Pandas学习笔记
Pandas学习笔记

Pandas是一个流行的Python开源数据分析库,提供了丰富的数据结构和数据处理工具,特别适用于数据清洗、处理、分析和可视化。它是数据科学家、分析师和工程师们在Python生态系统中进行数据处理和分析的重要工具之一。
Pandas主要提供两种核心数据结构:Series和DataFrame。
-
Series:Series是一维标记数组,类似于Python中的列表或数组,但附带了标签(label),使得数据具有更好的索引能力。Series可以包含不同类型的数据,并且支持各种数学运算。
-
DataFrame:DataFrame是一个二维的表格型数据结构,类似于关系型数据库中的表或Excel中的数据表。DataFrame可以被看作是多个Series对象按列组合而成,每列可以是不同的数据类型。它可以处理大量的数据,并提供了许多数据操作和转换的方法。
文章目录
- Pandas学习笔记
- 前言
-
- 1.Anaconda介绍
- 2.Jupyter介绍
- 一、Pandas数据读取
- 二、Pandas数据结构
- 2.待更
- 总结
前言
Pandas库的一些重要功能包括:
-
数据清洗:Pandas提供了各种方法用于处理缺失数据(NaN值)、重复数据、异常数据等。
-
数据操作:Pandas允许用户执行数据的筛选、过滤、排序、合并、拼接等操作,使得数据的处理更加灵活高效。
-
数据聚合:Pandas可以根据用户的需求对数据进行分组、聚合和汇总操作,例如计算平均值、求和、计数等。
-
时间序列处理:Pandas具有强大的时间序列处理功能,可以进行时间索引和频率转换,支持时间序列的滚动操作和重采样等。
-
数据可视化:Pandas结合了Matplotlib库,可以直接在DataFrame和Series上调用绘图方法,快速绘制直方图、折线图、散点图等。
Jupyter是一个非常受欢迎的交互式计算环境,允许用户在Web浏览器中创建和共享包含代码、文本、图像和其他媒体的文档。它支持多种编程语言,但最常用的是Python。
1.Anaconda介绍
当然,我很乐意为您介绍Anaconda。
Anaconda是一个流行的开源Python和R编程语言的发行版,主要用于数据科学、科学计算、人工智能和机器学习。它包含了许多常用的数据科学工具、库和软件,使得安装和管理这些工具变得非常方便。
Anaconda的主要特点和优势包括:
-
软件包管理: Anaconda拥有自己的软件包管理系统,可以方便地安装、升级和删除各种Python和R库。这些库包括了数据科学和机器学习领域中广泛使用的库,如NumPy、Pandas、Matplotlib、Scikit-learn、TensorFlow、PyTorch等。
-
跨平台支持: Anaconda支持Windows、macOS和Linux等多个操作系统,用户可以在不同平台上使用相同的Python和R环境和库。
-
虚拟环境管理: Anaconda允许用户创建独立的Python和R虚拟环境,每个环境可以有自己的库和版本,以避免不同项目之间的库版本冲突。
-
Jupyter集成: Anaconda默认安装了Jupyter Notebook,用户可以通过Jupyter在Web浏览器中进行交互式计算、数据分析和可视化。
-
科学计算工具: Anaconda发行版包含了许多用于科学计算和数据分析的工具,涵盖统计学、优化、图像处理、自然语言处理等多个领域。
-
大型社区支持: Anaconda拥有庞大的用户社区和开发者社区,用户可以从社区中获得丰富的资源和支持。
Anaconda可以通过下载官方发行版来安装,Anaconda发行版包含了Python(或R)解释器、Conda包管理器、各种常用库和工具,以及Anaconda Navigator图形界面。通过Anaconda Navigator,用户可以方便地管理和使用Python和R环境,安装所需的库和工具,启动Jupyter Notebook等。
Anaconda是数据科学家、研究人员和开发者的首选工具,它提供了一个集成、稳定且易用的环境,方便用户进行数据科学、机器学习和科学计算。无论您是初学者还是专业人士,Anaconda都能为您提供强大的支持和便捷的工作流程。
2.Jupyter介绍
源自三种主要的编程语言:Julia、Python和R,它们共同构成了"Jupyter"这个词。
主要特点和优势:
-
交互式计算: Jupyter允许用户一步一步地执行代码,同时保持代码的运行状态和输出结果。这种交互式计算方式非常适合数据探索、数据可视化和实验性编程。
-
支持多种编程语言: Jupyter不仅支持Python,还支持其他编程语言,如R、Julia、Scala等。这使得用户可以在同一个环境中使用多种编程语言进行计算和分析。
-
结合代码和文本: Jupyter笔记本允许用户在同一个文档中编写代码、文本、公式、图像和交互式可视化内容,使得代码和解释性文本可以直接结合在一起,非常适合进行数据科学和数据分析报告的撰写。
-
数据可视化: Jupyter支持直接在笔记本中绘制图表和图形,用户可以快速生成各种可视化图表,更直观地理解数据。
-
易于共享: Jupyter笔记本可以保存为文件,并轻松共享给其他人。在Jupyter Notebook中,你可以记录整个数据分析过程,包括代码、结果和解释,分享给他人时可以更好地展示和说明你的工作。
-
大型生态系统: Jupyter有一个庞大的社区,提供了许多扩展和插件,支持数据科学、机器学习、深度学习等领域的开发和应用。
Jupyter可以通过安装Anaconda发行版或纯粹的Python发行版来使用。安装Jupyter后,你可以通过命令行启动Jupyter Notebook,然后在浏览器中打开交互式界面,并创建、运行和编辑Jupyter笔记本。
Jupyter的交互式计算和可视化特性使得它成为数据科学家、数据分析师、研究人员和教育工作者等使用的强大工具,帮助他们更方便地探索数据、实验算法并进行数据可视化。
一、Pandas数据读取
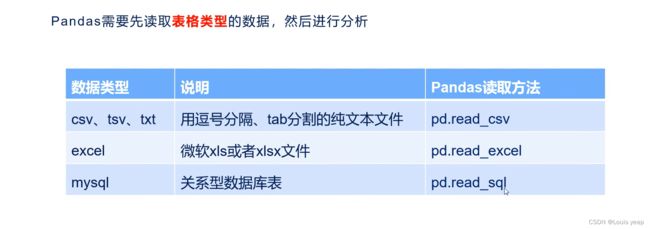
在Pandas中,有多种方法可以读取不同类型的数据。Pandas支持读取和处理各种数据源,包括CSV文件、Excel文件、数据库、JSON文件、HTML表格、SQL查询结果等。下面是一些常用的方法来读取数据,并指定读取后的数据类型:
- 从CSV文件读取:
import pandas as pd
# 读取CSV文件,并指定数据类型
df = pd.read_csv('data.csv', dtype={'column_name': dtype})
在上面的代码中,你需要将"column_name"替换为你希望指定数据类型的列的名称,将dtype替换为你希望指定的数据类型,例如int、float、str等。
- 从Excel文件读取:
import pandas as pd
# 读取Excel文件,并指定数据类型
df = pd.read_excel('data.xlsx', dtype={'column_name': dtype})
同样,在上面的代码中,将"column_name"替换为你希望指定数据类型的列的名称,将dtype替换为你希望指定的数据类型。
- 从数据库读取:
import pandas as pd
import sqlite3
# 连接到数据库
conn = sqlite3.connect('database.db')
# 读取数据库表中的数据,并指定数据类型
df = pd.read_sql_query('SELECT * FROM table_name', conn, dtype={'column_name': dtype})
在上面的代码中,将"table_name"替换为你要读取的数据库表的名称,将"column_name"替换为你希望指定数据类型的列的名称,将dtype替换为你希望指定的数据类型。
- 从JSON文件读取:
import pandas as pd
# 读取JSON文件,并指定数据类型
df = pd.read_json('data.json', dtype={'column_name': dtype})
同样,在上面的代码中,将"column_name"替换为你希望指定数据类型的列的名称,将dtype替换为你希望指定的数据类型。
这些方法中的dtype参数用于指定特定列的数据类型。它可以是Python原生数据类型,也可以是NumPy数据类型。通过在读取数据时指定数据类型,可以更精确地控制数据的解析过程,并避免一些数据类型自动推断的问题。
二、Pandas数据结构
Pandas提供了两种主要的数据结构:一维Series和二维DataFrame。
- Series:
Series是Pandas中的一维数据结构,类似于带有标签索引的数组。它由一组数据和与之相关联的索引组成。索引可以是自定义的标签,也可以是默认的整数索引。Series可以包含不同类型的数据,例如整数、浮点数、字符串等。
创建Series的方法:
import pandas as pd
# 从列表创建Series
data = [10, 20, 30, 40, 50]
index = ['a', 'b', 'c', 'd', 'e']
series = pd.Series(data, index=index)
# 从字典创建Series
data = {'a': 10, 'b': 20, 'c': 30, 'd': 40, 'e': 50}
series = pd.Series(data)
- DataFrame:
DataFrame是Pandas中的二维数据结构,类似于电子表格或SQL表格。它由行索引和列索引组成,每一列可以包含不同类型的数据。DataFrame是最常用的数据结构,用于存储和处理结构化数据。
创建DataFrame的方法:
import pandas as pd
# 从字典创建DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'London', 'Paris']}
df = pd.DataFrame(data)
# 从列表创建DataFrame
data = [[10, 20, 30], [40, 50, 60], [70, 80, 90]]
columns = ['A', 'B', 'C']
df = pd.DataFrame(data, columns=columns)
除了Series和DataFrame之外,Pandas还支持一些其他的数据结构,例如Panel(三维数据结构,现已不推荐使用)、Panel4D(四维数据结构)和PanelND(更高维度的数据结构)。但随着Pandas版本的更新,对于多维数据,更推荐使用NumPy的ndarray或Xarray库。
Pandas的Series和DataFrame提供了丰富的数据操作和处理方法,可以用于数据清洗、分析、聚合、合并、过滤、排序等操作,使得数据科学家和分析师可以更轻松地处理和探索数据。
2.待更
总结
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。