VDSR(Accurate Image Super-Resolution Using Very Deep Convolutional Networks)超分辨网络-详细分析
对超分有兴趣的同学们可直接关注微信公众号,这个号的定位就是针对图像超分辨的,会不断更新最新的超分算法解读。
正文开始
contents
- Introduction
- Related Work
- Proposed Method
-
- Proposed Network
- Training
- Understanding Properties
-
- The Deeper, the Better
- Residual-Learning
- Single Model for Multiple Scales
- Experimental Results
-
- Datasets for Training and Testing
- Training Parameters
- Benchmark
- Comparisons with State-of-the-Art Methods
- Conclusion
- References
Introduction
理解残差的概念,关键在于差,将差的部分加上原始部分才等于最终结果。例如在VDSR中,获得的残差为高频细节部分的信息图,再和原始低分图LR求和才得到SR图像。本文针对SRCNN,提出了3个问题的解决方案:
- 卷积核尺寸一定时,网络层数过浅导致生成图片的感受野过小。一个更深度的网络势必能带来更大的感受野,这就使得网络能够利用更多的上下文信息,能够有更反映全局的映射。;
- 为解决问题1必将加深网络深度,会使得网络的收敛速率变慢甚至无法收敛(学习率、梯度裁减)。作者提出的解决方案是利用残差学习和更高的学习率。首先,我们认为LR和HR共享了很多基本信息(由后边可知:低频结构信息),所以我们只需要学习LR和HR之间的差值(高频信息)即可,这称之为残差学习。明显可知,传统的学习方法(SRCNN)是从LR中直接学习到完整的结果图(SR)的特征,这学习强度明显大于只学习到部分高频信息(即残差学习),所以残差学习无论从难以程度还是学习时间成本上都优于SRCNN。最后在将学到的高频信息和LR(低频信息)整合即可获得接近于目标HR的结果图SR。其次,利用更高的学习率可以加速网络的收敛(事实上,作者对于不同的epoch运用了不同的学习率),但可能造成梯度的爆炸,所以提出了梯度裁减的方法来避免。可以看出,后来的网络大多都运用了残差学习的思想;
- SRCNN不能进行多尺度放大。分别设计不同的网络生成不同的模型来解决不同的尺度放大问题不切合实际,所以作者提出用一个网络训练不同的尺度放大图片来得到一个模型,解决不同放大尺度的问题。(由后文可知,作者并未给出具体操作,或许和EDSR相同。)
Related Work
首先说明了感受野的重要性,感受野定义为:输出图像中每个像素能够反映输入图像区域的大小。一个更深度的网络势必能带来更大的感受野,这就使得网络能够利用更多的上下文信息,能够有更全局的映射。
其次,残差学习通过对LR图片学习高频细节,然后加到LR上以获得SR图像。这可以更好的理解很多作者讲的ill-posed problem,因为我们是从低频图LR上估计高频图。另外我们可以联想到retinex的思想,也是将一副图片进行拆分。
然后,用一个模型训练3中尺度的缩放模型。
最后,相比于SRCNN在卷积中不适用padding而造成的生成图像相比于输入图像被缩小丢失几圈像素,VSDN在每层卷积中都考虑到了以0作为padding以使得conv前后的分辨率保持不变。相比于SRCNN前两层使用0.0001的学习率,第三层使用0.00001的学习率,VDSR每层的学习率相同,但每20个epoch,学习率乘上0.1。
Proposed Method
Proposed Network

首先将图像进行插值得到ILR图像,再将其输入网络(在总结部分可看出,这是个缺陷)。网络是基于VGG19的,利用了19组conv+relu层,每个conv采用的filter规格为3364。
在做卷积处理边缘像素时的三种解决办法:
- 限制核中心与边缘的距离;
- 用0填充,通过公式计算padding宽度;
- 用边缘像素填充,通过公式计算padding宽度。
SRCNN用方法1导致SR缩小,VDSR采用方法2。
Training
以均方误差MSE作为损失函数已获得最佳PSNR。
Residual-Learning:因为直接从LR中恢复SR图像时,网络需要传递整个图像的信息,而过深的网络可能记不住这么大的信息量,这可能导致梯度消失。因此,通过残差学习,只学习图像的高频信息,学习量小,有利于网络更好的运作。
损失函数由原来的SR和HR间的MES,转换为SR何残差HR-LR间的MSE。
文章使用带动量的SGD,动量参数为0.9。训练的正则化通过权值衰减(使用L2惩罚λw**2/2,λ=0.0001)(为啥不用BN?)进行。
补充一下SGD和momentum SGD的区别(参考文末文献),个人感悟,望纠正:我认为SGD是视原参数W为位移,而在此时的位移w上减掉一个同方向的速度的加权,获得下一个状态的w。而含动量的SGD考虑原状态的速度,需要在执行SGD时加上w的原速度的加权。从微分的角度出发,上述的各种速度,都是单位时间上的一段位移。
High Learning Rates for Very Deep Networks:下图为SRCNN不同深度,不同卷积核尺寸的网络训练比较:

由于SRCNN的0.00001的学习率太低了,即使在训练一周后,上述的网络也很难说收敛了,这也不能说明更深的网络不能带来更高的PSNR,至少说除SRCNN外,这种情况是可能发生的。
Adjustable Gradient Clipping:一定范围内(参考斋藤康毅的书)大的学习率能加快训练,但可能导致梯度消失和梯度爆炸(回头仔细看原因,参考文献8)。此时可用梯度裁减的技巧,将梯度控制在一定的范围内,如 [−θ, θ]。
梯度剪裁需要一定的技巧。我们首先要注意到的是,参数的减小量是学习率和梯度的乘积。因此在较大学习率时,只需要较小的梯度即可提供足够的下降,此时要求θ值较小,来避免梯度爆炸。但随着epoch的增加,学习率下降,此时若θ仍然较小,则可能带来很小的下降,进而需要多个epoch迭代来缓解θ下降慢的问题。
为了解决这个问题,使得不论多少个epoch(对应了学习率)都能保证不错的下降距离,我们可能需要一个动态的θ,并且这个θ应该和学习率成反比,因此可将θ改写为θ/γ,其中γ是学习率。
作者证明这种方法可以让原本训练几天的SRCNN,在4个小时完成收敛。
Multi-Scale:对于不同的图像分辨率放大因子,使用同一个网络,且网络参数是共享的。图像的预处理和SRCNN相似,都是用来patch的思想,不同点在于,SRCNN使用了在原图上重叠的patch而VDSR使用不重叠的patch。
Understanding Properties
本部分继续探索一下三个问题:
- deeper networks give better performances;
- residual-learning network converges much faster& learning rate;
- our method with a single network performs as well as a method using multiple networks trained for each scale。
The Deeper, the Better
优势:更大的感受野;模型将获得更复杂的非线性映射。
- 对于3X3的filter,第D层的感受野计算公式如下(2*D+1)**2
A large receptive field means thenetwork can use more context to predict image details. - 通过19层Relu可以产生更加复杂的非线性映射,能够拟合更加复杂的模型(不会发生过拟合么?)
对于不同深度的网络对网络精度的影响如下图:
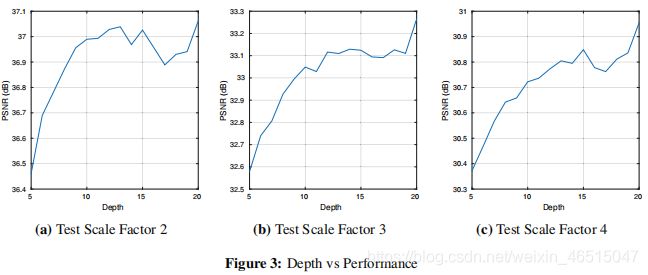
3幅图分别反映了不同的缩放因子下,不同深度的网络对精度的影响(仅计算权重参数而不计算Relu)。可以看出岁网络层数加深,网络表现能够得到提升。
Residual-Learning


- 残差学习能够收敛的非常快。
- 残差学习能够收敛到一个更高的PSNR。
- 如果使用0.1的学习率VDSR在10个epoch后的PSNR达到36.90。而使用0.001的学习率VDSR远不能在10个epoch后达到相同的值而在80个epoch后的PSNR才达到36.52。这在VDSR使用残差学习的纵向比较中说明了大的学习率的重要性(但如此大的学习率可能是与它的梯度裁减有关系的)。而在与不使用残差学习的VDSR的横向比较中,不使用残差学习的网络在学习率为0.1时10个epoch后的PSNR为27.42(这在一定程度上证明了残差学习在起作用作用而不是裁减梯度)
Single Model for Multiple Scales


用一种如scale3模型测试另一种如scale2的效果并不好,但用多种如scale2,scale3,scale4同时训练的模型(至少包括被测试图像的如scale2尺度即可)测试scale2的效果却很好,甚至超过仅用scale2训练的模型在测试scale2时的表现。因此一个网络通过多种scale训练后的模型能用很好的表现,且能处理多尺度的放大问题。
Experimental Results
和几个SOTA的比较
Datasets for Training and Testing
Training dataset:介绍了几个数据集,如91 images,291 images。作者采用291 images作为benchmark进行网络训练,处理数据时,进行rotation和flip。
Test dataset:使用四个数据集进行测试:‘Set5’ 、 ‘Set14’ ‘Urban100’、‘B100’。
Training Parameters
网络深度:20
batch size:64
momentum:0.9
weight decay parameter:0.0001
weight initialization:参考文献10
epoch:80
初始学习率0.1,每20个epoch衰减10倍,即80个epoch一共使用4中学习率。
Benchmark
Comparisons with State-of-the-Art Methods



Conclusion
- VDSR的一个重要缺点是在进入网络之前做图像的插值放大,这使得网络参数增大计算量增加。
- 这个网络可能能用在去噪、压缩图像去伪影等图像重建方向,值得尝试。
References
- Accurate Image Super-Resolution Using Very Deep Convolutional Networks
- 如何理解CNN中的感受野(receptive-field)?
- 什么是梯度下降法?_cf 动量的SGD
- Hessian矩阵
- 《深度学习入门-基于python的理论与实现》_cf p191(权值衰减)
- 正定矩阵
- 马鞍面
- Y. Bengio, P. Simard, and P. Frasconi. Learning long-term dependencies with gradient descent is difficult. Neural Networks, IEEE Transactions on, 5(2):157–166, 1994.
- CNN 感受野计算公式
- K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. CoRR, abs/1502.01852, 2015.