置:为了定位目标物体的位置,我们采用PRB作为检测器。 (2)数据关联:通过关联相邻帧中的每个物体来解决MOT问题。在通过PRB生成的检测结果之后,我们计算每一帧之间的运动相似性矩阵和外观相似性矩阵,然后通过匈牙利算法解决线性分配问题,其中成本矩阵与这两个矩阵相结合。

3.2 用于重新识别的相似性学习模块(SLM)
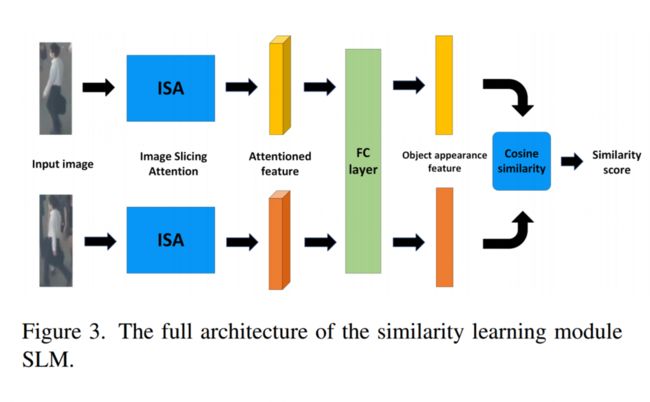
为了实现稳健的跟踪质量,目标的外观信息是不可或缺的。一些跟踪方法已经考虑了目标的外观信息。例如,DeepSORT使用一个由简单CNN构建的深度外观描述符来提取目标的外观特征。尽管外观描述符可以提取有用的外观特征,我们认为外观描述符无法清楚地区分不同物体之间的外观特征。为了提取更具有辨识度的外观特征,我们提出了一个类似Siamese网络架构的相似性学习模块SLM。SLM的详细信息如图3所示。
后面翻译略,感兴趣可以看论文。
Experimental Results