PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(11)——卷积神经网络
-
- 0. 前言
- 1. 全连接网络的缺陷
- 2. 卷积神经网络基本组件
-
- 2.1 卷积
- 2.2 步幅和填充
- 2.3 池化
- 2.3 卷积神经网络完整流程
- 3. 卷积和池化相比全连接网络的优势
- 4. 使用 PyTorch 构建卷积神经网络
-
- 4.1 使用 PyTorch 构建 CNN 架构
- 4.2 验证 CNN 输出
- 小结
- 系列链接
0. 前言
卷积神经网络 (Convolutional Neural Network, CNN) 是一种非常强大的深度学习模型,广泛应用于图像分析、目标检测、图像生成等任务中。CNN 的核心思想是卷积操作和参数共享,卷积操作通过滑动滤波器(也称为卷积核)在输入数据上进行元素级的乘积和求和运算,从而提取局部特征。通过多个滤波器的组合,CNN 可以学习到不同层次的特征表示,从低级到高级的抽象特征。本节从传统全连接神经网络的缺陷为切入点,介绍了卷积神经网络的优势及其基本组件,并使用 PyTorch 构建卷积神经网络。
1. 全连接网络的缺陷
在深入研究卷积神经网络 (Convolutional Neural Network, CNN) 之前,我们首先介绍传统深度神经网络的主要缺陷。传统深度前馈神经网络(也称全连接网络)的局限性之一是它不满足平移不变性,也就是说,在全连接网络看来,图像右上角有猫与位于图像中心的猫被视为不同对象,即使这是同一只猫。另外,全连接网络受对象大小的影响,如果训练集中大多数图像中的对象较大,而训练数据集图像中包含相同的对象但占据图像画面的比例较小,则全连接网络可能无法对图像进行正确分类。
接下来,我们通过具体示例来了解全连接网络的缺陷,继续使用在 PyTorch 构建深度神经网络中基于 Fashion-MNIST 数据集构建的模型,并预测给定图像对应的类别。
(1) 从训练图像中获取随机图像:
ix = 24150
plt.imshow(tr_images[ix], cmap='gray')
plt.title(fmnist.classes[tr_targets[ix]])
plt.show()

(2) 将图像输入到训练完毕的神经网络模型中,对输入图像执行预处理,并预测图像对应于各类别的概率:
img = tr_images[ix]/255.
img = img.view(28*28)
img = img.to(device)
np_output = model(img).cpu().detach().numpy()
print(np.exp(np_output)/np.sum(np.exp(np_output)))
"""
[3.1946290e-02 1.2138572e-03 8.1082803e-01 9.7291003e-04 8.0925472e-02
2.9379700e-07 7.3724821e-02 3.3111525e-07 3.1927411e-04 6.8671055e-05]
"""
从输出结果中,可以看到概率最高的是第 2 个索引,对应于 Pullover 类别。
(3) 多次平移图像,并记录预测结果。
创建一个存储预测结果的列表:
preds = []
创建循环,将图像从原始位置向右移动:
for px in range(-5,6):
对图像进行预处理:
img = tr_images[ix]/255.
img = img.view(28, 28)
在 for 循环中平移图像:
img2 = np.roll(img, px, axis=1)
在以上代码中,使用 axis=1 指定图像像素水平移动,将移动后的图像存储为张量对象并注册到设备中:
img3 = torch.Tensor(img2).view(28*28).to(device)
将 img3 输入到经过训练的模型以预测图像类别,并将其追加到存储预测结果列表中:
np_output = model(img3).cpu().detach().numpy()
preds.append(np.exp(np_output)/np.sum(np.exp(np_output)))
(4) 可视化模型对所有平移图像的预测( -5 像素到 +5 像素):
import seaborn as sns
fig, ax = plt.subplots(1,1, figsize=(12,10))
plt.title('Probability of each class for various translations')
sns.heatmap(np.array(preds), annot=True, ax=ax, fmt='.2f', xticklabels=fmnist.classes, yticklabels=[str(i)+str(' pixels') for i in range(-5,6)], cmap='gray')
plt.show()

图像内容并没有任何变化,因为对图像像素执行了平移,然而,当平移超过 2 个像素时,图像的预测类别发生了改变。这是因为在训练模型时,所有训练图像中的内容都处于中心位置,当使用偏离中心的平移图像进行测试时,模型将输出错误预测结果。这些问题的存在就是我们需要使用 CNN 的原因。
2. 卷积神经网络基本组件
卷积神经网络 (Convolutional Neural Network, CNN) 是处理图像时最常用的架构,CNN 解决了传统全连接神经网络的主要缺陷,除了图像分类,还可以用于目标检测、图像分割、GAN 等等,本质上,在使用图像作为输入的网络中,都可以使用 CNN 架构。在本节中,我们将详细介绍 CNN 中卷积过程的工作原理。
2.1 卷积
卷积本质上是两个矩阵之间的乘法(矩阵乘法是训练神经网络的关键要素)——通常一个矩阵具有较大尺寸,另一个矩阵则较小。为了确保我们对卷积过程有较好的理解,我们首先查看以下例子。
假设我们有两个矩阵用于执行卷积。给定矩阵 A 和矩阵 B 如下:

在进行卷积时,我们将较小的矩阵在较大的矩阵上滑动,在上述两个矩阵中,当较小的矩阵 B 需要在较大矩阵的整个区域上滑动时,会得到 9 次乘法运算,过程如下:
在矩阵 A 中从第 1 个元素开始选取与矩阵 B 相同尺寸的子矩阵 [ 1 2 0 1 1 1 3 3 2 ] \left[ \begin{array}{ccc} 1 & 2 & 0\\ 1 & 1 & 1\\ 3 & 3 & 2\\\end{array}\right] 113213012 和矩阵 B 相乘并求和:

1 × 3 + 2 × 1 + 0 × 1 + 1 × 2 + 1 × 3 + 1 × 1 + 3 × 2 + 3 × 2 + 2 × 3 = 29 1\times 3+2\times 1+0\times 1+1\times 2+1\times 3+1\times 1+3\times 2+3\times 2 + 2\times 3=29 1×3+2×1+0×1+1×2+1×3+1×1+3×2+3×2+2×3=29
然后,向右滑动一个窗口,选择第 2 个与矩阵 B 相同尺寸的子矩阵 [ 2 0 2 1 1 2 3 2 1 ] \left[ \begin{array}{ccc} 2 & 0 & 2\\ 1 & 1 & 2\\ 3 & 2 & 1\\\end{array}\right] 213012221 和矩阵 B 相乘并求和:

2 × 3 + 0 × 1 + 2 × 1 + 1 × 2 + 1 × 3 + 2 × 1 + 3 × 2 + 2 × 2 + 1 × 3 = 28 2\times 3+0\times 1+2\times 1+1\times 2+1\times 3+2\times 1+3\times 2+2\times 2 + 1\times 3=28 2×3+0×1+2×1+1×2+1×3+2×1+3×2+2×2+1×3=28
然后,再向右滑动一个窗口,选择第 3 个与矩阵 B 相同尺寸的子矩阵 [ 0 2 3 1 2 0 2 1 2 ] \left[ \begin{array}{ccc} 0 & 2 & 3\\ 1 & 2 & 0\\ 2 & 1 & 2\\\end{array}\right] 012221302 和矩阵 B 相乘并求和:

0 × 3 + 2 × 1 + 3 × 1 + 1 × 2 + 2 × 3 + 0 × 1 + 2 × 2 + 1 × 2 + 2 × 3 = 25 0\times 3+2\times 1+3\times 1+1\times 2+2\times 3+0\times 1+2\times 2+1\times 2 + 2\times 3=25 0×3+2×1+3×1+1×2+2×3+0×1+2×2+1×2+2×3=25
当向右滑到尽头时,向下滑动一个窗口,并从矩阵 A 左边开始,选择第 4 个与矩阵 B 相同尺寸的子矩阵 [ 1 1 1 3 3 2 1 0 2 ] \left[ \begin{array}{ccc} 1 & 1 & 1\\ 3 & 3 & 2\\ 1 & 0 & 2\\\end{array}\right] 131130122 和矩阵 B 相乘并求和:

1 × 3 + 1 × 1 + 1 × 1 + 3 × 2 + 3 × 3 + 2 × 1 + 1 × 2 + 0 × 2 + 2 × 3 = 30 1\times 3+1\times 1+1\times 1+3\times 2+3\times 3+2\times 1+1\times 2+0\times 2 + 2\times 3=30 1×3+1×1+1×1+3×2+3×3+2×1+1×2+0×2+2×3=30
然后,继续向右滑动,并重复以上过程滑动矩阵窗口,直到滑动到最后一个子矩阵为止,得到最终的结果 [ 29 28 25 30 30 27 20 24 34 ] \left[ \begin{array}{ccc} 29 & 28 & 25\\ 30 & 30 & 27\\ 20 & 24 & 34\\\end{array}\right] 293020283024252734 :

完整的卷积计算过程如以下动图所示:

通常,我们把较小的矩阵 B 称为滤波器 (filter) 或卷积核 (kernel),使用 ⊗ \otimes ⊗ 表示卷积运算,较小矩阵中的值通过梯度下降被优化学习,卷积核中的值则为网络权重。在计算机视觉中,卷积后得到的矩阵,也称为特征图 (feature map)。
滤波器是在模型开始训练时随机初始化的权重矩阵,模型会在训练过程中学习滤波器的最佳权重值。一般来说,CNN 中的滤波器越多,模型能够学习到的图像特征就越多,在后续学习中我们会介绍滤波器学习到的内容。滤波器能够学习图像中的不同特征,例如,某个滤波器可能会学习到如何分辨猫的耳朵,并在图像包含猫的耳朵时能够卷积得到较高激活(即矩阵乘法值)。
卷积核的通道数与其所乘矩阵的通道数相等。例如,当图像输入形状为 5 x 5 x 3 时(其中 3 为图像通道数),形状为 3 x 3 的卷积核也将具有 3 个通道,以便进行矩阵卷积运算:

可以看到无论卷积核有多少通道,一个卷积核计算后都只能得到一个通道。多为了捕获图像中的更多特征,通常我们会使用多个卷积核,得到多个通道的特征图,当使用多个卷积核时,计算过程如下:
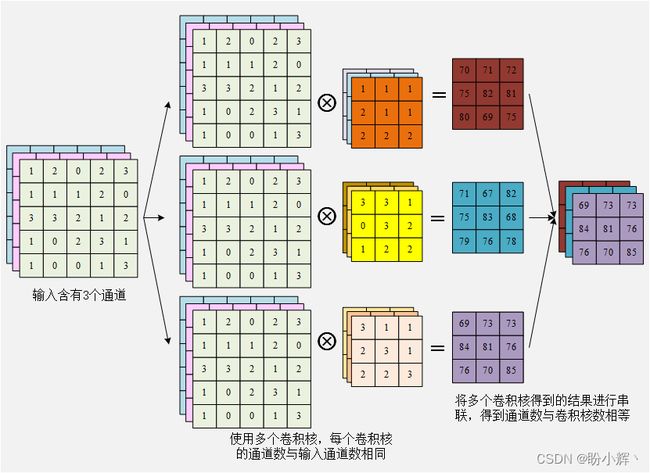
处理具有三个通道的彩色图像时,与原始图像卷积的滤波器也需要具有三个通道(每次卷积的计算结果为单个输出矩阵)。如果滤波器与网络中间输出进行卷积,比如中间输出形状为 64 x 112 x 112,则每个滤波器都包括 64 个通道来获取输出;此外,如果有 512 个滤波器与中间层输出进行卷积,则卷积输出后的形状为 512 x 111 x 111。
需要注意的是,卷积并不等同于滤波,最直观的区别在于滤波后的图像大小不变,而卷积会改变图像大小,关于它们之间更详细的计算差异,并非本节重点,因此不再展开介绍。
2.2 步幅和填充
2.2.1 步幅
在前面的示例中,卷积核每次计算时在水平和垂直方向只移动一个单位,因此可以说卷积核的步幅 (Strides) 为 (1, 1),步幅越大,卷积操作跳过的值越多,例如以下为步幅为 (2, 2) 时的卷积过程:

2.1.3 填充
在前面的示例中,卷积操作对于输入矩阵的不同位置计算的次数并不相同,具体来说对于边缘的数值在卷积时,仅仅使用一次,而位于中心的值则会被多次使用,因此可能导致卷积错过图像边缘的一些重要信息。如果要增加对于图像边缘的考虑,我们将在输入矩阵的边缘周围的填充 (Padding) 0,下图展示了用 0 填充边缘后的矩阵进行的卷积运算,这种填充形式进行的卷积,称为 same 填充,卷积后得到的矩阵大小为 ⌊ d + 2 p − k s ⌋ + 1 \lfloor\frac {d+2p-k} s\rfloor+1 ⌊sd+2p−k⌋+1,其中 s s s 表示步幅, p p p 表示填充大小, k k k 表示滤波器尺寸。而未进行填充时执行卷积运算,也称为 valid 填充。

完成此操作后,可以在卷积操作的输出之上执行激活函数,CNN 支持常见的所有可用激活函数,包括 Sigmoid,ReLU 和 LeakyReLU 等。
2.3 池化
研究了卷积的工作原理之后,我们将了解用于卷积操作之后的另一个常用操作:池化 (Pooling)。假设卷积操作的输出如下,为 2 x 2:
[ 29 28 20 24 ] \left[ \begin{array}{cc} 29 & 28\\ 20 & 24\\\end{array}\right] [29202824]
假设使用池化块(或者类比卷积核,我们也可以称之为池化核)为 2 x 2 的最大池化,那么将会输出 29 作为池化结果。假设卷积步骤的输出是一个更大的矩阵,如下所示:
[ 29 28 25 29 20 24 30 26 27 23 26 27 24 25 23 31 ] \left[ \begin{array}{cccc} 29 & 28 & 25 & 29\\ 20 & 24 & 30 & 26\\ 27 & 23 & 26 & 27\\ 24 & 25 & 23 & 31\\\end{array}\right] 29202724282423252530262329262731
当池化核为 2 x 2,且步幅为 2 时,最大池化会将此矩阵划分为 2 x 2 的非重叠块,并且仅保留每个块中最大的元素值,如下所示:
[ 29 28 ∣ 25 29 20 24 ∣ 30 26 — — — — — 27 23 ∣ 26 27 24 25 ∣ 23 31 ] = [ 29 30 27 31 ] \left[ \begin{array}{ccccc} 29 & 28 & | & 25 & 29\\ 20 & 24 & | & 30 & 26\\ —&—&—&—&—\\ 27 & 23 & | & 26 & 27\\ 24 & 25 & | & 23 & 31\\\end{array}\right]=\left[ \begin{array}{cc} 29 & 30\\ 27 & 31\\\end{array}\right] 2920—27242824—2325∣∣—∣∣2530—26232926—2731 =[29273031]
从每个池化块中,最大池化仅选择具有最高值的元素。除了最大池化外,也可以使用平均池化,其将输出每个池化块中的平均值作为结果,在实践中,与其他类型的池化相比,最常使用的池化为最大池化。
2.3 卷积神经网络完整流程
我们已经了解了卷积、滤波器和池化,以及它们对图像维度的影响。在 CNN 中通常还需要另一个关键组件——展平层。
为了理解展平过程,使用上一节得到的池化层输出,将输出展平后输出如下:
[ 29 30 27 31 ] \left[ \begin{array}{cccc} 29 & 30 & 27 & 31\end{array}\right] [29302731]
这样,就可以将 flatten 层视为全连接层的输入层,将其通过若干隐藏层后,获得用于预测图像类别的输出。综上,一个 CNN 的完整流程如下:

在上图中,可以看到 CNN 模型的整体流程,首先将图像通过多个滤波器进行卷积,然后进行池化(并数次重复执行卷积和池化过程),然后最后的池化操作输出展平,这部分称为特征学习 (feature learning)。
特征学习部分基本上由卷积和池化操作构成,使用滤波器从图像中提取相关特征,使用池化聚合特征信息,从而减少展平层的节点数量。如果直接展平输入图像,即使图像大小仅为 300 x 300=90000 像素,如果在隐藏层中有 1000 个神经节点,则在隐藏层就大约需要 900000x1000=90000000 个参数,计算量巨大。而卷积和池化有助于减少图像特征数量,降低计算量。最后,网络的分类 (classification) 部分类似于在使用 PyTorch 构建神经网络中介绍的全连接神经网络。
3. 卷积和池化相比全连接网络的优势
传统神经网络的缺点之一是每个像素都具有不同的权重。因此,如果这些权重要用于除原始像素以外的相邻像素,则神经网络得到的输出将不是非常准确。在 CNN 中,图像中的像素共享由每个卷积核构成的权重,相比全连接网络具有以下优势:
- 参数共享:在卷积层中,权重参数被共享,这意味着每个卷积核在整个输入图像上进行滑动并提取特征,这种参数共享的方式显著减少了需要学习的参数数量,降低了模型复杂度,从而减少了过拟合的风险
- 局部感知和空间结构:卷积层通过使用局部感知域(感受野)的方式来识别图像中的特征,利用了图像的空间结构信息,这使得卷积神经网络在处理图像等二维数据时能够更好地捕捉到图像的局部特征和空间关系,从而提高了图像处理的效果
- 参数量减少:由于卷积层采用参数共享的机制,卷积神经网络通常比全连接网络具有更少的参数量,这不仅减少了训练网络所需的计算资源和时间,而且降低了过拟合的风险,有助于更好地泛化到新的数据集
- 平移不变性:卷积操作具有平移不变性,也就是说,当输入图像发生平移时,卷积层的输出不会改变,这种平移不变性使得卷积神经网络对于图像中的平移和位置变化具有鲁棒性,可以更好地处理具有不同位置和尺度的图像
- 降低计算复杂度:由于参数共享和局部感知机制,卷积神经网络的计算复杂度相对较低,这使得
CNN在处理大规模图像数据时比全连接网络更高效,并且适用于部署在资源受限的设备上,如移动设备和嵌入式系统
接下来,我们从卷积和池化角度理解感受野,感受野是卷积神经网络中每个网络层输出的特征图中的单个元素映射回原始输入特征中的区域大小,假设我们对形状为 100 x 100 的图像执行两次卷积池化操作,两个卷积池化操作结束时的输出的形状为 25 x 25 (假设在卷积操作时使用填充操作),25 x 25 的输出中的每个单元对应于原始图像中尺寸为 4 x 4 的部分。通常网络层越深,其输出特征的元素对应感受野越大。
4. 使用 PyTorch 构建卷积神经网络
CNN 是计算机视觉的基础模块之一,在了解其工作原理后,本节中,我们通过代码了解 CNN 前向传播过程中的计算流程。
首先,我们使用 PyTorch 在一个简单数据示例上构建一个 CNN 架构,然后通过在 Python 中从零开始构建前向传播来验证输出结果。
4.1 使用 PyTorch 构建 CNN 架构
(1) 首先,导入相关的库并创建数据集:
import torch
from torch import nn
from torch.utils.data import TensorDataset, DataLoader
from torch.optim import Adam
device = 'cuda' if torch.cuda.is_available() else 'cpu'
X_train = torch.tensor([[[[1,2,3,4],[2,3,4,5],[5,6,7,8],[1,3,4,5]]],[[[-1,2,3,-4],[2,-3,4,5],[-5,6,-7,8],[-1,-3,-4,-5]]]]).to(device).float()
X_train /= 8
y_train = torch.tensor([[0],[1]]).to(device).float()
需要注意的是,与 Keras 等机器学习库不同,PyTorch 期望输入的形状为 N x C x H x W,其中 N 是图像数量(批大小),C 是通道数,H 是高度,W 是宽度。
将输入数据除以最大输入值缩放输入数据集,使其范围在 -1 到 +1 之间。以上输入数据集的形状为 (2,1,4,4),因为有两个数据点,每个数据点的形状为 4 x 4 并且有 1 个通道。
(2) 定义模型架构:
def get_model():
model = nn.Sequential(
nn.Conv2d(1, 1, kernel_size=3),
nn.MaxPool2d(2),
nn.ReLU(),
nn.Flatten(),
nn.Linear(1, 1),
nn.Sigmoid(),
).to(device)
loss_fn = nn.BCELoss()
optimizer = Adam(model.parameters(), lr=1e-2)
return model, loss_fn, optimizer
在以上模型中,指定输入图像中有 1 个通道,使用 nn.Conv2d 方法指定卷积后包括 1 个通道(大小为 3 x 3 的滤波器),使用 nn.MaxPool2d 执行最大池化,使用 nn.ReLU() 执行 ReLU 激活,然后展平激活值并连接到输出层,输出层中包含一个神经元。由于输出为二分类问题,因此使用二元交叉熵损失 nn.BCELoss(),还指定使用学习率为 0.001 的 Adam 优化器进行优化。
(3) 调用 get_model() 函数初始化模型、损失函数 (loss_fn) 和优化器后,使用 torch_summary (可以使用 pip install torch_summary 命令安装 torch_summary 库)查看模型架构摘要:
from torchsummary import summary
model, loss_fn, optimizer = get_model()
print(summary(model, tuple(X_train.shape[1:])))
"""
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 1, 2, 2] 10
MaxPool2d-2 [-1, 1, 1, 1] 0
ReLU-3 [-1, 1, 1, 1] 0
Flatten-4 [-1, 1] 0
Linear-5 [-1, 1] 2
Sigmoid-6 [-1, 1] 0
================================================================
Total params: 12
Trainable params: 12
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 0.00
----------------------------------------------------------------
"""
接下来,我们介绍每一网络层的参数来源。 Conv2d 类的参数如下:

在示例中,指定卷积核大小 (kernel_size) 为 3,输出通道数 (out_channels) 为 1 (即滤波器数量为 1),其中初始(输入)通道的数量为 1。对于每个输入图像,形状为 1 x 4 x 4 的输入使用滤波器尺寸为 3x3 的卷积,因此,输出形状为 1 x 2 x 2。网络包含 10 个参数( 3 x 3 = 9 个权重参数和 1 个卷积核偏置)。而 MaxPool2d、ReLU 和 Flatten 层没有参数,因为这些计算并不涉及权重或偏置。
全连接层有 2 个参数( 1 个权重和 1 个偏置),因此,共有 12 个参数( 10 个来自卷积操作,2 个来自全连接层)。
(4) 重用在使用 PyTorch 构建神经网络中的代码训练模型,使用 PyTorch 构建深度神经网络,其中定义了训练批数据的函数 train_batch();然后,获取 DataLoader 并在 2,000 个 epoch 上对其进行训练。
定义在批数据上训练模型的函数 train_batch():
def train_batch(x, y, model, optimizer, loss_fn):
model.train()
prediction = model(x)
# print(prediction)
batch_loss = loss_fn(prediction, y)
batch_loss.backward()
optimizer.step()
optimizer.zero_grad()
return batch_loss.item()
通过使用 TensorDataset 方法指定数据集,然后使用 DataLoader 加载数据集定义训练 DataLoader:
trn_dl = DataLoader(TensorDataset(X_train, y_train))
在以上代码中,直接利用 TensorDataset 方法,该方法提供与输入数据对应的对象。接下来,训练模型:
for epoch in range(2000):
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
batch_loss = train_batch(x, y, model, optimizer, loss_fn)
(5) 利用第一个数据点执行前向传递:
print(model(X_train[:1]))
# tensor([[0.0028]], device='cuda:0', grad_fn=)
在下一节中,我们将了解 CNN 中的前向传播工作原理,并从零开始构建 CNN 前向传播流程,验证本节模型计算结果。
4.2 验证 CNN 输出
在本节中,通过实现 CNN 的前向传播过程来验证从模型中获得的输出,本节仅用于帮助了解 CNN 的工作原理,而无需在实际应用场景中执行。
(1) 提取上一小节架构的卷积层和全连接层的权重和偏置。
提取模型的各个层:
print(list(model.children()))
"""
[Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1)), MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False), ReLU(), Flatten(start_dim=1, end_dim=-1), Linear(in_features=1, out_features=1, bias=True), Sigmoid()]
"""
提取模型中的所有层对应的 weights 属性:
(cnn_w, cnn_b), (lin_w, lin_b) = [(layer.weight.data, layer.bias.data) for layer in list(model.children()) if hasattr(layer, 'weight')]
在以上代码中,hasattr(layer,'weight') 会返回一个布尔值用于指示网络层是否包含权重属性。
只有卷积 (Conv2d) 层和全连接层包含参数的网络层,分别保存为 cnn_w 和 cnn_b 以及 lin_w 和 lin_b。cnn_w 的形状为 1 x 1 x 3 x 3,对应于具有一个通道、形状为 3 x 3 的一个滤波器,cnn_b 的形状为 `1,对应于此滤波器的偏置值。
(2) 要对输入值执行 cnn_w 卷积运算,必须初始化一个零矩阵用于存储计算结果 (sumprod),其中高度为 h_i - h_k + 1,宽度为 w_i - w_k + 1,其中 h_i 表示输入高度,h_k 表示滤波器高度,w_i 表示输入宽度,w_k 表示滤波器宽度:
h_im, w_im = X_train.shape[2:]
h_conv, w_conv = cnn_w.shape[2:]
sumprod = torch.zeros((h_im - h_conv + 1, w_im - w_conv + 1))
(3) 接下来,我们通过模拟卷积过程对输入数据执行卷积,沿着行和列执行矩阵乘法(卷积),首先将滤波器 (cnn_w) 形状由 1 x 1 x 3 x 3 重塑为 3 x 3,执行卷积后添加滤波器偏置项 (cnn_b),填充到结果 sumprod 中:
for i in range(h_im - h_conv + 1):
for j in range(w_im - w_conv + 1):
img_subset = X_train[0, 0, i:(i+3), j:(j+3)]
model_filter = cnn_w.reshape(3,3)
val = torch.sum(img_subset*model_filter) + cnn_b
sumprod[i,j] = val
在以上代码中,img_subset 存储了与滤波器执行卷积的输入部分。假设输入形状为 4 x 4,滤波器形状为 3 x 3,则输出形状为 2 x 2,sumprod 的输出如下:
tensor([[-2.2831, -2.9537],
[-0.6738, -1.5616]])
(4) 在输出 (sumprod) 上执行 ReLU 激活,然后使用最大池化 (MaxPooling)。
通过将输出最小值限制为 0,模拟 ReLU 激活函数:
print(sumprod.clamp_min_(0))
对上一步输出执行池化操作:
pooling_layer_output = torch.max(sumprod)
"""
tensor([[0., 0.],
[0., 0.]])
"""
(5) 通过线性激活传递以上输出:
intermediate_output_value = pooling_layer_output * lin_w + lin_b
(5) 由于使用二元交叉熵损失函数,因此通过 sigmoid 函数计算输出结果:
print(torch.sigmoid(intermediate_output_value))
# tensor([[0.0028]], device='cuda:0')
使用以上代码可以得到与使用 PyTorch 的 forward 方法相同输出结果,从而验证了 CNN 的计算流程。
小结
卷积神经网络 (Convolutional Neural Network, CNN) 是一种广泛应用的深度学习模型。通过参数共享、局部感知和空间结构等优势,能够更好地处理图像数据,并在图像识别、目标检测和图像生成等任务中展现出强大的能力。在本节中,介绍了卷积的计算方法以及卷积神经网络的基本组件,并使用 PyTorch 构建了卷积神经网络以深入了解其工作原理。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法