C++异常
目录
- 一、C语言处理错误的常用方式
- 二、C++异常的概念
- 三、异常的使用
-
- 3.1 异常的抛出和捕获
- 3.2 异常的重新抛出
- 3.3 异常安全
- 3.4 异常规范
- 四、自定义异常体系
- 五、C++标准库的异常体系
- 六、异常的优缺点(重点)
一、C语言处理错误的常用方式
传统的错误处理机制:
1、终止程序。如用assert断言,太暴力了,用户难以接受,例如发生除零错误程序会直接终止。
2、返回错误码。需要程序员自己去查找对应的错误。如系统的很多库的接口函数都是通过把错误码放到errno中,表示错误。
实际中C语言基本都是使用返回错误码的方式处理错误,部分情况下使用终止程序处理非常严重的错误。如除零错误是绝对不允许发生的,一旦出现,必然要直接终止程序。
二、C++异常的概念
异常是一种处理错误的方式,当一个函数发现自己无法处理的错误时就可以抛出异常,让函数的直接或间接的调用者处理这个错误。
throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
catch: 在您想要处理问题的地方,通过异常处理程序捕获异常.catch 关键字用于捕获异常,可以有多个catch进行捕获。
try: try 块中的代码标识将被激活的特定异常,它后面通常跟着一个或多个 catch 块。
如果有一个块抛出一个异常,捕获异常的方法会使用 try 和 catch 关键字。try 块中放置可能抛出异常的代码,try 块中的代码被称为保护代码。
捕获异常的示例如下:
int main()
{
try
{
int a = 10;
int b = 0;
if (b == 0)
{
//抛出异常
throw string("除零错误");
}
int c = a / b;
cout << c << endl;
}
catch(const string& s)//捕获异常
{
cout << s << endl;
}
return 0;
}
三、异常的使用
3.1 异常的抛出和捕获
异常的抛出和匹配原则
- 异常是通过抛出对象而引发的,该对象的类型决定了应该激活哪个catch的处理代码。
- 被选中的处理代码是调用链中与该对象类型匹配且离抛出异常位置最近的那一个。
- 抛出异常对象后,会生成一个异常对象的拷贝,因为抛出的异常对象可能是一个临时对象,所以会生成一个拷贝对象,这个拷贝的临时对象会在被catch以后销毁。(类似于函数的传值返回)
- catch(…)可以捕获任意类型的异常,但是并不能知道异常错误是什么。
- 实际中抛出和捕获的匹配原则有一个是例外的,并不都是类型完全匹配,可以抛出的子类对象,使用父类捕获,这个在实际中非常实用。
在函数调用链中异常栈展开匹配原则
- 首先检查throw本身是否在try块内部,如果是再查找匹配的catch语句。如果有匹配的,则调到catch的地方进行处理。
- 没有匹配的catch则退出当前函数栈,继续在调用函数的栈中进行查找匹配的catch。
- 如果到达main函数的栈,依旧没有匹配的,则终止程序。上述这个沿着调用链查找匹配的catch子句的过程称为栈展开。所以实际中我们最后都要加一个catch(…)捕获任意类型的异常,否则当有异常没捕获,程序就会直接终止。
- 找到匹配的catch子句并处理以后,会继续沿着catch子句后面继续执行。
void test2()
{
try
{
int a = 10;
int b = 0;
if (b == 0)
{
throw "除零错误";
}
}
catch (double d)//类型不匹配,继续往上一层栈帧找
{
cout << d << endl;
}
}
void test1()
{
try
{
test2();
}
catch (int a)//类型不匹配,继续往上一层栈帧找
{
cout << a << endl;
}
cout << "test1()" << endl;
}
int main()
{
try
{
test1();
}
catch (const char* s)//类型匹配
{
cout << s << endl;
}
return 0;
}

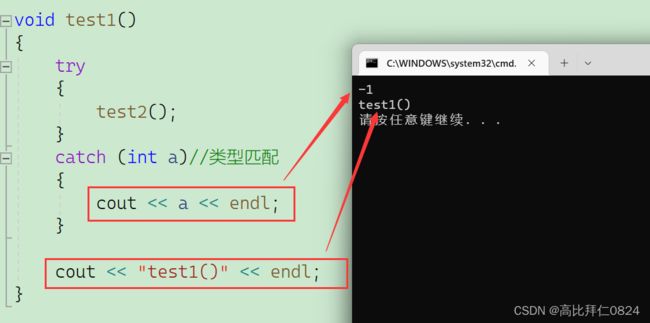
如果提前匹配到了,就不会继续往外抛出,而是紧接着执行捕获到异常的位置的后面的代码。
例如:
void test2()
{
try
{
int a = 10;
int b = 0;
if (b == 0)
{
throw - 1;
}
}
catch (double d)//类型不匹配,继续往上一层栈帧找
{
cout << d << endl;
}
}
void test1()
{
try
{
test2();
}
catch (int a)//类型匹配
{
cout << a << endl;
}
cout << "test1()" << endl;
}
int main()
{
try
{
test1();
}
catch (const char* s)
{
cout << s << endl;
}
return 0;
}
3.2 异常的重新抛出
有可能单个的catch不能完全处理一个异常,在进行一些校正处理以后,希望再交给更外层的调用链函数来处理,catch则可以通过重新抛出将异常传递给更上层的函数进行处理。
double Div(int a, int b)
{
// 当b == 0时抛出异常
if (b == 0)
{
throw "Div by zero condition!";
}
double c = a / b;
return c;
}
void test()
{
// 这里可以看到如果发生除0错误抛出异常,另外下面的array没有得到释放。
// 所以这里捕获异常后并不处理异常,异常还是交给外面处理,这里捕获了再
// 重新抛出去。
int* arr = new int[20];
try
{
int a, b;
cin >> a >> b;
cout << Div(a, b) << endl;
}
//这里必须要能够把异常捕获到再重新抛出,因为如果异常
//直接抛出到外面,则arr将不会被释放,就会出现内存泄
//漏的的问题(这里是异常非常坑的地方),所以无论前面
//写了多少个捕获的函数,在最后都必须要写一个catch...
//的,因为你架不住别人会乱抛异常
catch (...)
{
cout << "delete []" << arr << endl;
delete[] arr;
throw;
}
// ...
cout << "delete []" << arr << endl;
delete[] arr;
}
int main()
{
try
{
test();
}
catch (const char* errmsg)
{
cout << errmsg << endl;
}
catch(...)
{
cout<<"未知错误"<<endl;
}
return 0;
}
3.3 异常安全
构造函数完成对象的构造和初始化,最好不要在构造函数中抛出异常,否则可能导致对象不完整或没有完全初始化。
析构函数主要完成资源的清理,最好不要在析构函数内抛出异常,否则可能导致资源泄漏(内存泄漏、句柄未关闭等问题)
C++中异常经常会导致资源泄漏的问题,比如在new和delete中抛出了异常,导致内存泄漏,在lock和unlock之间抛出了异常导致死锁,C++经常使用RAII来解决以上问题。RAII需要在后面的智能指针的时候再总结。
3.4 异常规范
- 异常规规范说明的目的是为了让函数使用者知道该函数可能抛出的异常有哪些。 可以在函数的后面接throw(类型),列出这个函数可能抛掷的所有异常类型。
- 函数的后面接throw(),表示函数不抛异常。
- 若无异常接口声明,则此函数可以抛掷任何类型的异常。
// 这里表示这个函数会抛出A/B/C/D中的某种类型的异常
void fun() throw(A,B,C,D);
// 这里表示这个函数只会抛出bad_alloc的异常
void* operator new (std::size_t size) throw (std::bad_alloc);
// 这里表示这个函数不会抛出异常
void* operator delete (std::size_t size, void* ptr) throw();
// C++11 中新增的noexcept,表示不会抛异常
thread() noexcept;
thread (thread&& x) noexcept;
四、自定义异常体系
实际使用中很多公司都会自定义自己的异常体系进行规范的异常管理,因为一个项目中如果大家随意抛异常,那么外层的调用者(程序员)基本就没办法玩了,所以实际中都会定义一套继承的规范体系。
这样大家抛出的都是继承的派生类对象,捕获一个基类就可以了。
例如:服务器开发中通常使用的异常继承体系如下:
class Exception
{
public:
Exception(const string& errmsg,int id)
:_errmsg(errmsg)
,_id(id)
{}
virtual const string what()const
{
return _errmsg;
}
protected:
string _errmsg;
int _id;
};
class CacheException :public Exception
{
public:
CacheException(const string& errmsg,int id)
:Exception(errmsg,id)
{}
virtual const string what()const
{
string errmsg = "CacheException:" + _errmsg + " id:" + to_string(_id);
return errmsg;
}
private:
};
class HttpServerException :public Exception
{
public:
HttpServerException(const string& errmsg, int id)
:Exception(errmsg, id)
{}
virtual const string what()const
{
string errmsg = "HttpServerException:" + _errmsg + " id:" + to_string(_id);
return errmsg;
}
private:
};
class SqlException :public Exception
{
public:
SqlException(const string& errmsg, int id)
:Exception(errmsg, id)
{}
virtual const string what()const
{
string errmsg = "SqlException:" + _errmsg + " id:" + to_string(_id);
return errmsg;
}
private:
};
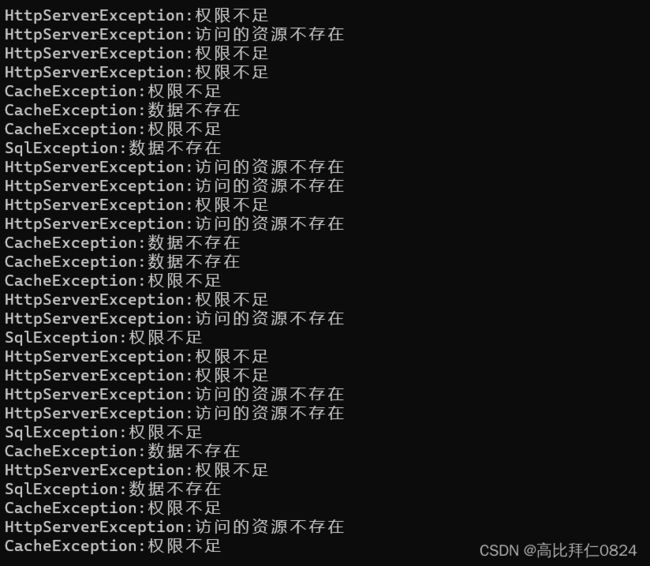
void Sql()
{
if (rand() % 7 == 0)
{
throw SqlException("数据不存在", 24);
}
else if (rand() % 8 == 0)
{
throw SqlException("权限不足", 8);
}
}
void Cache(void)
{
if (rand() % 5 == 0)
{
throw CacheException("权限不足", 200);
}
else if (rand() % 6 == 0)
{
throw CacheException("数据不存在", 300);
}
Sql();
}
void HttpServer()
{
if (rand() % 3 == 0)
{
throw HttpServerException("权限不足",10);
}
else if (rand() % 4 == 0)
{
throw HttpServerException("访问的资源不存在", 12);
}
Cache();
}
int main()
{
srand((unsigned int)time(nullptr));
while (1)
{
Sleep(1000);
try
{
HttpServer();
}
catch (const Exception& e)
{
cout << e.what() << endl;
}
catch (...)
{
cout << "未知异常" << endl;
}
}
return 0;
}
五、C++标准库的异常体系
C++ 提供了一系列标准的异常,定义在库中,我们可以在程序中使用这些标准的异常。它们是以父子类层次结构组织起来的,如下所示:
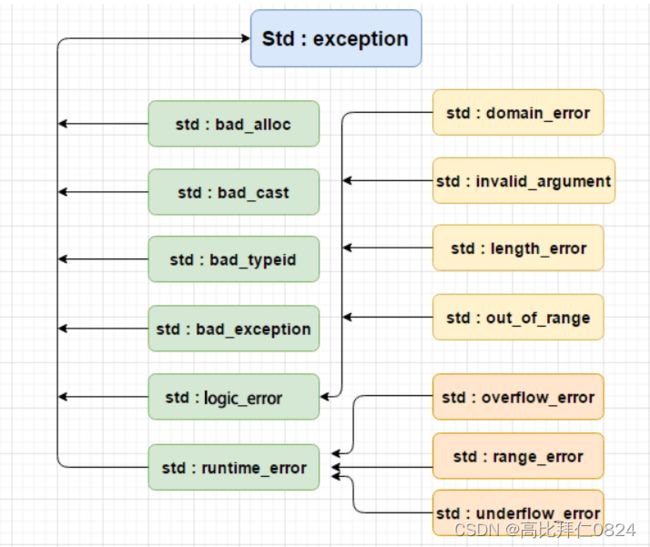
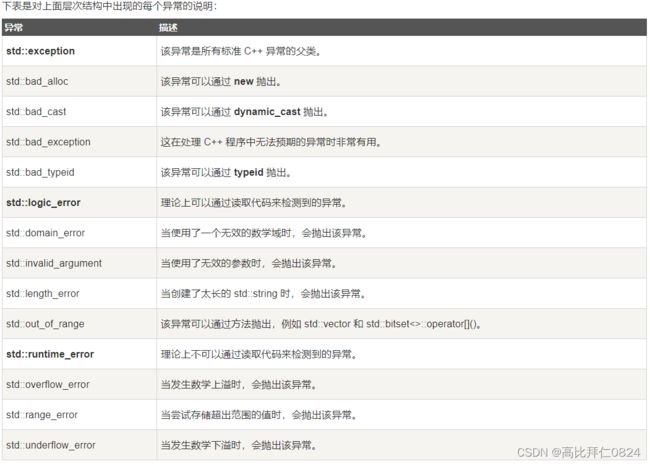
实际中我们可以继承exception类实现自己的异常类。但是实际中很多公司像上面(四、自定义异常体系)一样自己定义一套异常继承体系。因为C++标准库设计的不够好用。
int main()
{
try
{
vector<int> v(10, 5);
// 这里如果系统内存不够也会抛异常
v.reserve(1000000000);
}
catch (const exception& e) // 这里捕获父类对象就可以
{
cout << e.what() << endl;
}
catch (...)
{
cout << "Unkown Exception" << endl;
}
return 0;
}

六、异常的优缺点(重点)
C++异常的优点:
1.异常对象定义好了,相比错误码的方式可以清晰准确的展示出错误的各种信息,甚至可以包含堆栈调用的信息,这样可以帮助更好的定位程序的bug。
2. 返回错误码的传统方式有个很大的问题就是,在函数调用链中,深层的函数返回了错误,那么我们得层层返回错误,最外层才能拿到错误。
3. 很多的第三方库都包含异常,比如boost、gtest、gmock等等常用的库,那么我们使用它们也需要使用异常。
4. 部分函数使用异常更好处理,比如构造函数没有返回值,不方便使用错误码方式处理。比如T& operator这样的函数,如果pos越界了只能使用异常或者终止程序处理,没办法通过返回值表示错误。
C++异常的缺点:
1.异常会导致程序的执行流乱跳,并且非常的混乱,并且是运行时出错抛异常就会乱跳。这会导致我们跟踪调试时以及分析程序时,比较困难。
2. 异常会有一些性能的开销。当然在现代硬件速度很快的情况下,这个影响基本忽略不计。
3. C++没有垃圾回收机制,资源需要自己管理。有了异常非常容易导致内存泄漏、死锁等异常安全问题。这个需要使用RAII来处理资源的管理问题。学习成本较高。
4. C++标准库的异常体系定义得不好,导致大家各自定义各自的异常体系,非常的混乱。
5. 异常尽量规范使用,否则后果不堪设想,随意抛异常,外层捕获的用户苦不堪言。
所以异常规范有两点:一、抛出异常类型都继承自一个基类。二、函数是否抛异常、抛什么异常,都使用 func() throw();的方式规范化。
总的来说就是:异常总体而言,是利大于弊,所以工程中我们还是鼓励使用异常的。另外OO(面向对象)的语言基本都是用异常处理错误,这也可以看出这是大势所趋。
以上就是今天想要跟大家分享的C++异常的相关内容啦,你学会了吗?如果你感觉到有所收获的话,就点点赞顺便点点关注呗,后期还会持续更新C++的相关知识哦,我们下期见!!!