人工智能是数据的消耗大户,对存储有针对性的需求。这次我们讲讲面向AI场景的存储性能优化思路。
谈优化之前,我们先分析一下AI访问存储的几个特点:
- 海量文件,训练模型的精准程度依赖于数据集的大小,样本数据集越大,就为模型更精确提供了基础。通常,训练任务需要的文件数量都在几亿,十几亿的量级,对存储的要求是能够承载几十亿甚至上百亿的文件数量。
- 小文件,很多的训练模型都是依赖于图片、音频片段、视频片段文件,这些文件基本上都是在几KB到几MB之间,对于一些特征文件,甚至只有几十到几百个字节。
- 读多写少,在大部分场景中,训练任务只读取文件,把文件读取上来之后就开始计算,中间很少产生中间数据,即使产生了少量的中间数据,也是会选择写在本地,很少选择写回存储集群,因此是读多写少,并且是一次写,多次读。
- 目录热点,由于训练时,业务部门的数据组织方式不可控,系统管理员不知道用户会怎样存储数据。很有可能用户会将大量文件存放在同一个目录,这样会导致多个计算节点在训练过程中,会同时读取这一批数据,这个目录所在的元数据节点就会成为热点。跟一些AI公司的同事交流中,大家经常提到的一个问题就是,用户在某一个目录下存放了海量文件,导致训练的时候出现性能问题,其实就是碰到了存储的热点问题。
综上,对于AI场景来说,分布式存储面临三大挑战:
- 海量文件的存储
- 小文件的访问性能
- 目录热点
海量文件的存储
首先讨论海量文件存储的问题。海量文件存储的核心问题是什么,是文件的元数据管理和存储。为什么海量文件会是一个难题,我们看下传统的分布式文件存储架构,以HDFS,MooseFS为例,他们的元数据服务都是主备模式,只有一组元数据。这一组MDS就会受限于CPU,内存,网络以及磁盘等因素,很难支持海量文件的存储,也很难给高并发访问业务提供对应的存储性能。MooseFS单集群最大只能支持20亿的文件数量。传统的分布式文件存储都是针对大文件进行设计的,如果按照每个文件100MB计算,只需要1千万的文件,其总容量就有1PB了,所以对于大文件场景,集群容量是首要考虑的问题。但在AI场景中情况则不同,我们前面分析到,AI场景中80%以上是小文件,一个文件只有几十KB,文件数量动辄就几十亿,文件的数量成为了文件系统要解决的首要矛盾。
针对这个问题,该如何解决呢?我们第一反应就是做横向水平扩展,把单点的MDS集群化。横向扩展的元数据集群可以很好地解决单MDS的问题。第一,缓解了CPU,内存的压力;第二,多个MDS也可以存储更多的元数据信息;第三,元数据的处理能力也能够水平扩展,进而提升海量文件并发访问的性能。
分布式MDS的主流架构有三种:
第一种是静态子树,目录的存放位置是固定的,目录和文件的元数据以及他们数据都放在该节点上。NFS是一个典型的静态子树用法,每个NFS Server代表了一个元数据节点,只要能够保证各个挂载点的顺序和位置一致,多个NFS Server可以组成一个分布式的文件存储集群。它的优点是方式简单,不需要代码实现,只需要把多个NFS Server拼凑起来,保证挂载点一致就行。对应的,缺点也很明显,一个是运维不方便,各个客户端节点需要保证挂载点一致,需要人工干预,换个说法,这个方案并不是统一的命名空间,会带来维护上的复杂度;另外一个是会有数据热点问题,当一批数据进来后,基本上都会落在同一个NFS server上。训练任务读取这批数据的时候,所有的压力也都会集中在这个NFS server上,这个节点就会成为热点。
第二种是动态子树,目录元数据会随着访问的热度在不同的MDS节点上进行迁移,保证MDS之间的负载是均衡的。CephFS就是采用的这种方式,动态子树这个概念也是Ceph的作者提出来的。理论上来说这是一种相对完美的架构,消除了热点问题,元数据集群扩容也很方便。但是理想很丰满,现实很骨感,它的工程复杂度比较高,很难做到稳定。
第三种是Hash,GlusterFS采用的是这种方式,当然了GlusterFS是采用的基于路径的hash方式。它的优点是文件位置分散的比较均匀,不会有热点问题。但是劣势也很明显,元数据缺乏本地性,查询类的操作会很慢(例如对目录进行检索),需要遍历整个集群。
YRCloudFile采用的是静态子树+目录Hash两者结合的方式。这种方式有三个要素:
- 根目录在固定的MDS节点;
- 每一级目录都会根据Entry name进行hash再次选择MDS,保证横向扩展的能力;
- 目录下文件的元数据进行存放时,不进行hash,而是跟父目录在同一个节点,保证一定程度的元数据本地性。
这种做法带来两个好处,其一是实现了元数据的分布存储,从而通过扩展元数据节点即可支持百亿级别的文件数量,其二是在一定程度上保证了元数据的检索性能,减少在多个节点上进行元数据检索和操作。
小文件的访问性能
其次,我们讨论小文件性能访问。关于小文件,我们需要知道几点:第一,为什么关注小文件,前边我们提到,AI训练中,大的图片,语音文件通常会切片后进行分析,有助于分析特征,训练的文件大小通常在几KB到几MB之间,小文件的吞吐性能直接影响了AI训练效率;第二,小文件的性能瓶颈在哪里,读取一个小文件,需要多次元数据操作加一次数据操作。通常的改进思路,小文件内联,小文件聚合和客户端读缓存。这部分内容,本文先卖个关子,后续再通过单独的文章阐述。
目录热点
最后我们重点来讨论下目录热点的问题。
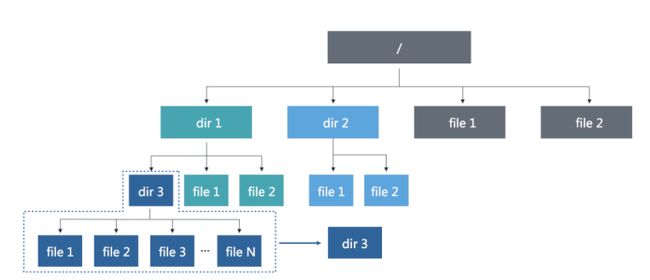
从这个图中,我们可以看到,假如dir3目录中有大量文件,比如说几百万,上千万文件,训练的时候,多个计算节点需要同时读这批文件的时候,dir3所在的MDS节点就会变成一个热点。
如何去解决热点问题呢?直观的想法,既然目录变成了一个热点,那就对目录进行拆分。对目录进行拆分有两种思路,一种是目录的镜像扩展,另一种是增加虚拟子目录。两种都能解决热点所引发的性能问题。
目录的镜像扩展,就是对指定的目录进行设置,这个目录及其下的文件元数据会在指定的几个MDS节点上存在,具体的这些MDS节点的位置信息会记录在目录的inode中,对这个目录内的文件进行open/close/unlink等操作的时候,会根据filename进行hash,找到对应MDS节点,再对文件进行操作,这样就把热点问题分摊到了指定的几个MDS节点上。整个思路类似于web架构中的负载均衡,如图所示。
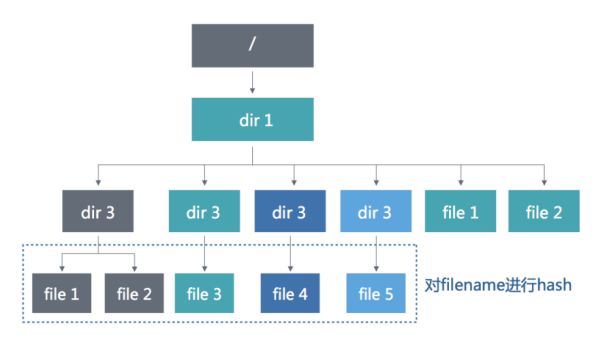
我们采用的是第二种,增加虚拟子目录的方式。这种方式虽然多了一层目录的查询操作,但是足够灵活,可以把热点分摊到集群中所有的元数据节点,同时也可以解决另外一个问题,就是单目录的文件数量问题。增加虚拟子目录可以很好的解决这个问题,使单目录可以支撑20亿左右的文件数量,并且可以根据虚拟子目录的数量灵活调整。

我们通过访问/dir1/dir2/file1举例来看看虚拟子目录是如何实现的。假设dir2是开启了dirStripe功能。访问流程:
- 在MDS1上拿到根目录的inode信息,查看没有开启dirStripe
- 在MDS1上获取dir1的dentry信息,找到所属owner(mds2)
- 在MDS2上拿到dir1的inode信息,查看没有开启dirStripe
- 在MDS2上获取dir2的dentry信息,找到所属owner(mds3)
- 在MDS3上拿到dir2的inode信息,查看开启了dirStripe
- 根据file1的filename,hash到虚拟目录2上
- 在MDS3上获取虚拟目录2的dentry信息,找到所属owner(mds4)
- 在MDS4上拿到file1的inode信息,返回给客户端
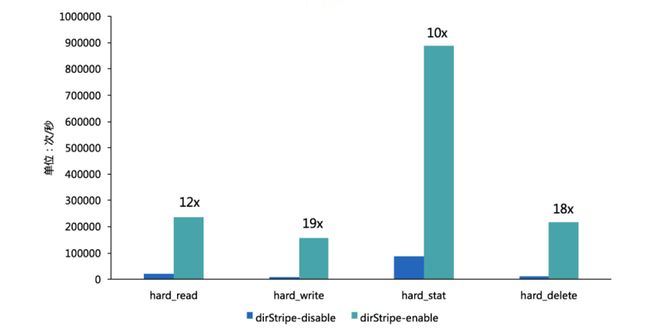
测试模拟了AI训练中,多个客户端并发访问同一个目录的场景。图中的结果是增加目录拆分前后的性能对比,从图中可以看到,无论是hard read, hard write,还是stat delete,目录拆分后,都有10倍以上的性能提升。
总结
本文针对海量文件存储、小文件访问性能、热点访问三个维度,分析了面向AI场景下,分布式文件系统面临的挑战,以及我们的应对思路,也希望借此文和更多技术专家交流如何对AI场景下的存储方案进行针对性的优化。