实战:使用Docker部署Hadoop集群
文章目录
-
- Hadoop简介
- Hadoop优势
- Hadoop应用场景
- docker与docker-compose安装
- Hadoop集群搭建
-
- 环境变量
- docker-compose
- 环境文件树结构
- 编排并运行容器
- 运行wordcount例子
- 写在最后
Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群进行高速运算和存储。Hadoop主要包含HDFS分布式文件系统和MapReduce映射规约,HDFS主要负责数据的分布式存储和管理;MapReduce的Map阶段负责任务分发各个集群节点计算获得中间结果,Reduce阶段负责将各个阶段的中间数据进行汇总获得结果。

Hadoop优势
1.高可靠性
2.高扩展性
3.高效性
4.高容错性
5.低成本
Hadoop应用场景
1、分布式存储
2、海量并行计算
3、大规模日志处理
4、ETL数据抽取、转换、装载
5、机器学习
6、搜索引擎
7、数据挖掘
docker与docker-compose安装
#安装docker社区版
yum install docker-ce
#版本查看
docker version
#docker-compose插件安装
curl -L https://github.com/docker/compose/releases/download/1.21.2/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
#可执行权限
chmod +x /usr/local/bin/docker-compose
#版本查看
docker-compose version
Hadoop集群搭建
环境变量
新建hadoop数据文件夹并赋予可读写权限
mkdir ./hadoop/data
chmod -R 777 ./hodoop
新增hadoop环境变量
vim ./hadoop.env
CORE_CONF_fs_defaultFS=hdfs://namenode:9000
CORE_CONF_hadoop_http_staticuser_user=root
CORE_CONF_hadoop_proxyuser_hue_hosts=*
CORE_CONF_hadoop_proxyuser_hue_groups=*
CORE_CONF_io_compression_codecs=org.apache.hadoop.io.compress.SnappyCodec
HDFS_CONF_dfs_webhdfs_enabled=true
HDFS_CONF_dfs_permissions_enabled=false
HDFS_CONF_dfs_namenode_datanode_registration_ip___hostname___check=false
YARN_CONF_yarn_log___aggregation___enable=true
YARN_CONF_yarn_log_server_url=http://historyserver:8188/applicationhistory/logs/
YARN_CONF_yarn_resourcemanager_recovery_enabled=true
YARN_CONF_yarn_resourcemanager_store_class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
YARN_CONF_yarn_resourcemanager_scheduler_class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___mb=8192
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___vcores=4
YARN_CONF_yarn_resourcemanager_fs_state___store_uri=/rmstate
YARN_CONF_yarn_resourcemanager_system___metrics___publisher_enabled=true
YARN_CONF_yarn_resourcemanager_hostname=resourcemanager
YARN_CONF_yarn_resourcemanager_address=resourcemanager:8032
YARN_CONF_yarn_resourcemanager_scheduler_address=resourcemanager:8030
YARN_CONF_yarn_resourcemanager_resource__tracker_address=resourcemanager:8031
YARN_CONF_yarn_timeline___service_enabled=true
YARN_CONF_yarn_timeline___service_generic___application___history_enabled=true
YARN_CONF_yarn_timeline___service_hostname=historyserver
YARN_CONF_mapreduce_map_output_compress=true
YARN_CONF_mapred_map_output_compress_codec=org.apache.hadoop.io.compress.SnappyCodec
YARN_CONF_yarn_nodemanager_resource_memory___mb=16384
YARN_CONF_yarn_nodemanager_resource_cpu___vcores=8
YARN_CONF_yarn_nodemanager_disk___health___checker_max___disk___utilization___per___disk___percentage=98.5
YARN_CONF_yarn_nodemanager_remote___app___log___dir=/app-logs
YARN_CONF_yarn_nodemanager_aux___services=mapreduce_shuffle
MAPRED_CONF_mapreduce_framework_name=yarn
MAPRED_CONF_mapred_child_java_opts=-Xmx4096m
MAPRED_CONF_mapreduce_map_memory_mb=4096
MAPRED_CONF_mapreduce_reduce_memory_mb=8192
MAPRED_CONF_mapreduce_map_java_opts=-Xmx3072m
MAPRED_CONF_mapreduce_reduce_java_opts=-Xmx6144m
MAPRED_CONF_yarn_app_mapreduce_am_env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
MAPRED_CONF_mapreduce_map_env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
MAPRED_CONF_mapreduce_reduce_env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
TEZ_CONF_tez_lib_uris=hdfs://namenode:9000/tez/tez,hdfs://namenode:9000/tez/tez/lib
TEZ_CONF_tez_lib_uris_classpath=hdfs://namenode:9000/tez/tez,hdfs://namenode:9000/tez/tez/lib
TEZ_CONF_tez_use_cluster_hadoop___libs=true
TEZ_CONF_tez_history_logging_service_class=org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService
docker-compose
新增docker-compose编排文件
vim docker-compose-hadoop.yaml
version: '3'
services:
namenode:
image: registry.cn-hangzhou.aliyuncs.com/senfel/hadoop-namenode:2.0.0-hadoop3.2.1-java8
container_name: namenode
hostname: namenode
restart: always
ports:
- 9000:9000
- 9870:9870
volumes:
- ./hadoop/data/hadoop_namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
networks:
- hadoop_net
resourcemanager:
image: registry.cn-hangzhou.aliyuncs.com/senfel/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8
container_name: resourcemanager
hostname: resourcemanager
restart: always
ports:
- "8088:8088"
depends_on:
- namenode
- datanode1
- datanode2
- datanode3
env_file:
- ./hadoop.env
networks:
- hadoop_net
historyserver:
image: registry.cn-hangzhou.aliyuncs.com/senfel/hadoop-historyserver:2.0.0-hadoop3.2.1-java8
container_name: historyserver
restart: always
hostname: historyserver
ports:
- "8188:8188"
depends_on:
- namenode
- datanode1
- datanode2
- datanode3
volumes:
- ./hadoop/data/hadoop_historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
networks:
- hadoop_net
nodemanager:
image: registry.cn-hangzhou.aliyuncs.com/senfel/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8
restart: always
container_name: nodemanager
hostname: nodemanager
depends_on:
- namenode
- datanode1
- datanode2
- datanode3
env_file:
- ./hadoop.env
ports:
- "8042:8042"
networks:
- hadoop_net
datanode1:
image: registry.cn-hangzhou.aliyuncs.com/senfel/hadoop-datanode:2.0.0-hadoop3.2.1-java8
restart: always
container_name: datanode1
hostname: datanode1
depends_on:
- namenode
ports:
- "5642:5642"
volumes:
- ./hadoop/data/hadoop_datanode1:/hadoop/dfs/data
env_file:
- ./hadoop.env
environment:
- HDFS_CONF_dfs_datanode_address=0.0.0.0:5640
- HDFS_CONF_dfs_datanode_ipc_address=0.0.0.0:5641
- HDFS_CONF_dfs_datanode_http_address=0.0.0.0:5642
networks:
- hadoop_net
datanode2:
image: registry.cn-hangzhou.aliyuncs.com/senfel/hadoop-datanode:2.0.0-hadoop3.2.1-java8
restart: always
container_name: datanode2
hostname: datanode2
depends_on:
- namenode
ports:
- "5645:5645"
volumes:
- ./hadoop/data/hadoop_datanode2:/hadoop/dfs/data
env_file:
- ./hadoop.env
environment:
- HDFS_CONF_dfs_datanode_address=0.0.0.0:5643
- HDFS_CONF_dfs_datanode_ipc_address=0.0.0.0:5644
- HDFS_CONF_dfs_datanode_http_address=0.0.0.0:5645
networks:
- hadoop_net
datanode3:
image: registry.cn-hangzhou.aliyuncs.com/senfel/hadoop-datanode:2.0.0-hadoop3.2.1-java8
restart: always
container_name: datanode3
hostname: datanode3
depends_on:
- namenode
ports:
- "5648:5648"
volumes:
- ./hadoop/data/hadoop_datanode3:/hadoop/dfs/data
env_file:
- ./hadoop.env
environment:
- HDFS_CONF_dfs_datanode_address=0.0.0.0:5646
- HDFS_CONF_dfs_datanode_ipc_address=0.0.0.0:5647
- HDFS_CONF_dfs_datanode_http_address=0.0.0.0:5648
networks:
- hadoop_net
networks:
hadoop_net:
driver: bridge
环境文件树结构
├── docker-compose-hadoop.yaml
├── hadoop
│ └── data
├── hadoop.env
编排并运行容器
1、编排
docker-compose -f docker-compose-hadoop.yaml up -d
Creating namenode … done
Creating datanode3 … done
Creating datanode2 … done
Creating datanode1 … done
Creating nodemanager … done
Creating resourcemanager … done
Creating historyserver … done
2、查看运行容器
docker ps

3、Hadoop web页面
hdfs健康信息 http://10.10.22.91:9870

hadoop集群信息 http://10.10.22.91:8088/

运行wordcount例子
# 进入namenode容器
docker exec -it namenode bash
#进入测试demo WordCount程序
cd /opt/hadoop-3.2.1/share/hadoop/mapreduce
# 在namenode容器里创建目录和2个文件
mkdir input
echo "this is a hadoop test example" > input/f1.txt
echo "my name is a senfel" > input/f2.txt
echo "good study day day up" > input/f3.txt
# 在HDFS创建一个input目录(绝对路径为/user/root/input)
hdfs dfs -mkdir -p input
# 把容器/input目录下的所有文件拷贝到HDFS的input目录,如果HDFS的input目录不存在会报错
hdfs dfs -put ./input/* input
# 在容器里运行WordCount程序,该程序需要2个参数:HDFS输入目录和HDFS输出目录
# 需要保证dfs中output文件夹不存在
hadoop jar hadoop-mapreduce-examples-3.2.1.jar wordcount input output
# 打印输出刚才运行的结果,结果保存到HDFS的output目录下
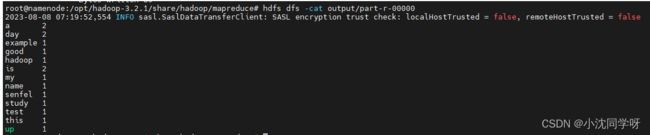
hdfs dfs -cat output/part-r-00000
写在最后
用docker方式部署hadoop集群较普通物理更为简单,且方便管理。本次实战过程用的bridge网络,如果需要远程访问hdfs则是需要用host网络构建容器。