ABAP 几种数据汇总的代码示例
问题描述
根据id累加汇总income
数据示例:
TYPES:BEGIN OF ty_data,
name TYPE char10, " 姓名
income TYPE i, " 收入
id TYPE char10, " 身份证号
END OF ty_data.
DATA: lt_data TYPE TABLE OF ty_data,
lt_res TYPE TABLE OF ty_data,
ls_res TYPE ty_data,
lv_income TYPE i,
lv_start TYPE timestampl,
lv_end TYPE timestampl,
lv_time TYPE timestampl.
DATA: lo_random TYPE REF TO cl_abap_random,
lv_seed TYPE i,
lv_min_limit TYPE i,
lv_max_limit TYPE i,
lv_range_num TYPE i.
lv_min_limit = 1000.
lv_max_limit = 9999.
" 生成随机数据
DO 100000 TIMES.
lv_seed = cl_abap_random=>seed( ).
lo_random = cl_abap_random=>create( seed = lv_seed ).
lv_range_num = lo_random->intinrange( low = lv_min_limit high = lv_max_limit ).
APPEND VALUE #( id = lv_range_num name = 'random' income = 1 ) TO lt_data.
ENDDO.
" 按主键排序
SORT lt_data BY id.
方法一:循环比较前后数据
一个相当通配的思路解法,几乎任何语言都可以按这个思路去汇总数据
每次循环比较当前条和下一条数据的id是否一致
case1: 若一致则累加income
case2: 若不一致则append 到新表
循环至最后一条时无需比较,直接append
FORM frm_process1 .
LOOP AT lt_data INTO DATA(ls_data).
" 若ls_res 为空则赋值当前行
IF ls_res IS INITIAL.
MOVE-CORRESPONDING ls_data TO ls_res.
ENDIF.
" 读取第index+1条
READ TABLE lt_data INTO DATA(ls_next) INDEX ( sy-tabix + 1 ).
" 成功读取第index + 1条,即不是最后一行
IF sy-subrc = 0.
" CASE1 下一行和当前行id相同
IF ls_data-id = ls_next-id.
" 累加收入
ls_res-income = ls_res-income + ls_next-income.
" CASE2 下一行和当前行id不相同
ELSE.
" 追加累加行目至结果表
APPEND ls_res TO lt_res.
" 清空累加变量结构
CLEAR ls_res.
ENDIF.
" 没有读取到index + 1条,即最后一行
ELSE.
" 直接将最后一行追加到结果表
APPEND ls_data TO lt_res.
ENDIF.
ENDLOOP.
cl_demo_output=>display( lt_res ).
ENDFORM.
方法二:AT NEW… AT END OF…
这个方法有个弊端,进行比较的字段不能放在结构列表前面位置,必须放到最后一个才行,否则字符类型的数据会全部变成####…
结构之所以将id放在最后也是因为这个原因
AT NEW时初始化结果结构
中间对收入进行累加
AT END时append 至结果表并清空结构
LOOP AT lt_data INTO DATA(ls_data).
AT NEW id.
CLEAR ls_res.
ls_res = CORRESPONDING #( ls_data
EXCEPT
income ).
ENDAT.
ls_res-income = ls_res-income + ls_data-income.
AT END OF id.
APPEND ls_res TO lt_res.
ENDAT.
ENDLOOP.
方法三:LOOP…INTO…GROUP BY… REDUCE
分组循环组内使用REDUCE关键字汇总合计,写法稍微复杂而且可读性差而且效率低(是分组效率低,REDUCE效率很高)(只要别的开发看不懂不敢改,我就不会被开,笑死)
LOOP AT lt_data INTO DATA(ls_data) GROUP BY ( id = ls_data-id )
ASSIGNING FIELD-SYMBOL().
READ TABLE lt_data INTO ls_data WITH KEY id = -id BINARY SEARCH.
IF sy-subrc = 0.
lt_res = VALUE #( BASE lt_res
( REDUCE #( INIT
lw_res = CORRESPONDING #( ls_data
EXCEPT
income )
FOR ls_group IN GROUP
NEXT lw_res-income = lw_res-income + ls_group-income ) ) ).
ENDIF.
ENDLOOP.
cl_demo_output=>display( lt_res ).
方法四:COLLECT
最最最简单的写法了,一个collect全部搞定,可以把所有数值类型的字段进行汇总合计,但是效率尚可
LOOP AT lt_data INTO DATA(ls_data).
ls_res = CORRESPONDING #( ls_data ).
COLLECT ls_res INTO lt_res.
ENDLOOP.
cl_demo_output=>display( lt_res ).
比较
四种方法依次使用计时方法进行了运行计时,结果如下
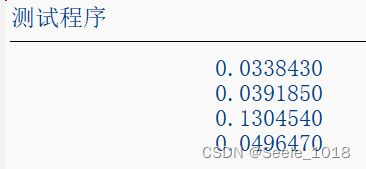

上午和下午分别运行了几次,结果偶有偏差
几个方法中除了REDUCE以外的效率都差不多
方案一脱离了所有汇总关键字完全使用基本语法,虽然代码量上去了但是效率还好。
方案二三代码量依次减少,使用起来方便但各自都有点问题,比如at new会出现#的问题,collect会汇总所有数值不够灵活。
方案四循环多了一步分组的操作导致效率大打折扣,因为单独测试一条汇总数据不使用GROUP BY时使用REDUCE的效率是最高的,只使用了上面三种方法一半不到的时间,使用新关键字REDUCE在写法上最灵活,但是对于不熟悉的人来说非常痛苦。
下面是单独测试一条数据汇总时的运行时长记录。

综合来看,如果只针对单条数据进行汇总计算,那么使用REDUCE的效率是最高的(尽量不在REDUCE中使用WHERE,会造成很大的效率问题);如果多条数据进行汇总计算,除REDUCE以外的几种方法均可