【天梯赛 - L1练习集】刷题(80 / 80)(二刷+完结)
目录
L1-002 打印沙漏 (20 分)
✓ L1-003 个位数统计 (15 分)
✓ *L1-006 连续因子 (20 分)
✓ L1-007 念数字 (10 分)
✓ *L1-009 N个数求和 (20 分)
✓ L1-011 A-B (20 分)
✓ L1-016 查验身份证 (15 分)
✓ L1-017 到底有多二 (15 分)
✓ L1-019 谁先倒 (15 分)
✓ *L1-020 帅到没朋友 (20 分)
✓ L1-025 正整数A+B (15 分)
✓ L1-027 出租 (20 分)
✓*L1-030 一帮一 (15 分)
✓L1-032 Left-pad (20 分)
✓L1-033 出生年 (15 分)
✓L1-034 点赞 (20 分)
✓L1-035 情人节 (15 分)
strcmp()函数
strcpy()函数
✓L1-039 古风排版 (20 分)
✓L1-040 最佳情侣身高差 (10 分)
✓*L1-043 阅览室 (20 分)
✓L1-044 稳赢 (15 分)
✓*L1-046 整除光棍 (20 分) 除法套路
✓除法套路 - 求A除以B的商与余数
✓L1-048 矩阵A乘以B (15 分)
✓*L1-049 天梯赛座位分配 (20 分)
✓*L1-050 倒数第N个字符串 (15 分) 不会
✓*L1-054 福到了 (15 分)
✓L1-056 猜数字 (20 分)
fabs和abs的区别
✓*L1-058 6翻了 (15 分)
✓*L1-059 敲笨钟 (20 分)
✓L1-071 前世档案 (20 分) 满二叉树
✓L1-072 刮刮彩票 (20 分)
✓L1-078 吉老师的回归 (15 分)
strstr( ) 函数
✓L1-080 乘法口诀数列 (20 分)
L1-002 打印沙漏 (20 分)
要求你写个程序把给定的符号打印成沙漏的形状。例如给定17个“*”,要求按下列格式打印
***** *** * *** *****所谓“沙漏形状”,是指每行输出奇数个符号;各行符号中心对齐;相邻两行符号数差2;符号数先从大到小顺序递减到1,再从小到大顺序递增;首尾符号数相等。
给定任意N个符号,不一定能正好组成一个沙漏。要求打印出的沙漏能用掉尽可能多的符号。
输入格式:
输入在一行给出1个正整数N(≤1000)和一个符号,中间以空格分隔。
输出格式:
首先打印出由给定符号组成的最大的沙漏形状,最后在一行中输出剩下没用掉的符号数。
输入样例:
19 *输出样例:
***** *** * *** ***** 2
#include
int main()
{
int n,i,j,res,max;
char ch;
scanf("%d %c",&n,&ch);
//求最大层数
for(i=1;;i++)
if(2*i*i-1 > n) //通过规律知上半部分星号总数为层数平方即i*i
//则两部分星号总数是2*i*i再减去多算的一个星号
{
max=i-1; //因为跳出循环时 正好比要求的max多一 因此要减一
break;
}
res=n-(2*max*max-1); //剩余星星数
//打印上半部分
int kong=0;
for(i=max;i>=1;i--) //控制层数
{
for(j=0;j
✓ L1-003 个位数统计 (15 分)
给定一个 k 位整数 N=dk−110k−1+⋯+d1101+d0 (0≤di≤9, i=0,⋯,k−1, dk−1>0),请编写程序统计每种不同的个位数字出现的次数。例如:给定 N=100311,则有 2 个 0,3 个 1,和 1 个 3。
输入格式:
每个输入包含 1 个测试用例,即一个不超过 1000 位的正整数 N。
输出格式:
对 N 中每一种不同的个位数字,以 D:M 的格式在一行中输出该位数字 D 及其在 N 中出现的次数 M。要求按 D 的升序输出。
输入样例:
100311
输出样例:
0:2
1:3
3:1
这种统计数字的问题,用数学取余的方法并不好做,用字符串的方法比较好
#include
#define N 1001
int main()
{
int i=0,j;
char a[N];
int num[10]={0};
scanf("%s",a);
while(a[i]!='\0')
{
for(j=0;j<10;j++)
if(a[i]-'0'==j) //a[i]-'0'指将数字字符转为数字
num[j]++;
i++;
}
for(i=0;i<10;i++)
if(num[i]!=0)
printf("%d:%d\n",i,num[i]);
return 0;
}
✓ *L1-006 连续因子 (20 分)
一个正整数 N 的因子中可能存在若干连续的数字。例如 630 可以分解为 3×5×6×7,其中 5、6、7 就是 3 个连续的数字。给定任一正整数 N,要求编写程序求出最长连续因子的个数,并输出最小的连续因子序列。
输入格式:
输入在一行中给出一个正整数 N(1
输出格式:
首先在第 1 行输出最长连续因子的个数;然后在第 2 行中按 因子1*因子2*……*因子k 的格式输出最小的连续因子序列,其中因子按递增顺序输出,1 不算在内。
输入样例:
630
输出样例:
3
5*6*7
#include
#include
int main()
{
int i,j,n,max=0,t,first;
scanf("%d",&n);
for(i=2;imax)
{
max=j-i;
first=i;//记录第一个因子
}
}
if(max==0) printf("1\n%d",n); //质数情况
else
{
printf("%d\n",max);
printf("%d",first);
for(i=1;i
✓ L1-007 念数字 (10 分)
输入一个整数,输出每个数字对应的拼音。当整数为负数时,先输出fu字。十个数字对应的拼音如下:
0: ling
1: yi
2: er
3: san
4: si
5: wu
6: liu
7: qi
8: ba
9: jiu
输入格式:
输入在一行中给出一个整数,如:1234。
提示:整数包括负数、零和正数。
输出格式:
在一行中输出这个整数对应的拼音,每个数字的拼音之间用空格分开,行末没有最后的空格。如 yi er san si。
输入样例:
-600
输出样例:
fu liu ling ling
#include
#include
int main()
{
char *num[10]={"ling","yi","er","san","si","wu","liu","qi","ba","jiu"};
char n;
int flag=0;
while((n=getchar())!='\n') //一个一个字符输入
{
if(flag) printf(" ");
flag=1;
if(n=='-') printf("fu");
else printf("%s",num[n-'0']);
}
}
✓ *L1-009 N个数求和 (20 分)
本题的要求很简单,就是求N个数字的和。麻烦的是,这些数字是以有理数分子/分母的形式给出的,你输出的和也必须是有理数的形式。
输入格式:
输入第一行给出一个正整数N(≤100)。随后一行按格式a1/b1 a2/b2 ...给出N个有理数。题目保证所有分子和分母都在长整型范围内。另外,负数的符号一定出现在分子前面。
输出格式:
输出上述数字和的最简形式 —— 即将结果写成整数部分 分数部分,其中分数部分写成分子/分母,要求分子小于分母,且它们没有公因子。如果结果的整数部分为0,则只输出分数部分。
输入样例1:
5
2/5 4/15 1/30 -2/60 8/3
输出样例1:
3 1/3
输入样例2:
2
4/3 2/3
输出样例2:
2
输入样例3:
3
1/3 -1/6 1/8
输出样例3:
7/24
这道题从学长那块学到好多东西,比如欧几里得求最大公约数,还有分数相加的快速算法
这种分数的题挺考验数学知识和编程结合的,以后找一些分数相关编程的题多练练
#include
typedef struct
{
int fz;
int fm;
}FEN;
int gcd(int x,int y)//欧几里得最大公约数
{
return y?gcd(y,x%y):x;
}
void simply(int *fz,int *fm)//约分
{
int t;
t=gcd(*fz,*fm);
*fz/=t;
*fm/=t;
}
int main()
{
FEN f[101];
int n,i;
int fenzi=0,fenmu=1;
scanf("%d",&n);
for(i=0;i
关于第二个for循环,做了个图解,昨天在这然了近两个小时,其实就是简单的分子乘对方分母,然后分母相乘,分子相加的简单操作

✓ L1-011 A-B (20 分)
本题要求你计算A−B。不过麻烦的是,A和B都是字符串 —— 即从字符串A中把字符串B所包含的字符全删掉,剩下的字符组成的就是字符串A−B。
输入格式:
输入在2行中先后给出字符串A和B。两字符串的长度都不超过104,并且保证每个字符串都是由可见的ASCII码和空白字符组成,最后以换行符结束。
输出格式:
在一行中打印出A−B的结果字符串。
输入样例:
I love GPLT! It's a fun game!
aeiou
输出样例:
I lv GPLT! It's fn gm!
方法一:标记法
#include
#include
#define N 10001
int main()
{
char a[N],b[N],c[1010]; //这个c[256]作为字母标记数组
int i;
gets(a);
gets(b);
for(i=0;i
方法二:字符串对比,相同字符不输出法
#include
#include
#define N 10001
int main()
{
int flag;
char a[N],b[N];
gets(a);
gets(b);
for(int i=0;i
✓ L1-016 查验身份证 (15 分)
一个合法的身份证号码由17位地区、日期编号和顺序编号加1位校验码组成。校验码的计算规则如下:
首先对前17位数字加权求和,权重分配为:{7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2};然后将计算的和对11取模得到值Z;最后按照以下关系对应Z值与校验码M的值:
Z:0 1 2 3 4 5 6 7 8 9 10
M:1 0 X 9 8 7 6 5 4 3 2
现在给定一些身份证号码,请你验证校验码的有效性,并输出有问题的号码。
输入格式:
输入第一行给出正整数N(≤100)是输入的身份证号码的个数。随后N行,每行给出1个18位身份证号码。
输出格式:
按照输入的顺序每行输出1个有问题的身份证号码。这里并不检验前17位是否合理,只检查前17位是否全为数字且最后1位校验码计算准确。如果所有号码都正常,则输出All passed。
输入样例1:
4
320124198808240056
12010X198901011234
110108196711301866
37070419881216001X
输出样例1:
12010X198901011234
110108196711301866
37070419881216001X
输入样例2:
2
320124198808240056
110108196711301862
输出样例2:
All passed
#include
int main()
{
int n,i,j,sum,flag=1,cnt=0;
char a[101][17];
int quan[17]={7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2};
char check[11]={'1','0','X','9','8','7','6','5','4','3','2'};
scanf("%d",&n);
for(i=0;i
✓ L1-017 到底有多二 (15 分)
一个整数“犯二的程度”定义为该数字中包含2的个数与其位数的比值。如果这个数是负数,则程度增加0.5倍;如果还是个偶数,则再增加1倍。例如数字-13142223336是个11位数,其中有3个2,并且是负数,也是偶数,则它的犯二程度计算为:3/11×1.5×2×100%,约为81.82%。本题就请你计算一个给定整数到底有多二。
输入格式:
输入第一行给出一个不超过50位的整数N。
输出格式:
在一行中输出N犯二的程度,保留小数点后两位。
输入样例:
-13142223336
输出样例:
81.82%
一开始没读懂,以为题目给的×2指的是2这个数,但其实是指数是偶数了话,倍数增加一倍,也就是2倍。主要考察字符串,特别是负数字符串时,数字实际位数会比真实位数多一,所以要减一。
还有:%输出时,前要加%!
#include
#include
int main()
{
char a[51];
int cnt=0,l,i;
double bei=1.0,s;
scanf("%s",a);
l=strlen(a);
for(i=0;i
✓ L1-019 谁先倒 (15 分)
划拳是古老中国酒文化的一个有趣的组成部分。酒桌上两人划拳的方法为:每人口中喊出一个数字,同时用手比划出一个数字。如果谁比划出的数字正好等于两人喊出的数字之和,谁就输了,输家罚一杯酒。两人同赢或两人同输则继续下一轮,直到唯一的赢家出现。
下面给出甲、乙两人的酒量(最多能喝多少杯不倒)和划拳记录,请你判断两个人谁先倒。
输入格式:
输入第一行先后给出甲、乙两人的酒量(不超过100的非负整数),以空格分隔。下一行给出一个正整数N(≤100),随后N行,每行给出一轮划拳的记录,格式为:
甲喊 甲划 乙喊 乙划
其中喊是喊出的数字,划是划出的数字,均为不超过100的正整数(两只手一起划)。
输出格式:
在第一行中输出先倒下的那个人:A代表甲,B代表乙。第二行中输出没倒的那个人喝了多少杯。题目保证有一个人倒下。注意程序处理到有人倒下就终止,后面的数据不必处理。
输入样例:
1 1
6
8 10 9 12
5 10 5 10
3 8 5 12
12 18 1 13
4 16 12 15
15 1 1 16
输出样例:
A
1
这题莫得难度,我放这只想记录一下一次AC的快乐哈哈哈
#include
int main()
{
int A,B,n,i,j,sum=0;
int da=0,db=0; //记录a,b喝的酒杯数
int a[101][4];
scanf("%d %d",&A,&B);
scanf("%d",&n);
for(i=0;iA)
{
printf("A\n%d",db);
break;
}else if(db>B)
{
printf("B\n%d",da);
break;
}
}
return 0;
}
✓ *L1-020 帅到没朋友 (20 分)
当芸芸众生忙着在朋友圈中发照片的时候,总有一些人因为太帅而没有朋友。本题就要求你找出那些帅到没有朋友的人。
输入格式:
输入第一行给出一个正整数N(≤100),是已知朋友圈的个数;随后N行,每行首先给出一个正整数K(≤1000),为朋友圈中的人数,然后列出一个朋友圈内的所有人——为方便起见,每人对应一个ID号,为5位数字(从00000到99999),ID间以空格分隔;之后给出一个正整数M(≤10000),为待查询的人数;随后一行中列出M个待查询的ID,以空格分隔。
注意:没有朋友的人可以是根本没安装“朋友圈”,也可以是只有自己一个人在朋友圈的人。虽然有个别自恋狂会自己把自己反复加进朋友圈,但题目保证所有K超过1的朋友圈里都至少有2个不同的人。
输出格式:
按输入的顺序输出那些帅到没朋友的人。ID间用1个空格分隔,行的首尾不得有多余空格。如果没有人太帅,则输出No one is handsome。
注意:同一个人可以被查询多次,但只输出一次。
输入样例1:
3
3 11111 22222 55555
2 33333 44444
4 55555 66666 99999 77777
8
55555 44444 10000 88888 22222 11111 23333 88888
输出样例1:
10000 88888 23333
输入样例2:
3
3 11111 22222 55555
2 33333 44444
4 55555 66666 99999 77777
4
55555 44444 22222 11111
输出样例2:
No one is handsome
错误代码&&复杂思路:
思路很简单,就是用index数组记录出现的id,这题烦就烦在:一个空格格式问题,一个是特殊情况(一个人朋友圈只有一个人,那么他也是个孤独的帅哥,输出时也要带上他)。我现在知道最后一个点的问题出在哪里了,但是不知道为什么index不记录,先放这,等我思考思考
(反思:因为之前m=1的话,lone就=1了,但下一个lone没重置,也就不记录了;
其次是,index[ a[ j ] ]=0是错的,像一下这种样例就不对,不能一棒子打死,55555这个人前面出现两次,如果最后一下给他直接标记清零就不对了,应改成index[ a[ j ] ]--;)
输入:
3
3 11111 22222 55555
4 55555 66666 99999 77777
1 55555
错误输出:
1
55555
#include
int main()
{
int n,i,j,m,x,id,flag=1,cnt=0,lone=0;
int a[1001];
int index[99999]={0};
scanf("%d",&n);
for(i=0;i
简化AC代码:
#include
int main()
{
int n,i,j,m,x,id,flag=1;
int a[1001];//数组用来存储每个朋友圈的id
int index[100001]={0};
scanf("%d",&n);
for(i=0;i
✓ L1-025 正整数A+B (15 分)
题的目标很简单,就是求两个正整数A和B的和,其中A和B都在区间[1,1000]。稍微有点麻烦的是,输入并不保证是两个正整数。
输入格式:
输入在一行给出A和B,其间以空格分开。问题是A和B不一定是满足要求的正整数,有时候可能是超出范围的数字、负数、带小数点的实数、甚至是一堆乱码。
注意:我们把输入中出现的第1个空格认为是A和B的分隔。题目保证至少存在一个空格,并且B不是一个空字符串。
输出格式:
如果输入的确是两个正整数,则按格式A + B = 和输出。如果某个输入不合要求,则在相应位置输出?,显然此时和也是?。
输入样例1:
123 456
输出样例1:
123 + 456 = 579
输入样例2:
22. 18
输出样例2:
? + 18 = ?
输入样例3:
-100 blabla bla...33
#include
#include
int num(char a[],int l)//把字符换成数字
{
int i,sum=0;
for(i=0;i'9') f1=0;
for(i=0;i'9') f2=0;
if(num(a,la)<1||num(a,la)>1000) f1=0; //数字在[1,1000],超范围算乱码
if(num(b,lb)<1||num(b,lb)>1000) f2=0;
if(f1&&f2) printf("%s + %s = %d",a,b,num(a,la)+num(b,lb));
else if(f1&&f2==0) printf("%s + ? = ?",a);
else if(f1==0&&f2) printf("? + %s = ?",b);
else printf("? + ? = ?");
return 0;
}
✓ L1-027 出租 (20 分)
一时间网上一片求救声,急问这个怎么破。其实这段代码很简单,index数组就是arr数组的下标,index[0]=2 对应 arr[2]=1,index[1]=0 对应 arr[0]=8,index[2]=3 对应 arr[3]=0,以此类推…… 很容易得到电话号码是18013820100。
本题要求你编写一个程序,为任何一个电话号码生成这段代码 —— 事实上,只要生成最前面两行就可以了,后面内容是不变的。
输入格式:
输入在一行中给出一个由11位数字组成的手机号码。
输出格式:
为输入的号码生成代码的前两行,其中arr中的数字必须按递减顺序给出。
输入样例:
18013820100
输出样例:
int[] arr = new int[]{8,3,2,1,0};
int[] index = new int[]{3,0,4,3,1,0,2,4,3,4,4};
上次刷这题还借鉴了别人,这次直接自己写,代码还更短嘿嘿嘿,l1的题就是多练,多找规律
#include
int main()
{
int i,j,cnt=0;
char a[11];//存储电话号码
int sum[10]={0};//记录电话里有的数字1~9
int arr[11]={0};
int index[11]={0};
scanf("%s",a);
for(i=0;i<11;i++)
sum[a[i]-'0']++;
for(i=9;i>=0;i--)//题目的arr是从大到小,因此倒置遍历
if(sum[i]!=0)
arr[cnt++]=i;
for(i=0;i<11;i++) //电话号码一个一个与arr比对,位置存入index
for(j=0;j
✓*L1-030 一帮一 (15 分)
“一帮一学习小组”是中小学中常见的学习组织方式,老师把学习成绩靠前的学生跟学习成绩靠后的学生排在一组。本题就请你编写程序帮助老师自动完成这个分配工作,即在得到全班学生的排名后,在当前尚未分组的学生中,将名次最靠前的学生与名次最靠后的异性学生分为一组。
输入格式:
输入第一行给出正偶数N(≤50),即全班学生的人数。此后N行,按照名次从高到低的顺序给出每个学生的性别(0代表女生,1代表男生)和姓名(不超过8个英文字母的非空字符串),其间以1个空格分隔。这里保证本班男女比例是1:1,并且没有并列名次。
输出格式:
每行输出一组两个学生的姓名,其间以1个空格分隔。名次高的学生在前,名次低的学生在后。小组的输出顺序按照前面学生的名次从高到低排列。
输入样例:
8
0 Amy
1 Tom
1 Bill
0 Cindy
0 Maya
1 John
1 Jack
0 Linda
输出样例:
Amy Jack
Tom Linda
Bill Maya
Cindy John
学到一招 flag数组,这样标记就能一对一啦!
因为男女比例是1:1,所以只要给前一半的学生找异性后一半的同桌就行。
#include
typedef struct
{
int gender;
char name[10];
}stu;
int main()
{
int n,i,j,flag[51]={0};//flag数组 用于一个一个标记 更加方便
stu s[51];
scanf("%d",&n);
for(i=0;i=n/2;j--)//后一半
if(!flag[j]&&s[i].gender!=s[j].gender)//如果没配对且性别不同就配对在一起
{
printf(" %s\n",s[j].name);
flag[j]=1;//已配对的把他标记 下次就不会重复配对
break; //配对好了就不用继续遍历
}
}
return 0;
}
✓L1-032 Left-pad (20 分)
根据新浪微博上的消息,有一位开发者不满NPM(Node Package Manager)的做法,收回了自己的开源代码,其中包括一个叫left-pad的模块,就是这个模块把javascript里面的React/Babel干瘫痪了。这是个什么样的模块?就是在字符串前填充一些东西到一定的长度。例如用*去填充字符串GPLT,使之长度为10,调用left-pad的结果就应该是******GPLT。Node社区曾经对left-pad紧急发布了一个替代,被严重吐槽。下面就请你来实现一下这个模块。
输入格式:
输入在第一行给出一个正整数N(≤104)和一个字符,分别是填充结果字符串的长度和用于填充的字符,中间以1个空格分开。第二行给出原始的非空字符串,以回车结束。
输出格式:
在一行中输出结果字符串。
输入样例1:
15 _
I love GPLT
输出样例1:
____I love GPLT
输入样例2:
4 *
this is a sample for cut
输出样例2:
cut
#include
#include
int main()
{
int n,i,l;
char c,a[40000];
scanf("%d %c",&n,&c);
getchar(); //吞掉上面scanf的回车
gets(a);
l=strlen(a);
if(n>l)
{
for(i=0;i
✓L1-033 出生年 (15 分)
以上是新浪微博中一奇葩贴:“我出生于1988年,直到25岁才遇到4个数字都不相同的年份。”也就是说,直到2013年才达到“4个数字都不相同”的要求。本题请你根据要求,自动填充“我出生于y年,直到x岁才遇到n个数字都不相同的年份”这句话。
输入格式:
输入在一行中给出出生年份y和目标年份中不同数字的个数n,其中y在[1, 3000]之间,n可以是2、或3、或4。注意不足4位的年份要在前面补零,例如公元1年被认为是0001年,有2个不同的数字0和1。
输出格式:
根据输入,输出x和能达到要求的年份。数字间以1个空格分隔,行首尾不得有多余空格。年份要按4位输出。注意:所谓“n个数字都不相同”是指不同的数字正好是n个。如“2013”被视为满足“4位数字都不同”的条件,但不被视为满足2位或3位数字不同的条件。
输入样例1:
1988 4
输出样例1:
25 2013
输入样例2:
1 2
输出样例2:
0 0001
#include
#include
int main()
{
int year,n,cnt;
int a[4];
scanf("%d %d",&year,&n);
int y=year;
while(cnt!=n)
{
cnt=1; //计数器要重置
a[0]=y/1000;
a[1]=y/100%10;
a[2]=y/10%10;
a[3]=y%10;
if(a[0]!=a[1]&&a[0]!=a[2]&&a[0]!=a[3]) cnt++;
if(a[1]!=a[2]&&a[1]!=a[3]) cnt++;
if(a[2]!=a[3]) cnt++;
if(cnt!=n) y++;
}
printf("%d %04d",y-year,y);
return 0;
}
✓L1-034 点赞 (20 分)
微博上有个“点赞”功能,你可以为你喜欢的博文点个赞表示支持。每篇博文都有一些刻画其特性的标签,而你点赞的博文的类型,也间接刻画了你的特性。本题就要求你写个程序,通过统计一个人点赞的纪录,分析这个人的特性。
输入格式:
输入在第一行给出一个正整数N(≤1000),是该用户点赞的博文数量。随后N行,每行给出一篇被其点赞的博文的特性描述,格式为“K F1⋯FK”,其中1≤K≤10,Fi(i=1,⋯,K)是特性标签的编号,我们将所有特性标签从1到1000编号。数字间以空格分隔。
输出格式:
统计所有被点赞的博文中最常出现的那个特性标签,在一行中输出它的编号和出现次数,数字间隔1个空格。如果有并列,则输出编号最大的那个。
输入样例:
4
3 889 233 2
5 100 3 233 2 73
4 3 73 889 2
2 233 123
输出样例:
233 3
#include
int main()
{
int i,j,n,m,dz,index[1001]={0};
scanf("%d",&n);
for(i=0;i=index[max]) //注意这里是>= 如果只是> 并列的就不输出了
max=i; //如果有并列,则输出编号最大的那个
printf("%d %d",max,index[max]);
return 0;
}
✓L1-035 情人节 (15 分)
以上是朋友圈中一奇葩贴:“2月14情人节了,我决定造福大家。第2个赞和第14个赞的,我介绍你俩认识…………咱三吃饭…你俩请…”。现给出此贴下点赞的朋友名单,请你找出那两位要请客的倒霉蛋。
输入格式:
输入按照点赞的先后顺序给出不知道多少个点赞的人名,每个人名占一行,为不超过10个英文字母的非空单词,以回车结束。一个英文句点.标志输入的结束,这个符号不算在点赞名单里。
输出格式:
根据点赞情况在一行中输出结论:若存在第2个人A和第14个人B,则输出“A and B are inviting you to dinner...”;若只有A没有B,则输出“A is the only one for you...”;若连A都没有,则输出“Momo... No one is for you ...”。
输入样例1:
GaoXZh
Magi
Einst
Quark
LaoLao
FatMouse
ZhaShen
fantacy
latesum
SenSen
QuanQuan
whatever
whenever
Potaty
hahaha
.
输出样例1:
Magi and Potaty are inviting you to dinner...
输入样例2:
LaoLao
FatMouse
whoever
.
输出样例2:
FatMouse is the only one for you...
输入样例3:
LaoLao
.
输出样例3:
Momo... No one is for you ...
strcmp()函数
strcmp ( str1, str2 )
- str1 -- 要进行比较的第一个字符串。
- str2 -- 要进行比较的第二个字符串。
该函数返回值如下:
- 如果返回值小于 0,则表示 str1 小于 str2。
- 如果返回值大于 0,则表示 str1 大于 str2。
- 如果返回值等于 0,则表示 str1 等于 str2。
strcpy()函数
strcpy ( str1, str2 )
将str2的内容复制到str1中
#include
#include
int main()
{
int cnt=0;
char a[15],p1[15],p2[15];
while(scanf("%s",a)&&strcmp(a,".")!=0)
{
cnt++;
if(cnt==2) strcpy(p1,a);
if(cnt==14) strcpy(p2,a);
}
if(cnt>=14) printf("%s and %s are inviting you to dinner...",p1,p2);
else if(cnt>=2) printf("%s is the only one for you...",p1);
else printf("Momo... No one is for you ...");
return 0;
}
✓L1-039 古风排版 (20 分)
中国的古人写文字,是从右向左竖向排版的。本题就请你编写程序,把一段文字按古风排版。
输入格式:
输入在第一行给出一个正整数N(<100),是每一列的字符数。第二行给出一个长度不超过1000的非空字符串,以回车结束。
输出格式:
按古风格式排版给定的字符串,每列N个字符(除了最后一列可能不足N个)。
输入样例:
4
This is a test case
输出样例:
asa T
st ih
e tsi
ce s
#include
#include
int main()
{
int n,i,j,cnt=0;
char a[1001];
char s[101][101];
scanf("%d",&n);
getchar(); //吞掉scanf的空格
gets(a);
int l=strlen(a);
int lie; //求列数
if(l%n!=0) lie=l/n+1;
else lie=l/n;
for(j=lie-1;j>=0;j--)
for(i=0;i
✓L1-040 最佳情侣身高差 (10 分)
专家通过多组情侣研究数据发现,最佳的情侣身高差遵循着一个公式:(女方的身高)×1.09 =(男方的身高)。如果符合,你俩的身高差不管是牵手、拥抱、接吻,都是最和谐的差度。
下面就请你写个程序,为任意一位用户计算他/她的情侣的最佳身高。
输入格式:
输入第一行给出正整数N(≤10),为前来查询的用户数。随后N行,每行按照“性别 身高”的格式给出前来查询的用户的性别和身高,其中“性别”为“F”表示女性、“M”表示男性;“身高”为区间 [1.0, 3.0] 之间的实数。
输出格式:
对每一个查询,在一行中为该用户计算出其情侣的最佳身高,保留小数点后2位。
输入样例:
2
M 1.75
F 1.8
输出样例:
1.61
1.96
#include
typedef struct
{
char gender;
double h;
}peo;
int main()
{
int n,i;
peo p[11];
scanf("%d",&n);
for(i=0;i
✓*L1-043 阅览室 (20 分)
天梯图书阅览室请你编写一个简单的图书借阅统计程序。当读者借书时,管理员输入书号并按下S键,程序开始计时;当读者还书时,管理员输入书号并按下E键,程序结束计时。书号为不超过1000的正整数。当管理员将0作为书号输入时,表示一天工作结束,你的程序应输出当天的读者借书次数和平均阅读时间。
注意:由于线路偶尔会有故障,可能出现不完整的纪录,即只有S没有E,或者只有E没有S的纪录,系统应能自动忽略这种无效纪录。另外,题目保证书号是书的唯一标识,同一本书在任何时间区间内只可能被一位读者借阅。
输入格式:
输入在第一行给出一个正整数N(≤10),随后给出N天的纪录。每天的纪录由若干次借阅操作组成,每次操作占一行,格式为:
书号([1, 1000]内的整数) 键值(S或E) 发生时间(hh:mm,其中hh是[0,23]内的整数,mm是[0, 59]内整数)
每一天的纪录保证按时间递增的顺序给出。
输出格式:
对每天的纪录,在一行中输出当天的读者借书次数和平均阅读时间(以分钟为单位的精确到个位的整数时间)。
输入样例:
3
1 S 08:10
2 S 08:35
1 E 10:00
2 E 13:16
0 S 17:00
0 S 17:00
3 E 08:10
1 S 08:20
2 S 09:00
1 E 09:20
0 E 17:00
输出样例:
2 196
0 0
1 60
#include
int main()
{
int i,n,t,num,h,m,cnt=0;
scanf("%d",&n);
char c; //输入S/E
int book[1001][2]={0}; //借出则标记为1,归还标记为0
//0存是否借出,1存借出时间
for(i=0;i1) printf("%d %.0f\n",cnt,(float)t/cnt);
}
return 0;
}
✓L1-044 稳赢 (15 分)
现要求你编写一个稳赢不输的程序,根据对方的出招,给出对应的赢招。但是!为了不让对方输得太惨,你需要每隔K次就让一个平局。
输入格式:
输入首先在第一行给出正整数K(≤10),即平局间隔的次数。随后每行给出对方的一次出招:ChuiZi代表“锤子”、JianDao代表“剪刀”、Bu代表“布”。End代表输入结束,这一行不要作为出招处理。
输出格式:
对每一个输入的出招,按要求输出稳赢或平局的招式。每招占一行。
输入样例:
2
ChuiZi
JianDao
Bu
JianDao
Bu
ChuiZi
ChuiZi
End
输出样例:
Bu
ChuiZi
Bu
ChuiZi
JianDao
ChuiZi
Bu
#include
#include
int main()
{
int n,cnt=0;
char c[10];
scanf("%d",&n);
while(scanf("%s",c))
{
if(strcmp(c,"End")==0) break;
if(cnt==n)
{
puts(c);//puts()自带换行
cnt=0;
}
else
{
if(strcmp(c,"ChuiZi")==0) printf("Bu\n");
else if(strcmp(c,"JianDao")==0) printf("ChuiZi\n");
else if(strcmp(c,"Bu")==0) printf("JianDao\n");
cnt++;
}
}
return 0;
}
✓*L1-046 整除光棍 (20 分) 除法套路
这里所谓的“光棍”,并不是指单身汪啦~ 说的是全部由1组成的数字,比如1、11、111、1111等。传说任何一个光棍都能被一个不以5结尾的奇数整除。比如,111111就可以被13整除。 现在,你的程序要读入一个整数x,这个整数一定是奇数并且不以5结尾。然后,经过计算,输出两个数字:第一个数字s,表示x乘以s是一个光棍,第二个数字n是这个光棍的位数。这样的解当然不是唯一的,题目要求你输出最小的解。
提示:一个显然的办法是逐渐增加光棍的位数,直到可以整除x为止。但难点在于,s可能是个非常大的数 —— 比如,程序输入31,那么就输出3584229390681和15,因为31乘以3584229390681的结果是111111111111111,一共15个1。
输入格式:
输入在一行中给出一个不以5结尾的正奇数x(<1000)。
输出格式:
在一行中输出相应的最小的s和n,其间以1个空格分隔。
输入样例:
31
输出样例:
3584229390681 15
#include
int main()//就是除法的套路,综合复习一下
{
int x,yv=1,num=0,cnt=0;
scanf("%d",&x);
while(num
✓除法套路 - 求A除以B的商与余数
计算A/B的商和余数,其中被除数A是不超过1000位的非负整数,除数B是一个不超过229的任意非负整数。要求你输出商Q和余数R。
输入格式:
输入在一行中依次给出 A 和 B,中间以空格分隔。
输出格式:
在一行中依次输出 Q 和 R,中间以空格分隔。
输入样例:
1234567891234567893 23
输出样例:
53676864836285560 13
#include
#include
int main()
{
char a[1001]={'\0'};
int B,i,t=0,flag=0;//flag表示已经除过了
scanf("%s %d",a,&B);
for(i=0;i=B)
{
printf("%d",t/B);
t%=B;
flag=1;
}
}
if(flag) printf(" %d",t);
else printf("0 %d",t);
return 0;
}
✓L1-048 矩阵A乘以B (15 分)
给定两个矩阵A和B,要求你计算它们的乘积矩阵AB。需要注意的是,只有规模匹配的矩阵才可以相乘。即若A有Ra行、Ca列,B有Rb行、Cb列,则只有Ca与Rb相等时,两个矩阵才能相乘。
输入格式:
输入先后给出两个矩阵A和B。对于每个矩阵,首先在一行中给出其行数R和列数C,随后R行,每行给出C个整数,以1个空格分隔,且行首尾没有多余的空格。输入保证两个矩阵的R和C都是正数,并且所有整数的绝对值不超过100。
输出格式:
若输入的两个矩阵的规模是匹配的,则按照输入的格式输出乘积矩阵AB,否则输出Error: Ca != Rb,其中Ca是A的列数,Rb是B的行数。
输入样例1:
2 3
1 2 3
4 5 6
3 4
7 8 9 0
-1 -2 -3 -4
5 6 7 8
输出样例1:
2 4
20 22 24 16
53 58 63 28
输入样例2:
3 2
38 26
43 -5
0 17
3 2
-11 57
99 68
81 72
输出样例2:
Error: 2 != 3
#include
int main()
{
int a[101][101],b[101][101],c[201][201]; //注意这里存储相乘结果的矩阵范围要大
int ra,ca,rb,cb;
int i,j,k;
scanf("%d %d",&ra,&ca);
for(i=0;i
✓*L1-049 天梯赛座位分配 (20 分)
天梯赛每年有大量参赛队员,要保证同一所学校的所有队员都不能相邻,分配座位就成为一件比较麻烦的事情。为此我们制定如下策略:假设某赛场有 N 所学校参赛,第 i 所学校有 M[i] 支队伍,每队 10 位参赛选手。令每校选手排成一列纵队,第 i+1 队的选手排在第 i 队选手之后。从第 1 所学校开始,各校的第 1 位队员顺次入座,然后是各校的第 2 位队员…… 以此类推。如果最后只剩下 1 所学校的队伍还没有分配座位,则需要安排他们的队员隔位就坐。本题就要求你编写程序,自动为各校生成队员的座位号,从 1 开始编号。
输入格式:
输入在一行中给出参赛的高校数 N (不超过100的正整数);第二行给出 N 个不超过10的正整数,其中第 i 个数对应第 i 所高校的参赛队伍数,数字间以空格分隔。
输出格式:
从第 1 所高校的第 1 支队伍开始,顺次输出队员的座位号。每队占一行,座位号间以 1 个空格分隔,行首尾不得有多余空格。另外,每所高校的第一行按“#X”输出该校的编号X,从 1 开始。
输入样例:
3
3 4 2
输出样例:
#1
1 4 7 10 13 16 19 22 25 28
31 34 37 40 43 46 49 52 55 58
61 63 65 67 69 71 73 75 77 79
#2
2 5 8 11 14 17 20 23 26 29
32 35 38 41 44 47 50 53 56 59
62 64 66 68 70 72 74 76 78 80
82 84 86 88 90 92 94 96 98 100
#3
3 6 9 12 15 18 21 24 27 30
33 36 39 42 45 48 51 54 57 60
变态c++:
#include
using namespace std;
const int N = 110;
int n, cnt, school, m = 1;
//res 是高校数 rate是控制间隔的
struct node
{
int team;
vectorv;
}a[N];
int main()
{
cin >> n;
school = n;
cnt = n == 1 ? 2 : 1;//如果只有一个学校,间隔是2
for (int i = 0; i < n; i++)//输入每个高校的队伍数
cin >> a[i].team;
while (school)
{
for (int i = 0; i < n; i++) //高校数
{
if (a[i].v.size() < a[i].team*10)
{
if (a[i].v.size() == a[i].team*10-1) school--;
a[i].v.push_back(m); //m是座位号
m += cnt;
if (school == 1) cnt = 2; //如果只剩一个高校 则隔排就坐
}
}
}
for (int i = 0; i < n; i++)
{
cout << '#' << i + 1 << endl;
for (int j = 0; j < a[i].v.size(); j++)
cout << a[i].v[j] << ((j + 1) % 10 ? " " : "\n");
}
return 0;
}
c代码: 我悟了 我终于懂了 不容易啊啊啊啊啊啊啊 希望有一天我也能自己编出来
#include
typedef struct
{
int team;//每个高校的队伍数量
int peo;//已排好座位的人数
int sit[101];//排位
}p;
int main()
{
p a[110];
int n, i, j, m = 1;
scanf("%d", &n);//输入高校数
int cnt = n==1 ? 2:1;//如果只有一所学校,间隔而坐
for (i=1; i<=n; i++)
scanf("%d", &a[i].team);
int school = n;//这里要重新设个变量 不能直接用n n的值不能改变
while (school)
{
//按顺序给高校排座位:for用来切换高校
for (i=1; i<=n; i++)
{
if (a[i].peo < a[i].team * 10)//如果该高校人没排完
{
if (a[i].peo == a[i].team * 10-1) school--;//处理完一个高校
a[i].sit[a[i].peo++] = m; //记录编号
m += cnt;//控制间隔
if (school == 1) cnt=2;//如果只剩一所学校 则间隔变为2
}
}
}
for (i = 1; i <= n; i++)
{
printf("#%d\n", i);
for (j=0; j
✓*L1-050 倒数第N个字符串 (15 分) 不会
给定一个完全由小写英文字母组成的字符串等差递增序列,该序列中的每个字符串的长度固定为 L,从 L 个 a 开始,以 1 为步长递增。例如当 L 为 3 时,序列为 { aaa, aab, aac, ..., aaz, aba, abb, ..., abz, ..., zzz }。这个序列的倒数第27个字符串就是 zyz。对于任意给定的 L,本题要求你给出对应序列倒数第 N 个字符串。
输入格式:
输入在一行中给出两个正整数 L(2 ≤ L ≤ 6)和 N(≤105)。
输出格式:
在一行中输出对应序列倒数第 N 个字符串。题目保证这个字符串是存在的。
输入样例:
3 7417
输出样例:
pat
#include
#include
int main()
{
int l,n,cnt=0,i;
char a[10];
scanf("%d %d",&l,&n);
n=pow(26,l)-n;
while(l--)
{
a[cnt++]=n%26+'a';
n=n/26;
}
for(i=cnt-1;i>=0;i--)
printf("%c",a[i]);
}
#include
int main()
{
int l,n,i;
int a[10];
scanf("%d %d",&l,&n);
n=n-1;
for(i=l-1;i>=0;i--)
{
a[i]=n%26;
n=n/26;
}
for(i=0;i
✓*L1-054 福到了 (15 分)
“福”字倒着贴,寓意“福到”。不论到底算不算民俗,本题且请你编写程序,把各种汉字倒过来输出。这里要处理的每个汉字是由一个 N × N 的网格组成的,网格中的元素或者为字符 @ 或者为空格。而倒过来的汉字所用的字符由裁判指定。
输入格式:
输入在第一行中给出倒过来的汉字所用的字符、以及网格的规模 N (不超过100的正整数),其间以 1 个空格分隔;随后 N 行,每行给出 N 个字符,或者为 @ 或者为空格。
输出格式:
输出倒置的网格,如样例所示。但是,如果这个字正过来倒过去是一样的,就先输出bu yong dao le,然后再用输入指定的字符将其输出。
输入样例 1:
$ 9
@ @@@@@
@@@ @@@
@ @ @
@@@ @@@
@@@ @@@@@
@@@ @ @ @
@@@ @@@@@
@ @ @ @
@ @@@@@
输出样例 1:
$$$$$ $
$ $ $ $
$$$$$ $$$
$ $ $ $$$
$$$$$ $$$
$$$ $$$
$ $ $
$$$ $$$
$$$$$ $
输入样例 2:
& 3
@@@
@
@@@
输出样例 2:
bu yong dao le
&&&
&
&&&
啊啊啊啊啊啊字符串单个字符 都怪大一上册c的字符串这章没好好听!!!
#include
int main()
{
char c,a[100][100];
int n,i,j,flag=1;
scanf("%c %d",&c,&n);
getchar(); //接收scanf的空格以防被下面接收
for(i=0;i=0;i--)
{
for(j=n-1;j>=0;j--)
printf("%c",a[i][j]);
printf("\n");
}
return 0;
}
✓L1-056 猜数字 (20 分)
一群人坐在一起,每人猜一个 100 以内的数,谁的数字最接近大家平均数的一半就赢。本题就要求你找出其中的赢家。
输入格式:
输入在第一行给出一个正整数N(≤104)。随后 N 行,每行给出一个玩家的名字(由不超过8个英文字母组成的字符串)和其猜的正整数(≤ 100)。
输出格式:
在一行中顺序输出:大家平均数的一半(只输出整数部分)、赢家的名字,其间以空格分隔。题目保证赢家是唯一的。
输入样例:
7
Bob 35
Amy 28
James 98
Alice 11
Jack 45
Smith 33
Chris 62
输出样例:
22 Amy
fabs和abs的区别
fabs的参数为double型,返回值也是double型
abs的参数为int型,返回值也是int型
abs是求一个整数的绝对值,而fabs是求一个实数的绝对值
#include
#include
typedef struct
{
char name[10];
int x;
}p;
int main()
{
p peo[10001];
int n,i,index=0,sum=0; //index需要初始化 如果不初始化 会段错误
scanf("%d",&n);
for(i=0;ifabs(average-peo[i].x))
{
min=fabs(average-peo[i].x);
index=i;
}
}
printf("%d %s",average,peo[index].name);
return 0;
}
✓*L1-058 6翻了 (15 分)
“666”是一种网络用语,大概是表示某人很厉害、我们很佩服的意思。最近又衍生出另一个数字“9”,意思是“6翻了”,实在太厉害的意思。如果你以为这就是厉害的最高境界,那就错啦 —— 目前的最高境界是数字“27”,因为这是 3 个 “9”!
本题就请你编写程序,将那些过时的、只会用一连串“6666……6”表达仰慕的句子,翻译成最新的高级表达。
输入格式:
输入在一行中给出一句话,即一个非空字符串,由不超过 1000 个英文字母、数字和空格组成,以回车结束。
输出格式:
从左到右扫描输入的句子:如果句子中有超过 3 个连续的 6,则将这串连续的 6 替换成 9;但如果有超过 9 个连续的 6,则将这串连续的 6 替换成 27。其他内容不受影响,原样输出。
输入样例:
it is so 666 really 6666 what else can I say 6666666666
输出样例:
it is so 666 really 9 what else can I say 27
strlen( )不会将'\0'计算在内
#include
#include
int main()
{
int i,j,cnt=0;
char s[1001];
gets(s);
for(i=0;i<=strlen(s);i++) //i<=strlen(s)遍历到'\0'
{
if(s[i]=='6')//如果遇到6 计数 要不然输出其他字符
{
cnt++;
}
else{
if(cnt>9) printf("27");
else if(cnt>3) printf("9");
else
{
for(j=0;j
✓*L1-059 敲笨钟 (20 分)
微博上有个自称“大笨钟V”的家伙,每天敲钟催促码农们爱惜身体早点睡觉。为了增加敲钟的趣味性,还会糟改几句古诗词。其糟改的方法为:去网上搜寻压“ong”韵的古诗词,把句尾的三个字换成“敲笨钟”。例如唐代诗人李贺有名句曰:“寻章摘句老雕虫,晓月当帘挂玉弓”,其中“虫”(chong)和“弓”(gong)都压了“ong”韵。于是这句诗就被糟改为“寻章摘句老雕虫,晓月当帘敲笨钟”。
现在给你一大堆古诗词句,要求你写个程序自动将压“ong”韵的句子糟改成“敲笨钟”。
输入格式:
输入首先在第一行给出一个不超过 20 的正整数 N。随后 N 行,每行用汉语拼音给出一句古诗词,分上下两半句,用逗号 , 分隔,句号 . 结尾。相邻两字的拼音之间用一个空格分隔。题目保证每个字的拼音不超过 6 个字符,每行字符的总长度不超过 100,并且下半句诗至少有 3 个字。
输出格式:
对每一行诗句,判断其是否压“ong”韵。即上下两句末尾的字都是“ong”结尾。如果是压此韵的,就按题面方法糟改之后输出,输出格式同输入;否则输出 Skipped,即跳过此句。
输入样例:
5
xun zhang zhai ju lao diao chong, xiao yue dang lian gua yu gong.
tian sheng wo cai bi you yong, qian jin san jin huan fu lai.
xue zhui rou zhi leng wei rong, an xiao chen jing shu wei long.
zuo ye xing chen zuo ye feng, hua lou xi pan gui tang dong.
ren xian gui hua luo, ye jing chun shan kong.
输出样例:
xun zhang zhai ju lao diao chong, xiao yue dang lian qiao ben zhong.
Skipped
xue zhui rou zhi leng wei rong, an xiao chen jing qiao ben zhong.
Skipped
Skipped
#include
#include
int main()
{
int n,i,j,len,index=0,flag1,flag2,cnt;
char s[101];
scanf("%d",&n);
getchar();
for(i=0;i=0;j--)//倒序遍历 记录第三个位置空格之后的下标
{
if(s[j]==' ') cnt++;
if(cnt==3)
{
index=j+1;
break;
}
}
for(j=0;j
✓L1-071 前世档案 (20 分) 满二叉树
网络世界中时常会遇到这类滑稽的算命小程序,实现原理很简单,随便设计几个问题,根据玩家对每个问题的回答选择一条判断树中的路径(如下图所示),结论就是路径终点对应的那个结点。
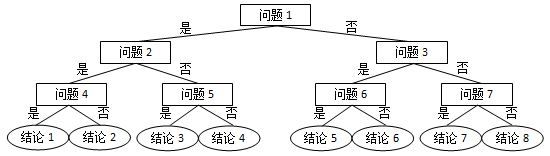
现在我们把结论从左到右顺序编号,编号从 1 开始。这里假设回答都是简单的“是”或“否”,又假设回答“是”对应向左的路径,回答“否”对应向右的路径。给定玩家的一系列回答,请你返回其得到的结论的编号。
输入格式:
输入第一行给出两个正整数:N(≤30)为玩家做一次测试要回答的问题数量;M(≤100)为玩家人数。
随后 M 行,每行顺次给出玩家的 N 个回答。这里用 y 代表“是”,用 n 代表“否”。
输出格式:
对每个玩家,在一行中输出其对应的结论的编号。
输入样例:
3 4
yny
nyy
nyn
yyn
输出样例:
3
5
6
2
数学规律法:

#include
#include
int main()
{
int i,j,q,n,res;
char s[101];
scanf("%d %d",&q,&n);
getchar();
for(i=0;i
✓L1-072 刮刮彩票 (20 分)
每次游戏玩家会拿到一张彩票,上面会有 9 个数字,分别为数字 1 到数字 9,数字各不重复,并以 3×3 的“九宫格”形式排布在彩票上。
在游戏开始时能看见一个位置上的数字,其他位置上的数字均不可见。你可以选择三个位置的数字刮开,这样玩家就能看见四个位置上的数字了。最后玩家再从 3 横、3 竖、2 斜共 8 个方向中挑选一个方向,方向上三个数字的和可根据下列表格进行兑奖,获得对应数额的金币。
数字合计
获得金币
数字合计
获得金币
6
10,000
16
72
7
36
17
180
8
720
18
119
9
360
19
36
10
80
20
306
11
252
21
1,080
12
108
22
144
13
72
23
1,800
14
54
24
3,600
15
180
现在请你写出一个模拟程序,模拟玩家的游戏过程。
输入格式:
输入第一部分给出一张合法的彩票,即用 3 行 3 列给出 0 至 9 的数字。0 表示的是这个位置上的数字初始时就能看见了,而不是彩票上的数字为 0。
第二部给出玩家刮开的三个位置,分为三行,每行按格式 x y 给出玩家刮开的位置的行号和列号(题目中定义左上角的位置为第 1 行、第 1 列。)。数据保证玩家不会重复刮开已刮开的数字。
最后一部分给出玩家选择的方向,即一个整数: 1 至 3 表示选择横向的第一行、第二行、第三行,4 至 6 表示纵向的第一列、第二列、第三列,7、8分别表示左上到右下的主对角线和右上到左下的副对角线。
输出格式:
对于每一个刮开的操作,在一行中输出玩家能看到的数字。最后对于选择的方向,在一行中输出玩家获得的金币数量。
输入样例:
1 2 3
4 5 6
7 8 0
1 1
2 2
2 3
7
输出样例:
1
5
6
180
#include
int main()
{
int i,j,x,y,m,sum=0;
int a[4][4];
int s[25]={0,0,0,0,0,0,10000,36,720,360,80,252,108,72,54,180,72,180,119,36,306,1080,144,1800,3600};
for(i=1;i<=3;i++)
for(j=1;j<=3;j++)
{
scanf("%d",&a[i][j]);
sum+=a[i][j];
if(a[i][j]==0)
{
x=i;
y=j;
}
}
a[x][y]=45-sum;
for(i=0;i<3;i++)
{
scanf("%d %d",&x,&y);
printf("%d\n",a[x][y]);
}
sum=0;
scanf("%d",&m);
if(m<=3)
{
for(i=1;i<=3;i++)
sum+=a[m][i];
}else if(m>=4&&m<=6)
{
for(i=1;i<=3;i++)
sum+=a[i][m-3];
}else if(m==7)
{
for(i=1;i<=3;i++)
sum+=a[i][i];
}else
{
for(i=1;i<=3;i++)
sum+=a[i][4-i];
}
printf("%d",s[sum]);
return 0;
}
✓L1-078 吉老师的回归 (15 分)
曾经在天梯赛大杀四方的吉老师决定回归天梯赛赛场啦!
为了简化题目,我们不妨假设天梯赛的每道题目可以用一个不超过 500 的、只包括可打印符号的字符串描述出来,如:Problem A: Print "Hello world!"。
众所周知,吉老师的竞赛水平非常高超,你可以认为他每道题目都会做(事实上也是……)。因此,吉老师会按照顺序看题并做题。但吉老师水平太高了,所以签到题他就懒得做了(浪费时间),具体来说,假如题目的字符串里有 qiandao 或者 easy(区分大小写)的话,吉老师看完题目就会跳过这道题目不做。
现在给定这次天梯赛总共有几道题目以及吉老师已经做完了几道题目,请你告诉大家吉老师现在正在做哪个题,或者吉老师已经把所有他打算做的题目做完了。
提醒:天梯赛有分数升级的规则,如果不做签到题可能导致团队总分不足以升级,一般的选手请千万不要学习吉老师的酷炫行为!
输入格式:
输入第一行是两个正整数 N,M (1≤M≤N≤30),表示本次天梯赛有 N 道题目,吉老师现在做完了 M 道。
接下来 N 行,每行是一个符合题目描述的字符串,表示天梯赛的题目内容。吉老师会按照给出的顺序看题——第一行就是吉老师看的第一道题,第二行就是第二道,以此类推。
输出格式:
在一行中输出吉老师当前正在做的题目对应的题面(即做完了 M 道题目后,吉老师正在做哪个题)。如果吉老师已经把所有他打算做的题目做完了,输出一行 Wo AK le。
输入样例 1:
5 1
L1-1 is a qiandao problem.
L1-2 is so...easy.
L1-3 is Easy.
L1-4 is qianDao.
Wow, such L1-5, so easy.
输出样例 1:
L1-4 is qianDao.
输入样例 2:
5 4
L1-1 is a-qiandao problem.
L1-2 is so easy.
L1-3 is Easy.
L1-4 is qianDao.
Wow, such L1-5, so!!easy.
输出样例 2:
Wo AK le
strstr( ) 函数
strstr(str1,str2) 函数用于判断字符串str2是否是str1的子串。
如果是,则该函数返回str2在str1中首次出现的地址,否则,返回NULL。
#include
#include
int main()
{
int n,m,flag=1;
char s[1000];
scanf("%d %d",&n,&m);
getchar();
while(n--)
{
gets(s);
if(strstr(s,"easy")||strstr(s,"qiandao")) continue;//如果遇到简单题直接跳过 做题次数不减
else
{
if(m==0) //如果做题次数完了 输出在看的题 改变flag
{
puts(s);
flag=0;
}
m--;//做题次数减一
}
}
if(flag) printf("Wo AK le");
return 0;
}
✓L1-080 乘法口诀数列 (20 分)
本题要求你从任意给定的两个 1 位数字 a1 和 a2 开始,用乘法口诀生成一个数列 {an},规则为从 a1 开始顺次进行,每次将当前数字与后面一个数字相乘,将结果贴在数列末尾。如果结果不是 1 位数,则其每一位都应成为数列的一项。
输入格式:
输入在一行中给出 3 个整数,依次为 a1、a2 和 n,满足 0≤a1,a2≤9,0
输出格式:
在一行中输出数列的前 n 项。数字间以 1 个空格分隔,行首尾不得有多余空格。
输入样例:
2 3 10
输出样例:
2 3 6 1 8 6 8 4 8 4
样例解释:
数列前 2 项为 2 和 3。从 2 开始,因为 2×3=6,所以第 3 项是 6。因为 3×6=18,所以第 4、5 项分别是 1、8。依次类推…… 最后因为第 6 项有 6×8=48,对应第 10、11 项应该是 4、8。而因为只要求输出前 10 项,所以在输出 4 后结束。
#include
int main()
{
int i,t,n,a[1001],cnt=2;
scanf("%d %d %d",&a[0],&a[1],&n);
for(i=0;cnt