sequencer和sequence
●了解了sequencer与driver之间传递sequence item的握手过程,同时也掌握了sequence与item之间的关系。
●接下来需要就sequence挂载到sequencer的常用方法做出总结,大家可以通过对这些常用方法和宏的介绍,了解到它们不同的使用场景。
●面对多个sequence如果需要同时挂载到sequencer时,那就面临着仲裁的需要,uvm_sequencer 自带有仲裁特性,结合sequence的优先级设定,最终可以实现想要的效果。
●对于UVM的初学者,我们往往给出的建议是,如果可以正确区别方法start()和宏`uvm_do, 那就拿下了sequence发送和嵌套的半壁江山。
●然而考虑到读者对技艺的高要求,我们这里会系统性地阐述各种方法和宏之间的关系,以及讨论什么时候可以使用方法、什么时候可以使用宏。
●对于已经习惯于sequence宏使用的用户而言,当他们再切回到sequence方法、或者调试这些方法时,会有一种不适感,但是如果你想要对sequence发送做出更准确的控制,我们还须正本清源,首先熟悉sequence的方法。
class bus_trans extends uvm_sequence_item;
rand int data;
`uvm_object_utils_begin(bus_trans)
`uvm_field_int(data,UVM_ALL_ON)
`uvm_object_utils_end
...
endclass
class child_seq extends uvm_sequence;
`uvm_object_utils(child_seq)
...
task body();
uvm_sequence_item tmp;
bus_trans req;
tmp=create_item(bus_trans::get_type(),m_sequencer,"req");
void`($cast(req,tmp));
start_item(req);
req.randomize with {data == 10;};
finish_item(req);
endtask
endclasstop sequence里既有child sequence,又有item。child sequence挂载到sequencer上,最终也会执行其body,也就是按照最小的item进行发送
class top_seq extends uvm_sequence;
`uvm_object_utils(top_seq)
...
task body();
uvm_sequence_item tmp;
child_seq cseq;
bus_trans req;
//create child sequence and item
cseq=child_seq::type_id::create("cseq");
tmp=create_item(bus_trans::get_type(),m_sequencer,"req");
//send child sequence via start()
cseq.start(m_sequencer,this); //发送sequence,和test一样
//send sequence item
void'($cast(req,tmp)); //发送item
start_item(req);
req.randomize with {data==20;};
finish_item(req);
endtask
endclass进行发送时,对于顶层sequence需要区分是child sequence还是item,对于driver而言,不需要区分,拿到的都是最小颗粒度的item。
class sequencer extends uvm_sequencer;
`uvm_component_utils(sequencer)
...
endclass
class driver extends uvm_driver;
`uvm_component_utils(driver)
...
task run_phase(uvm_phase phase);
REQ tmp;
bus_trans req;
forever begin
seq_item_port.get_next_item(tmp); //流过的是最小颗粒度item
void'($cast(req,tmp));
`uvm_info("DRV",$sformatf("got a item \n %s",req.sprint()),UVM_LOW)
seq_item_port.item_done();
end
endtask
endclass发送sequence/item方法建议
- 在这段例码中,主要使用了两种方法。
- 第一个方法是针对将sequence挂载到sequencer上的应用。
uvm_sequence::start(uvm_sequencer_base sequencer, uvm_sequence_base parent_sequence = null, int this_priority=-1, bit call_pre_post = 1)
- 在使用该方法的过程中,用户首先应该指明sequencer的句柄。如果该sequence是顶部的sequence,即没有更上层的sequence嵌套它,则它可以省略对第二个参数parent_sequence的指定。
- 第三个参数的默认值-1会使得该sequence如果有parent_sequence会继承其优先级值,如果它是顶部(root) sequence,则其优先级会被自动设定为100,用户也可以自己制定优先级数值。(指定了parent suquence,当前sequence还可以访问自己的成员变量。不仅可以访问到自己挂载的sequencer,还可以访问parent sequence。组件上层可以看到底部组件的实例,底部组件也可以看到parent,sequence也是这样)
- 第四个参数建议使用默认值,这样的话uvm_ sequence:pre_body()和uvm_sequence::post_ body()两个方法会在uvm_sequence::body()的前后执行。(body一旦挂载到sequencer上,就会自动执行)
- 在上面的例子中,child_seq被嵌套到top_seq中,继而在挂载时需要指定parent_sequence; 而在test一层调用top_seq时,由于它是root sequence,则不需要再指定parent sequence,这一点用户需要注意。另外,在调用挂载sequence时,需要对这些sequence进行例化。
- 第二种发送方法是针对将item挂载到sequencer上的应用。
uvm_sequence::start_item (uvm_sequence_item item, int set_ priority=-1, uvm_sequencer_base sequencer=null);
uvm_sequencefinish_item (uvm_sequence_item item, int set_priority= -1);
- 对于start_ item()的使用,第三个参数用户需要注意是否要将item挂载到“非当前parent sequence挂载的sequencer”上面,有点绕口是吗?简单来说,如果你想将item和其parent sequence挂载到不同的sequencer上面,你就需要指定这个参数。
- 在使用这一对方法时,用户除了需要记得创建item,例如通过uvm_object:create()或者uvm_ sequence::create_item(), 还需要在它们之间完成item的随机化处理。
- 从这一点建议来看,需要读者了解到,对于一个item的完整传送,sequence要在sequencer一侧获得通过权限,才可以顺利将item发送至driver。我们可以通过拆解这些步骤得到更多的细节:
- 创建item。
- 通过start_item()方法等待获得sequencer的授权许可,其后执行parent sequence的方法pre_ do()。
- 对item进行随机化处理。
- 通过finish_item()方法在对item进行了随机化处理之后,执行parent sequence的mid_do(), 以及调用uvm_sequencer::send_request()和uvm_sequencer::wait_for_item_done() (都是sequencer的函数,但是finish_item调用)来将item发送至sequencer再完成与driver之间的握手。最后,执行了parent_sequence的post_do()。 (finish_item是sequence的函数,但是又间接调用所挂载的sequencer的函数。因为可以在finish_item可以看到sequencer句柄(m_sequencer),看不到sequencer实现,因为都是预定义的)
(两个sequence,同一时间,只有一个item获得授权许可,拿到sequencer的句柄。一旦获得授权许可,就可以调用sequencer的函数,)
发送sequence/item方法解析
这些完整的细节有两个部分需要注意。
●第一,sequence和item自身的优先级,可以决定什么时刻可以获得sequencer的授权。
●第二,读者需要意识到,parent sequence的虚方法pre_do()、mid_do()和post_ do()会发生在发送item的过程中间。
- 如果对比start()方法和start_item()/finish_item(),读者首先要分清它们面向的挂载对象是不同的。
- 在执行start()过程中,默认情况下会执行sequence的pre_body()和post_body(), 但是如果start()的参数call_pre_post=0, 那么就不会这样执行,所以在一些场景中,UVM用户会奇怪为什么pre_ body()和post_ body()没有被执行。
- pre_body()和post_body()并不是一定会被执行的,这一点同UVM的phase顺序执行是有区别的。
- 下面一段代码是对start()方法执行过程的自然代码描述(资料引用),读者可以看到它们执行的顺序关系和条件:
sub_seq.pre_start () (task)
sub_seq.pre_body () (task) if call_pre_post == 1
parent_seq.pre_do(0) (task) if parent sequence ! =nu1l
parent_seq.mid_do (this)(func) if parent_sequence ! =nu1l
sub_seq.body (task) YOUR STIMULUS CODE
parent_seq.post_do (this) (func)if parent sequence !=nu1l
sub_seq.post_body() (task) if call_pre_post == 1
sub_seq.post_start() (task)- 对于pre_do()、mid_do()、post_do()而言,子一级的sequence/item在被发送过程中会间接调用parent sequence的pre_do()等方法。
- 只要在参数传递过程中,确保子一级sequence/item与parentsequence的联系,那么这些执行过程是会按照_上面的描述依次执行的。
下面我们也给出一段start_item()/finish_item()的自然代码描述,来表示执行发送item时的相关方法执行顺序:(start_item立即返回,是因为只有一个sequence挂载)

把item发送给driver,driver然后get到item,返回item_done。sequence只有挂载了才知道sequencer的句柄。
发送序列的相关宏
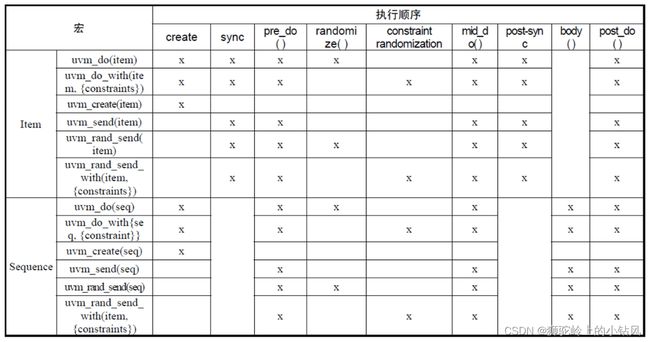
item没有body,带x的表示支持该方法。只有发送item的时候才会有优先级。sync(优先级?)。只有sequence可以调用这些宏。case中不能调用。
●正是通过几个sequence/item宏来打天下的方式,用户可以通过uvm_ do/i uvm_ do_ with来发送无论是sequence还是item。这种不区分对象是sequence还是item的方式,带来了不少便捷,但也容易引起verifier们的惰性。所以在使用它们之前,需要先了解它们背后的sequence和item各自
发送的方法。
●不同的宏,可能会包含创建对象的过程也可能不会创建对象。例如uvm_do/ uvm_do_with会 创建对象,而“uvm_ send则不会创建对象,也不会将对象做随机处理,因此要了解它们各自包含的执行内容和顺序。
●此外还有其它的宏,例如,将优先级作为参数传递的uvm_do_pri/`uvm_do_on_prio(加on,表示要把当前sequence挂载到某个sequencer上面;不加on意味着sequence挂载到的sequencer和顶层sequence挂载的sequencer是一样的)等,还有专门针对sequence的`uvm_create_seq/`uvm_do_seq/`uvm_do_seq_with等宏。
class child_seq extends uvm_sequence;
...
task body();
bus_trans req;
`uvm_create(req);
`uvm_rand_send_with(req,{data == 10;})
endtask
endclass
class top_seq extends uvm_sequence;
...
task body();
child_seq cseq;
bus_trans req;
//send child sequence via start()
`uvm_do(cseq);
//send sequence item
start_item(req);
`uvm_do_with(req,{data == 20;})
endtask
endclass最后给出的关于发送sequence/item的几点建议:
- 无论sequence处于什么层次,都应当让sequence在test结束前执行完毕。但这不是充分条件,一般而言,还应当保留出一部分时间供DUT将所有发送的激励处理完毕,进入空闲状态才可以结束测试。
- 尽量避免使用fork-join_any或者fork-join_none来控制sequence的发送顺序。因为这背后隐藏的风险是,如果用户想终止在后台运行的sequence线程而简单使用disable方式,那么就可能在不恰当的时间点上锁住sequencer。(star item需要wait for grante,一旦拿到权限没有返回,来不及给sequencer释放权限,最终导致sequencer死锁)
- 一旦sequencer被锁住而又无法释放,接下来也就无法发送其它sequence。所以如果用户想实现类似fork-join_any或者 forkjoin_none的发送顺序,还应当在使用disable前,对各个sequence线程的后台运行保持关注,尽量在发送完。item完成握手之后再终止sequence,这样才能避免sequencer被死锁的问题。
- 如果用户要使用fork-join方式,那么应当确保有方法可以让sequence线程在满足一些条件后停止发送item。否则只要有一个sequence线程无法停止,则整个fork-join无法退出。面对这种情况,仍然需要用户考虑监测合适的事件或者时间点,才能够使用disable来关闭线程。
sequencer的仲裁特性介绍
uvm_sequencer类自建了仲裁机制用来保证多个sequence在同时挂载到sequencer时,可以按照仲裁规则允许特定sequence中的item优先通过。

在实际使用中,我们可以通过uvm_sequencer::set_arbitration(UVM_SEQ_ARB_TYPE val)函数来设置仲裁模式,这里的仲裁模式UVM_ SEQ_ARB_TYPE有下面几种值可以选择:
●UVM_SEQ_ARB_FIFO: 默认模式。来自于sequences的发送请求,按照FIFO先进先出的方式被依次授权,和优先级没有关系。
●UVM_SEQ_ARB_WEIGHTED:不同sequence的发送请求,将按照它们的优先级权重随机授权。
●UVM_SEQ_ARB_RANDOM:不同的请求会被随机授权,而无视它们的抵达顺序和优先级。
●UVM_SEQ_ARB_STRICT_FIFO: 不同的请求,会按照它们的优先级以及抵达顺序来依次授权,因此与优先级和抵达时间都有关。
●UVM_SEQ_ARB_STRICT_RANDOM:不同的请求,会按照它们的最高优先级随机授权,与抵达时间无关。
●UVM_SEQ_ARB_USER: 用户可以自定义仲裁方法user_priority_arbitration()来裁定哪个
sequence的请求被优先授权。

在上面的仲裁模式中,与priority有关的模式有UVM_SEQ_ARB_WEIGHTED、UVM_SEQ_ARB_ STRICT_FIFO和UVM_SEQ_ARB_STRICT_RANDOM。
这三种模式的区别在于,UVM_SEQ_ ARB_WEIGHTED的授权可能会落到各个优先级sequence的请求上面,而UVM_ SEQ_ARB_STRICT_RANDOM则只会将授权随机安排到最高优先级的请求上面,UVM_SEQ_ARB_STRICT_FIFO则不会随机授权,而是严格按照优先级以及抵达顺序来依次授权。
没有特别的要求,用户不需要再额外自定义授权机制,因此使用UVM_SEQ_ARB_USER这一模式的情况不多见,其它模式可以满足绝大多数的仲裁需求。
鉴于sequence传送的优先级可以影响sequencer的仲裁授权,我们有必要结合sequencer的仲裁模式和sequence的优先级给出一段例码。
class bus_trans extends uvm_sequence_item;
rand int data;
...
endclass
class child_seq extends uvm_sequence;
rand int base;
...
task body();
bus_trans req;
//发送sequence时,sequence的body里面发送item时才会拿到优先级,uvm_do_with开始会wait for grant
//等待授权。每次发送item,都要作请求的授权
repeat(2) `uvm_do_with(req,{data inside {[base:base+9]}};)
endtask
endclass
class top_seq extends uvm_sequence;
...
task body();
child_seq seq1,seq2,seq3;
m_sequencer.set_arbitration(UVM_SEQ_ARB_STRICT_FIFO);
fork
`uvm_do_pri_with(seq1,500,{base == 10;}) //前两个优先级一样高
`uvm_do_pri_with(seq2,500,{base == 20;})
`uvm_do_pri_with(seq3,300,{base == 30;})
join
endtask
endclass
class sequencer extends uvm_sequencer;
...
endclass
class driver extends uvm_driver;
...
task run_phase(uvm_phase phase);
REQ tmp;
bus_trans req;
forever begin
seq_item_port.get_next_item(tmp);
void`($cast(req,tmp));
`uvm_info("DRV",$sformatf("got a item %0d from parent sequence
%s",req.data,req.get_parent_sequence().get_name()),UVM_LOW)
seq_item_port.item_done();
endtask
endclass
class env extends uvm_env;
sequencer sqr;
driver drv;
...
function void build_phase(uvm_phase phase);
sqr=sequencer::type_id::create("sqr",this);
drv=driver::type_id::create("drv",this);
endfunction
function void connect_phase(uvm phase);
drv.seq_itm_port.connect(sqr.seq_item_export);
endfunction
endclass
class test1 extends uvm_test;
env e;
...
task run_phase(uvm_phase phase);
top_seq seq;
phase.raise_objection(phase);
seq=new();
seq.start(e.sqr); //这里不支持uvm_do等宏
phase.drop_objection(phase);
endtask
endclass
//结果: seq1 seq2 seq1 seq2 seq3 seq3seq1、seq2、 seq3在同一时刻发起传送请求,通过“uvm_do_prio_with的宏,在发送sequence时可以传递优先级参数。
由于将seq1与seq2设置为同样的高优先级,而seq3设置为较低的优先级,这样在随后的UVM_SEQ_ARB_STRICT_FIFO仲裁模式下,可以从输出结果看到,按照优先级高低和传送请求时间顺序,先将seq1和seq2中的item发送完毕,随后将seq3发送完。
除了sequence遵循仲裁机制,在一些特殊情形 下,有一些sequence需要有更高权限取sequencer的授权来访问driver。例如在需要响应中断的情形下,用于处理中断的sequence应该有更高的权限来获得sequencer的授权。
sequencer的锁定机制
uvm_ sequencer提供了两种锁定机制(seq拿到item后,就可以锁定,后续item都可以拿到。只有别的sequence没有被授权时,才可以锁定),分别通过lock()和grab()方 法实现,这两种方法的区别在于:
●lock()与unlock()这一对方法可以为sequence提供排外的访问权限,但前提条件是,该sequence首先需要按照sequencer的仲裁机制获得授权。而一旦sequence获得授权,则无需担心权限被收回,只有该sequence主动解锁(unlock) 它的sequencer, 才可以释放这一锁定的权限。lock()是一 种阻塞任务,只有获得了权限,它才会返回。
●grab()与ungrab()(优先级更高)也可以为sequence提供排外的访问权限,而且它只需要在sequencer下一次授权周期时就可以无条件地获得授权。与lock方 法相比,grab方法无视同一时刻内发起传送请求的其它sequence,而唯一可以阻止它的只有已经预先获得授权的其它lock或者grab的sequence。
●这里需要注意的是,由于“解铃还须系铃人”,如果sequence使用了lock()或者grab()方法,必须在sequence结束前调用unlock()或者ungrab()方法来释放权限,否则sequencer会进入死锁状态而无法继续为其余sequence授权。
class bus_trans extends uvm_sequnece_item;
...
endclass
class child_seq extends uvm_sequence;
...
endclass
class lock_seq extends uvm_sequence;
...
task body();
bus_trans req;
#10ns;
m_sequencer.lock(this); //当前优先级默认100
`uvm_info("LOCK","get exclusive access by lock()",UVM_LOW)
repeat(3) #10ns `uvm_do_with(req,{data inside {[100:110]};})
m_sequencer.unlock(this);
endtask
endclass
class grap_seq extends uvm_sequence;
...
task body();
bus_trans req;
#20ns;
m_sequencer.grap(this);
`uvm_info("GRAB","get exclusive access by grap()",UVM_LOW)
repeat(3) #10ns `uvm_do_with(req,{data inside {[200:210]};})
m_sequencer.ungrap(this);
endtask
endclass
class top_seq extends uvm_sequence;
...
task body();
child_seq seq1,seq2,seq3;
lock_seq locks;
grap_seq graps;
m_sequencer.set_arbitration(UVM_SEQ_ARB_STRICT_FIFO);
fork
`uvm_do_pri_with(seq1,500,{base == 10;})
`uvm_do_pri_with(seq2,500,{base == 20;})
`uvm_do_pri_with(seq3,300,{base == 30;})
`uvm_do_pri(locks,300)
`uvm_do(grabs)
join
endtask
endclass
结合例码和输出结果,我们从中可以发现如下几点:
●对于sequence locks,在10ns时它跟其它几个sequence一同向sequencer发起;请求,按照仲裁模式,sequencer先后授权给seq1、seq2、seq3, 最后才授权给locks。
●而locks在获得授权之后,就可以一直享有权限而无需担心权限被sequencer收回,locks结束前,用户需要通过unlock()方法返还权限。
●对于sequence grabs,尽管他在20ns时就发起了请求权限(实际上seq1、seq2、seq3也在同一时刻发起了权限请求),而由于权限已经被locks占用,所以它也无权收回权限。 ●因此只有当locks40ns结束时,grabs才 可以在sequencer没有被锁定的状态下获得权限,而grabs在此条件下获取权限是无视同一时刻发起请求的其它sequence的。
●同样地,在grabs结束前,也应当通过ungrab()方法释放权限,防止sequencer的死锁行为。
sequence的层次化
伴随着对sequence/item发送方式的了解,读者也需要从之前4位初出茅庐的verifier梅、尤、娄和董他们的角度来看,如何完成验证的水平复用和垂直复用。
就水平复用而言,在MCDF各个子模块的验证语境中,它指的是如何利用已有资源,完成高效的激励场景创建。
就垂直复用来看,它指的是在MCDF子系统验证中,可以完成结构复用和激励场景复用两个方面。这节的垂直复用主要关注于激励场景复用。
无论是水平复用还是垂直复用,激励场景的复用很大程度.上取决于如何设计sequence,使得底层的sequence实现合理的粒度,帮助完成水平复用,进一步依托于底层激励场景,最终可以实现底层到高层的垂直复用。
本节就MCDF的实际验证场景出发,引申出以下概念来完善sequence的层次化:
●hierarchical sequence
●virtual sequence
●layering sequence
Hierarchical Sequence介绍
在验证MCDF的寄存器模块时,verifier将 SV验证环境进化到了UVM环境之后,关于测试寄存器模块的场景可以将其拆解为:
- 设置时钟和复位
- 测试通道1的控制寄存器和只读寄存器
- 测试通道2的控制寄存器和只读寄存器
- 测试通道3的控制寄存器和只读寄存器
也许读者对此会计划不同的测试环节,然而无论怎么设计,这其中的理念都不会脱离对底层测试sequence的合理设计。上面的测试场景拆解下的sequence需要挂载的都是reg_master_agent中的sequencer。这里我们给出一段代码用来说明底层sequence的设计和顶层hierarchical sequence对这些底层sequence的结构化使用。
typedef enum {CLKON,CLKOFF,RESET,WRREG,RDREG} cmd_t;
class bus_trans extends uvm_sequence_item;
rand cmd_t cmd;
rand int addr;
rand int data;
constraint cstr{
soft addr == 'h0;
soft data == 'h0;
}
...
endclass
class clk_rst_se extends uvm_sequence;
rand int freq;
...
task body();
bus_trans req;
`uvm_do_with(req,{cmd == CLKON;data == freq;})
`uvm_do_with(req,{cmd == RESET;})
endtask
endclass
class reg_test_seq extends uvm_sequence;
rand int chnl;
...
task body();
bus_trans req;
//write and read test for WR register
`uvm_do_with(req,{cmd == WRREG;addr == chnl*'h4;})
`uvm_do_with(req,{cmd == RDREG;addr == chnl*'h4;})
//read for RD register
`uvm_do_with(req,{cmd == REREG;addr == chnl*'h4+'h10;})
endtask
endclass
class top_seq extends uvm_sequence;
...
task body();
clk_rst_seq clkseq;
reg_test_seq regseq0,regseq1,regseq2;
//turn on clock with 150Mhz and assert reset
`uvm_do_with(clkseq,{freq == 150;}) //这些uvm_do的sequence和top sequence挂载的
//test the registers of channel0 //sequencer一致
`uvm_do_with(regseq0,{chnl == 0;})
//test the registers of channel1
`uvm_do_with(regseq1,{chnl == 1;})
//test the registers of channel2
`uvm_do_with(regseq2,{chnl == 2;})
endtask
endclass
class reg_master_sequencer extends uvm_sequencer;
...
endclass
class reg_master_driver extends uvm_driver;
...
task run_phase(uvm_phase phase);
REQ tmp;
bus_trans req;
forever begin
seq_item_port.get_next_item(tmp);
void`($cast(req,tmp));
`uvm_info("DRV",$sformatf("got a item \n %s",req.sprint()),UVM_LOW)
seq_item_port.item_done();
end
endtask
endclass
class reg_master_agent extends uvm_agent;
reg_master_sequencer sqr;
reg_master_driver drv;
...
function void build_phase(uvm_phase phase);
sqr==reg_master_sequencer::type_id::create("sqr",this);
drv==drv_master_sequencer::type_id::create("drv",this);
endfunction
function void connect_phase(uvm_phase phase);
drv.seq_item_port.connect(sqr.seq_item_export);
endfunction
endclass
Hierarchical Sequence解析item类bus_trans包含了几个简单的域cmd、addr和data。 在后续的
clk_rst_seq和reg_test_seq这两个底层的sequence在例化和传送item时,就通过随机bus__trans中的域来实现不同的命令和数据内容。通过这些不同数据内容的item,最终以实现不同的测试目的。在top_seq中,它就通过对clk_rst_seq和reg_ test_seq这两个element sequence进行组合和随机化赋值,最终实现了一个完整的测试场景,即先打开时钟和完成复位,其后对寄存器模块中的寄存器完成读写测试。
●所以如果将clk_rst_seq和reg_test_seq作为底层sequence,或者称之为element sequence, top_seq作为一个更高层的协调sequence,它本身也会容纳更多的sequence,并对它们进行协调和随机限制,通过将这些element sequence进行有机的调度,最终完成一个期望的测试场景。
那么这样的top_seq我们就可以称为hierarchical sequence,它内部可以包含多个sequence和item,而通过层层嵌套,最终完成测试序列的合理切分。
对于verifier而言,有了粒度合适的element sequence,他们就更容易在这些设计好的“轮子”。上面, 实现验证的加速过程。而水平复用,就非常依赖于hierarchical sequence的实现。
如何区别接下来讲到的virtual sequence,毕竟它们两者之间的共同点就是对于各个sequence的协调。它们的不同在于,hierarchical sequence面对的对象是同一个sequencer,即hierarchical sequence本身也会挂载到sequencer上面,而对于virtual sequence而言,它内部不同的sequence可以允许面向不同的sequencer种类。
virtual sequence介绍
伴随着底层模块的验证周期趋于尾声,在MCDF子系统验证环境集成过程中,完成了前期的结构垂直复用,就需要考虑如何复用各个模块的element sequence和hierarchical sequence。
对于更上层的环境,可想而知的是,顶层的测试序列要协调的不再只是面向一个sequencer的sequence群,而是要面向多个sequencer的sequence群。那么面向不同sequencer的sequence群落在组织以后,如何分别挂接到不同的sequencer上呢?
我们在之前介绍的sequence,都是面向单一的sequencer, 因此挂载也很简单;即通过uvm_ sequence::start()来挂载root sequence,而在内部的child sequence则可以通过宏“uvm_do来实现。
如果将各个模块环境的element sequence和hierarchical sequence都作为可以复用的sequence资源,那么就需要一个可以容纳各个sequence的容器来承载它们,同时也需要一个合适的routing sequencer来组织不同结构中的sequencer,这样的sequence和sequencer分别称之为virtual sequence和virtual sequencer。
就之前的sequence和sequencer而言,它们之间的差别在于:
●virtual sequence可以承载不同目标sequencer的sequence群落,而组织协调这些sequence的方式则类似于高层次的hierarchical sequence。virtualsequence一般只会挂载到virtual sequencer上面。 ●virtual sequencer与普通的sequencer相比有着很大的不同,它们起到了桥接其它sequencer的作用,即virtual sequencer是一个链接所有底层sequencer句柄的地方,它是一个中心化的路由器。
●同时virtual sequencer本身并不会传送item数据对象,因此virtual sequencer不需要与任何的driver进行TLM连接。所以UVM用户需要在顶层的connect阶段,做好virtual sequencer中各个sequencer句柄与底层sequencer实体对象的一一对接, 避免句柄悬空。

接下来的示例用来表示element sequence/hierarchical sequence与virtual sequence的关系,以及底层sequencer与virtual sequencer的联系,同时也说明virtual sequence与virtual sequencer的挂载方法。
typedef class mcdf_virtual_sequencer;
//底层sequence定义,分属不同sequencer
//clk_rst_seq
//reg_cfg_seq
//data_trans_seq
//fmt_slv_cfg_seq
class mcdf_normal_seq extends uvm_sequence;
`uvm_object_utils(mcdf_normal_seq)
//uvm_declare_p_sequencer完成两步:定义成员变量类型p_sequencer;
//$cast(p_sequencer,m_sequencer);m_sequencer、p_sequencer都指向virtual sequencer
//要想访问virtual sequencer(子类类型)里面的成成员变量,只能通过子类句柄;m_sequencer作为父类
//无法直接访问到子类成员里面的对象,所以做类型转换
`uvm_declare_p_sequencer(mcdf_virtual_sequencer) //mcdf_virtual_sequencer子类句柄
...
task body();
clk_rst_seq clk_seq;
reg_cfg_seq cfg_seq;
data_trans_seq data_seq;
fmt_slv_cfg_seq fmt_seq;
//配置formatter slave agent
`uvm_do_on(fmt_seq,p_sequencer.fmt_sqr)
//打开时钟并复位
`uvm_do_on(clk_seq,p_sequencer.cr_sqr)
//传送channel数据包
fork
`uvm_do_on(data_seq,p_sequencer.chnl_sqr0)
`uvm_do_on(data_seq,p_sequencer.chnl_sqr1)
`uvm_do_on(data_seq,p_sequencer.chnl_sqr2)
join
endtask
endclass
//这里用的uvm_do_on,而hierarchy sequence用的uvm_do,因为它默认挂载到top sequence
//挂载的sequencer。virtual sequence要挂载到virtual sequencer上,底层通过sequencer句柄挂载到
//不同sequencer上
//m_sequencer是uvm_sequencer,父类句柄;p_sequencer是子类句柄,通过前面的宏声明。p_sequencer/
//是新鲜定义的(这里的类型是mcdf_virtual_sequencer),m_sequencer是预定义好的
//virtual sequence:用宏创建sequencer;包含不同sequence;用uvm_do_on//子一级的sequencer和agent定义
//cr_master_sequencer | cr_master_agent
//reg_master_sequencer | reg_maseter_agent
//chnl_master_sequencer | chnl_master_agent
//fmt_slave_sequencer | fmt_slave_agent
class mcdf_virtual sequencer extends uvm_sequencer;
cr_master_sequencer cr_sqr;
reg_master_sequencer reg_sqr;
chnl_master_sequencer chnl_sqr0;
chnl_master_sequencer chnl_sqr1;
chnl_master_sequencer chnl_sqr2;
fmt_slave_sequencer fmt_sqr;
`uvm_component_utils(mcdf_virtual_sequencer)
function new(string name,uvm_component parent);
super.new(name,parent);
endfunction
endclassclass mcdf_env extends uvm_env;
cr_master_agent cr_agent;
reg_master_agent reg_agent;
chnl_master_agent chnl_agt0;
chnl_master_agent chnl_agt1;
chnl_master_agent chnl_agt2;
fmt_slave_agent fmt_agt;
mcdf_virtutal_sequencer virt_sqr; //virtual sequencer也要声明创建,因为也是组件
`uvm_component_utils(mcdf_env)
function new(string name,uvm_component parent);
super.new(name,parent);
endfunction
function void build_phase(uvm_phase phase);
cr_agt = cr_master_agent::type_id::create("cr_agt",this);
reg_agt = reg_master_agent::type_id::create("reg_agt",this);
chnl_agt0 = chnl_master_agent::type_id::create("chnl_agt".this);
chnl_agt1 = chnl_master_agent::type_id::create("chnl_agt1".this);
chnl_agt2 = chnl_master_agent::type_id::create("chnl_agt2".this);
fmt_agt = fmt_slave_agent::type_id::create("fmt_agt",this);
virt_sqr = mcdf_virtual_sequencer::type_id::create("virt_sqr",this);
endfunction
function void connect_phase(uvm_phase phase);
//virtual sequencer connection
//but no any TLM connection with sequencers
//把各个底层的sequencer句柄分别传递virtual sequencer里面的句柄
virt_sqr.cr_sqr=cr_agt.sqr;
virt_sqr.reg_sqr=reg_agt.sqr;
virt_sqr.chnl_sqr0=chnl_agt0.sqr;
virt_sqr.chnl_sqr1=chnl_agt1.sqr;
virt_sqr.chnl_sqr2=chnl_agt2.sqr;
endfunction
endclass:mcdf_env
class test1 extends uvm_test;
mcdf_env e;
...
task run_phase(uvm_phase phase);
mcdf_normal_seq seq;
phase.raise_objection(phase);
seq=new();
seq.start(e.virt_sqr); //virtual sequence挂载到virtual sequence
phase.drop_objection(phase);
endtask
endclass:test1
- 对于virtual sequence mcdf_normal_seq而言,它可以承载各个子模块环境的element sequence,而通过最后挂载的virtual sequencer mcdf_virtual_sequencer中的各个底层sequencer句柄,各个element sequence可以分别挂载到对应的底层sequencer上。
- 尽管在最后test1中,将virtual sequence挂载到了virtual sequencer上面,但是这种挂载的根本目的是为了提供给virtual sequence一个中心化的sequencer路由,而借助在virtual sequence mcdf_normal_seq中使用了宏`uvm_declare_p_sequencer, 使得virtual sequence可以使用声明后的成员变量p_sequencer (类型为mcdf_virtual_sequencer) ,来进一步回溯到virtual sequencer内部的各个sequencer句柄。
- 在这里使用`uvm_declare_p_sequencer是较为方便的,因为这个宏在后台,可以新创建一个p_sequencer变量,而将m_sequencer的默认变量(uvm_ sequencer_base类型)通过动态转换,变为类型为mcdf_virtual sequencer的p_sequencer。
只要声明的挂载sequencer类型正确,用户可以通过这个宏,完成方便的类型转换,因此才可以通过p_ sequencer索引到在mcdf_virtual_ sequencer中声明的各个sequencer句柄。
初学者需要理解virtual sequence的协调作用,virtual sequencer的路由作用,以及在顶层中需要完成virtual sequencer同底层sequencer的连接,并最终在test层实现virtual sequence挂载到virtual sequencer上。
这种中心化的协调方式,使得顶层环境在场景创建和激励控制方面更加得心应手,而且在代码后期维护中,测试场景的可读性也得到了提高。
Virtual Sequence建议
UVM初学者在一 开始学习virtual sequence和virutal sequencer时容易出现编译错误和运行时句柄悬空的错误,还有一些概念上的偏差,在这里路桑给出一些建议供读者参考:
● 需要区分virtual sequence同其它普通sequence (element sequence、hierarchical sequence)。
●需要区分virtual sequencer同其它底层负责传送数据对象的sequencer。
●在virtual sequence中记得使用宏“uvm_ declare_p_sequencer来创建正确类型的p_sequencer变量, 方便接下来各个目标sequencer的索引。
●在顶层环境中记得创建virtual sequencer, 并且完成virtual sequencer中各个sequencer句柄与底层sequencer的跨层次链接。
Layering Sequence介绍
●如果我们在构建更加复杂的协议总线传输,例如PCle,USB3.0等,那么通过一个单一的传输层级会对以后的激励复用、上层控制不那么友好。
●对于这种更深层次化的数据传输,在实际中无论是VIP还是自开发的环境,都倾向于通过若干抽象层次的sequence群落来模拟协议层次。
●通过层次化的sequence可以分别构建transaction layer、 transport layer和physical layer等从高抽象级到低抽象级的transaction转化。这种层次化的sequence构建方式,我们称之为layering sequence。
●例如在进行寄存器级别的访问操作,其需要通过transport layer转化,最终映射为具体的总线传输。
我们将通过一段简单的例码,来阐述layer sequence的核心,突出sequence层级转换的思想。
(比如,这里的寄存器模型的读写指令通过寄存器模型转换为总线item。reg item转换为bus item)
typedef enum {CLKON,CLKOFF,RESET,WRREG,RDREG} phy_cmd_t;
typedef enum {FREQ_LOW_TRANS,FREQ_MED_TRANS,FREQ_HIGH_TRANS} layer_cmd_t;
class bus_trans extends uvm_sequence_item;
rand phy_cmd_t cmd;
rand int addr;
rand int data;
constraint cstr{
soft addr == 'h0;
soft data == 'h0;
}
...
endclass
class packet_seq extends uvm_sequence;
rand int len;
rand int addr;
rand int data[];
rand phy_cmd_t cmd;
constraint cstr{
soft len inside {[30:50]};
soft addr [31:16] == 'hFF00;
data.size() == len;
}
...
task body();
bus_trans req;
foreach(data[i])
`uvm_do_with(req, {cmd == local::cmd;
addr == local::addr;
data == local::data[i];})
endtask
endclassclass layer_trans extends uvm_sequence_item //更抽象
rand layer_cmd_t layer_cmd;
rand int pkt_len;
rand int pkt_idle;
constraint cstr {
soft pkt_len inside {[10:20]}};
layer_cmd == FREQ_LOW_TRANS -> pkt_idle inside {[300:400]};
layer_cmd == FREQ_MED_TRANS -> pkt_idle inside {[100:200]};
layer_cmd == FREQ_HIGH_TRANS -> pkt_idle inside {[20:40]};
...
endclass
class adapter_seq extends uvm_sequence; //转化层
`uvm_object_utils(adapter_seq)
`uvm_declare_p_sequencer(phy_master_sequencer)
...
task body();
layer_trans trans;
packer_seq pkt;
forever begin
p_sequencer.up_sqr.get_next_item(req); //与p_sequencer相连的上层sequencer句柄
void'($cast(trans,req)); //get_next_item是sequencer的方法,driver是因为port
repeat(trans.pkt_len)begin //与sequencer的import相连,通过port调用sequencer方法
`uvm_do(pkt) //高抽象维度转化为低抽象维度pkt
delay(trans.pkt_idle);
end
p_sequencer.up_sqr.item_done(); //握手
end
endtask
virtual task delay(int delay);
...
endtask
endclassclass top_seq extends uvm_sequence; //高抽象级
...
task body();
layer_trans trans;
`uvm_do_with(trans,{layer_cmd == FREQ_LOW_TRANS;})
`uvm_do_with(trans,{layer_cmd == FREQ_HIGH_TRANS;})
endtask
endclass
class layerin_sequencer extends uvm_sequencer;
...
endclass
class phy_master_sequencer extends uvm_sequencer;
layering_sequencer up_sqr; //句柄
...
endclassclass phy_master_driver extends uvm_driver;
...
task run_phase(uvm_phase phase);
REQ tmp;
bus_trans req;
forever begin
seq_item_port.get_next_item(tmp);
void`($cast(req,tmp));
`uvm_info("DRV",$sformatf("got a item \n %s",req.sprint()),UVM_LOW)
seq_item_port.item_done();
end
endtask
endclass
class phy_master_agent extends uvm_agent;
phy_master_sequencer sqr;
phy_master_driver drv;
...
function void build_phase(uvm_phase phase);
sqr=phy_master_sequencer::type_id::create("sqr",this);
drv=phy_master_driver::type_id::create("drv",this);
endfunction
function void connect_phase(uvm_phase phase);
drv.seq_item_port.connect(sqr.seq_item_export);
endfunction
endclassclass test1 extends uvm_test;
layering_sequencer layer_sqr; //例化的两个
phy_master_agent phy_agt;
...
function void build_phase(uvm_phase phase);
layer_sqr = layering_sequencer::type_id::create("layer_sqr",this);
phy_agt = phy_master::create::type_id::create("phy_agt",this);
endfunction
function void connect_phase(uvm_phase phase);
phy_agt.sqr.up_sqr=layer_sqr; //句柄传递过去
endfunction
task run_phase(uvm_phase phase);
top_seq seq;
adapter_seq adapter;
phase.raise_objection(phase);
seq=new();
adapter=new();
fork
adapter.start(phy_agt.sqr); //挂载,这里adapter里面用到forever,所以用fork
join_none //join_none,让其在后台运行
seq.start(layer_sqr); //挂载,phy_seq不用挂载,产生的过程
phase.drop_objection(phase);
endtask
endclassLayering Sequence包含高抽象的item、低抽象的item、中间作转换的sequence。

我们可以得出一些关于如何实现sequencer layer协议转换的方法:
●无论有多少抽象层次的transaction类定义,都应该有对应的sequencer作为transaction的路由通道。例如layer_sequencer和phy_master_sequencer分别作为layer_trans和bus_trans的通道。
●在各个抽象级的sequencer中,需要有相应的转换方法,将从高层次的transaction从高层次的sequencer获取,继而转换为低层次的transaction,最终通过低层次的sequencer发送出去。例如adapter_ seq负责从layer_sequencer获取layer_trans,再将其转换为phy_master_sequencer一侧对应的sequence或者transaction,最后将其从phy_master_sequencer发送出去。
●这些adaption sequence应该运行在低层次的sequencer一侧,作为“永动” 的sequence时刻做好服务准备,从高层次的sequencer获取transaction,通过转化将其从低层次的sequencer一侧送出。例如上面在test1中,adapter sequence通过adapter.start(phy_ agt.sqr)挂载到低层次的sequencer,做好转换transaction并将其发送的准备。
●至于需要定义多少个层次的transaction item类,上面的例子仅仅是为了说明layer sequence的一般方法,对于实际中的层次定义和transaction item定义,我们还需要具体问题具体处理。 ●我们可以看到各个sequence类别对应的sequencer,同时也有sequence item发送和转换的方向。经过转化,最终高层次的transaction内容可以落实到低层次的protocol agent和physical interface上面。
●例码中没有给出读回路的处理,即从physical interface穿过physical agent,最终抵达layering sequencer的通信。在实际中我们可以通过相同路径返回response item来实现。
●也可以通过不同层次的monitor采集response transaction,最终通过monitor转化抽象级返回item的方式来实现。
●至于选择哪一种反馈回路,这与底层agent反馈回路的实现方式有关,即如果原有方式通过driver一侧返回response,那么我们建议继续在该反馈链条上进行从低级transaction到高级transaction的转化,如果原有方式通过monitor一侧返回response,那么我们也建议创建对应的高层次monitor,实现抽象层次转化。