深入源码分析kubernetes informer机制(三)Resync
[阅读指南]
这是该系列第三篇
基于kubernetes 1.27 stage版本
为了方便阅读,后续所有代码均省略了错误处理及与关注逻辑无关的部分。
文章目录
- 为什么需要resync
- resync做了什么
为什么需要resync
如果看过上一篇,大概能了解,client数据主要通过reflector 的list/watch进行同步。
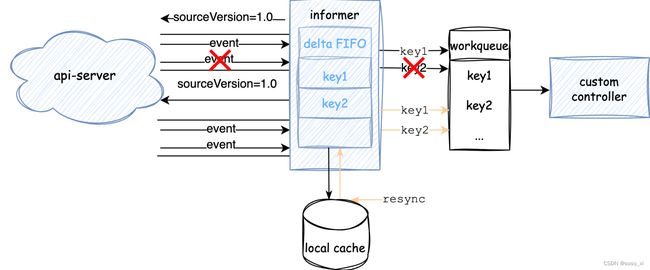
回顾一下informer整体的数据同步逻辑。
- informer初始化时,调用list接口获取制定类型的全量资源数据,此时的resource version默认为0。假如指定资源类型为pod,那么就是获取所有pod数据
- list 获取到数据后,将全量数据同步到本地缓存。首次list完成后,informer后续都将通过watch来同步资源更新
- watcher监控到资源更新事件,将接收到的事件放入存储队列中(delta FIFO)
- informer 的另一个process会不断取出存储队列中的delta事件进行数据更新
- 缓存数据更新成功后,将数据变化通过回调函数同步至custom controller workqueue中
- custom controller顺序处理workqueue中的数据变更事件

流程包括了三端的数据同步。
-
首先api-server与informer中间通过sourceVersion可以保证数据的一致性
client携带本地的sourceVersion请求api-server,api-server会将最新版本的增量变化通过事件返回给client。
如图所示,在此期间,如果数据连接发生任何异常,informer会在重新建立watcher连接时,携带上个版本的sourceVersion,并再次更新所有的增量变化。

-
然后是本地informer与custom之间,通过workqueue来进行事件通知。
informer的协程将FIFO队列中的事件取出更新至本地后,还会将事件同步回调至custom controller,加入到workqueue队列中。
但是回看informer的代码,informer在处理回调事件时,并不会关注回调的结果。

也就是说,如果custom controller侧的消费出现异常导致数据同步失败,informer是不知情的。
所以还需要引入别的机制来保障custom数据与本地缓存的一致性,以维持体的可靠性,也就是resync。
(当然如果controller本身也存在对比sourceVersion的逻辑,其实不需要这一机制也是可以确保数据一致的,resync相当于从框架层增加了一层保护,这篇博客有对相关的问题进行探讨)
resync做了什么
resync的逻辑非常简单,就是定时将本地缓存中所有的资源对象生成事件重新推送到FIFO中,重新触发controller的回调。
参考《Programming Kubernetes》一书中的概念,其实就是在边缘触发,水平驱动的基础上,附加了定时同步的能力。
具体来看下resync的代码实现。
informer在初始化时指定了resync执行间隔。
// informer创建方法
func NewIndexerInformer(
lw ListerWatcher,
objType runtime.Object,
resyncPeriod time.Duration, // Resync执行周期
h ResourceEventHandler,
indexers Indexers,
) (Indexer, Controller) {}
// workqueue调用示例
// 0 代表不重复执行
indexer, informer := cache.NewIndexerInformer(podListWatcher, &v1.Pod{}, 0, cache.ResourceEventHandlerFuncs{...})
在informer初始化完成后,拉起一个协程进行定时resync
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
...
go r.startResync(stopCh, cancelCh, resyncerrc)
return r.watch(w, stopCh, resyncerrc)
}
该协程会按照informer配置的时间间隔定时调用存储对象的resync方法。
比较特殊的是,sharedIndexInformer类型的informer会另外有ShouldResync方法来轮询每个监听了当前资源对象的listener的是否需要进行resync操作。
func (r *Reflector) startResync(stopCh <-chan struct{}, cancelCh <-chan struct{}, resyncerrc chan error) {
resyncCh, cleanup := r.resyncChan() // 返回一个触发resync的信号,内部实现就是一个timer
defer func() {
cleanup() // Call the last one written into cleanup
}()
for {
select {
case <-resyncCh:
case <-stopCh:
return
case <-cancelCh:
return
}
// sharedIndexInformer 中用ShouldResync()来管理各个listener的resync
if r.ShouldResync == nil || r.ShouldResync() {
if err := r.store.Resync(); err != nil {
resyncerrc <- err
return
}
}
cleanup()
resyncCh, cleanup = r.resyncChan()
}
}
resync只做一件事,将本地缓存里的资源对象全部重新添加到FIFO队列中,再触发contronller处理一次。
不过,为了避免与最新的变更发生冲突,FIFO队列中已有delta且还没有处理的资源对象,不会被重新添加。
func (f *DeltaFIFO) Resync() error {
f.lock.Lock()
defer f.lock.Unlock()
if f.knownObjects == nil {
return nil
}
// f.knownObjects 可以获取到本地缓存中所有资源对象的列表
keys := f.knownObjects.ListKeys()
for _, k := range keys {
// 过滤掉已经有新的事件在队列中等待处理的资源对象
// 把所有资源对象以resync类型添加到队列中
if err := f.syncKeyLocked(k); err != nil {
return err
}
}
return nil
}
参考:
https://www.kubernetes.org.cn/2693.html
https://github.com/cloudnativeto/sig-kubernetes/issues/11
https://www.cnblogs.com/WisWang/p/13897782.html