【论文阅读笔记】(2022 ECCV)CMD: Self-supervised 3D Action Representation Learning with Cross-modal Mutual Di
写在前面
我又回来啦~前段时间忙毕业论文,停更了好久【dbq】。现在论文终于送审出去啦~撒花花~
后面会继续读博当科研狗吧,努力继续看论文更新 blog,耶✌
有小伙伴提建议弄中文版的解读,咱努力哈,一般是英文,时间有富余的话会用中文再总结一遍哒~
今天可以有中文版~
CMD: Self-supervised 3D Action Representation Learning with Cross-modal Mutual Distillation
(2022 ECCV)
Yunyao Mao, Wengang Zhou, Zhenbo Lu, Jiajun Deng, and Houqiang Li*
Notes
Paper Link:https://arxiv.org/pdf/2208.12448.pdf
Code Link:https://github.com/maoyunyao/CMD
1. Contribution
作者提出了一个跨模态互蒸馏(Cross-modal Mutual Distillation,CMD)的自监督学习框架。
其中,模态之间进行的是双向知识蒸馏(bidirectional knowledge distillation);
蒸馏的知识(knowledge)是样本和其他样本的相似度分布(the neighboring similarity distribution)
在蒸馏的过程中,为老师(teacher)和学生(student)模型设置不同的参数,目的是稳定蒸馏的过程,同时保证传输具有高置信度的知识。

2. Method
2.1 Overview
如图所示,CMD 框架包含两个模块:一个是单模态的对比学习(Single-modal Contrastive Learning,SCL),一个是跨模态互蒸馏(Cross-modal Mutual Distillation,CMD)。该框架既挖掘特定于单模态的特征,又利用多模态之间的交互来挖掘模态之间丰富的互补信息。
给定骨架点视频序列的不同模态(如 joint、bone 和 motion),先用 SCL 模块学习特定于单模态的特征。同时,在 CMD 模块里,将样本与其相近样本之间的相似度分布作为知识,通过减小模态之间知识的 KL 散度来达到知识蒸馏的目的。
注意,SCL 和 CMD 两个模块是同时训练的。

2.2 单模态对比学习 SCL
在该模块里,作者使用的是 MoCo v2 的对比学习框架。
具体来说,对每个样本  进行两次数据增强,得到
进行两次数据增强,得到 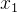 ,
, 。 和 之间互为正样本,Memory Bank 中的样本为 和 的负样本。
。 和 之间互为正样本,Memory Bank 中的样本为 和 的负样本。
训练时,key encoder(teacher model)不用梯度更新其模型的参数,而是用 query encoder (student model)的参数来进行动量更新,即
![]()
损失函数用的是 InfoNCE.
2.3 跨模态互蒸馏 CMD
模态 A 的某个样本 ![]() 经过 key encoder(teacher model)后得到的特征向量为
经过 key encoder(teacher model)后得到的特征向量为 ![]() ,从 A 模态的 Memory Bank 中找出和该特征向量最相近的 K 个特征向量
,从 A 模态的 Memory Bank 中找出和该特征向量最相近的 K 个特征向量 ![]() 。计算
。计算 ![]() 和这 K 个特征向量的距离,得到一个 K 维的距离向量
和这 K 个特征向量的距离,得到一个 K 维的距离向量 ![]() 。再对这 K 维的距离向量求 softmax,将其转化为一个和为 1 的概率向量,这也就是特征向量
。再对这 K 维的距离向量求 softmax,将其转化为一个和为 1 的概率向量,这也就是特征向量 ![]() 和最相近的 K 个特征向量的距离分布(即 A 模态上 teacher 的知识)。
和最相近的 K 个特征向量的距离分布(即 A 模态上 teacher 的知识)。

模态 B 里该样本 ![]() 经过 query encoder (student model)后得到的特征向量为
经过 query encoder (student model)后得到的特征向量为 ![]() ,从 B 模态的 Memory Bank 中找出和该特征向量最相近的 K 个特征向量,计算得到特征向量
,从 B 模态的 Memory Bank 中找出和该特征向量最相近的 K 个特征向量,计算得到特征向量 ![]() 和最相近的 K 个特征向量的距离分布(即 B 模态上 student 的知识)
和最相近的 K 个特征向量的距离分布(即 B 模态上 student 的知识)
最后,通过减少 A 模态上 teacher 的知识 和 B 模态上 student 的知识 之间的 KL 散度,将 A 模态上的知识蒸馏到 B 模态的模型上(只更新 B 模态的模型参数)。

在进行知识蒸馏时,作者设置了超参数  . 由于老师模型(key encoder)是动量更新其参数,所以其提供的知识是更稳定的。为保证输出高置信度的知识,将老师模型(key encoder)的超参数
. 由于老师模型(key encoder)是动量更新其参数,所以其提供的知识是更稳定的。为保证输出高置信度的知识,将老师模型(key encoder)的超参数 ![]() 设置成一个较小的数值。此时,老师模型和学生模型的超参数 值是不相同的,这也就对应了 Contribution 中的最后一点(Asymmetric)。
设置成一个较小的数值。此时,老师模型和学生模型的超参数 值是不相同的,这也就对应了 Contribution 中的最后一点(Asymmetric)。
同理,也可以进行反方向的学习,即通过减少 B 模态上 teacher 的知识 和 A 模态上 student 的知识 之间的 KL 散度,将 B 模态上的知识蒸馏到 A 模态的模型上(只更新 A 模态的模型参数)。
该模态最终的双向蒸馏损失函数如下:
![]()
2.4 最终的损失函数
结合两个模块,最终的损失函数如下:
![]()
其中,a 和 b 代表着两种不同的模态。
2.5 伪代码

2.6 其他
作者还用公式推导证明了一下该工作与 CrosSCLR 工作之间的关系,这里就不详述啦~
结论就是 CrosSCLR 工作约等于该工作的一种特殊情况,即 K=1.
3. Results
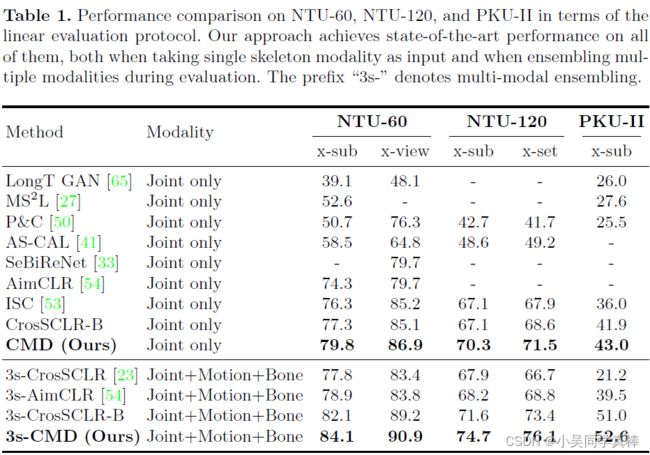
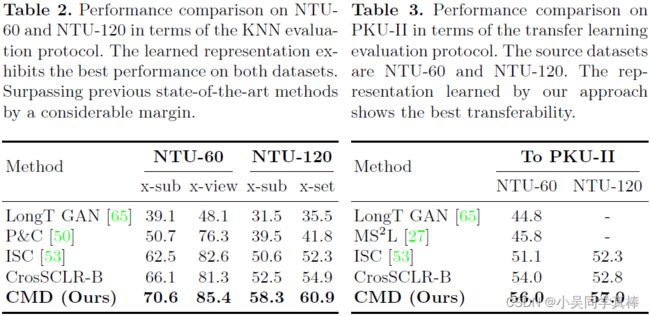
作者在三个数据集上做了线性评估、KNN 评估、迁移学习和半监督评估的下游实验,结果如下:

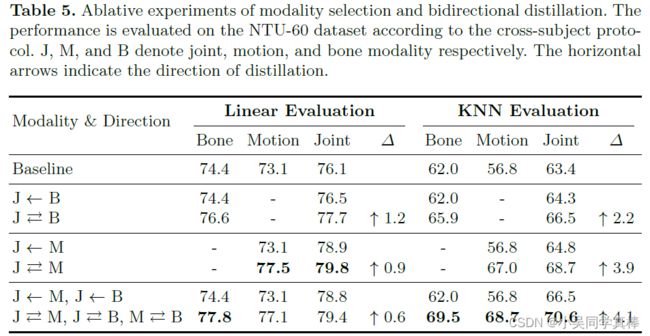
消融实验:
4. 相关论文推荐及解读博客
之前解读过几篇类似的论文,可见链接:
- CrosSCLR:http://t.csdn.cn/Kjkcj
- CPM:http://t.csdn.cn/2rGmi