k8s 自身原理之高可用
说到高可用,咱们在使用主机环境的时候(非 k8s),咱做高可用有使用过这样的方式:
- 服务器做主备部署,当主节点和备节点同时存活的时候,只有主节点对外提供服务,备节点就等着主节点挂了之后,立刻补位
- 另外为了提供服务的可用性,做了异地多活,增加服务的接入节点,对流量进行分流等
- 对于数据库同样也是做备份,定期同步,热备或者冷备
那么前面分享了那么多的关于 k8s 自身组件的原理,咱们可以回过来头看,我们为什么要选择 k8s ?
简单来说还是因为 k8s 自身的特性:
- 自身满足负载均衡
- 服务自愈
- 管理的服务还可横向扩容
- 升级的时候,能够滚动升级,平滑过渡,整个升级过程能够做到非常的丝滑,
- 若中间出现升级异常,还可以一键回滚,在回滚过程中,亦不影响原有服务
这一切的一切,咱们在主机环境都是需要耗费很大的人力成本去做的事情,因而,最终才会选择服务部署在 k8s 上面,可以极大的减少开发和运维的心智负担和运维成本
那么上述说的这么好, k8s 是如何保障高可用的呢?
高可用我们可以从哪些方面思考呢?
从 pod 来看
从 pod 来看高可用的话,前面我们有说到 pod 可以通过使用高级资源 Deployment 来进行管理,创建,更新,删除 pod ,使用 Deployment 都可以进行平滑的升级和回滚
当然默认说的这种方式是无状态的 pod
如果咱们是的服务是有状态的,运行在 pod 中,咱们仍然可以使用 Deployment ,但是只能有 1 个副本,否则会有影响
如果带有数据卷的时候,咱们也可以使用 StatefulSet 资源来进行管理
但是若咱们的 pod 挂掉,咱们在 pod 重启到可以对外提供服务的过程中,服务会中断一段时间
有状态服务,无法水平扩展的高可用方式
有状态的服务,无法水平扩展,咱们也可以像最开始我说到的使用主备的这种做法来进行处理
类似的,我们可以使用领导选举机制,来将多个同样的有状态服务中选举一个服务来对外处理请求
直到这个服务出现异常而宕机之后,使用同样的方式,来在剩下的服务中选举出一个有效的服务,来处理外来请求
具体的算法和 k8s 中的实现方式,我会在后面的文章中进行分享
从 etcd 来看
etcd ,咱们是使用主机环境的时候也有使用过 etcd
主要是用来存放服务配置,和用来做服务发现的,key 值是服务的目录或者带有 / 的字符串, value 的话,则是服务的 ip 和 端口
**etcd 本身就被设计成一个分布式的系统,**本身就可以运行多个 etcd 实例,天生做高可用就是很容易的事情
一般做集群,咱们会部署 3 个,5个 或者是 7 个,原因的话**,可以尝试去看看 redis 集群部署一章的分享**
可以看这个简图:
多 master ,多 worker 的简图
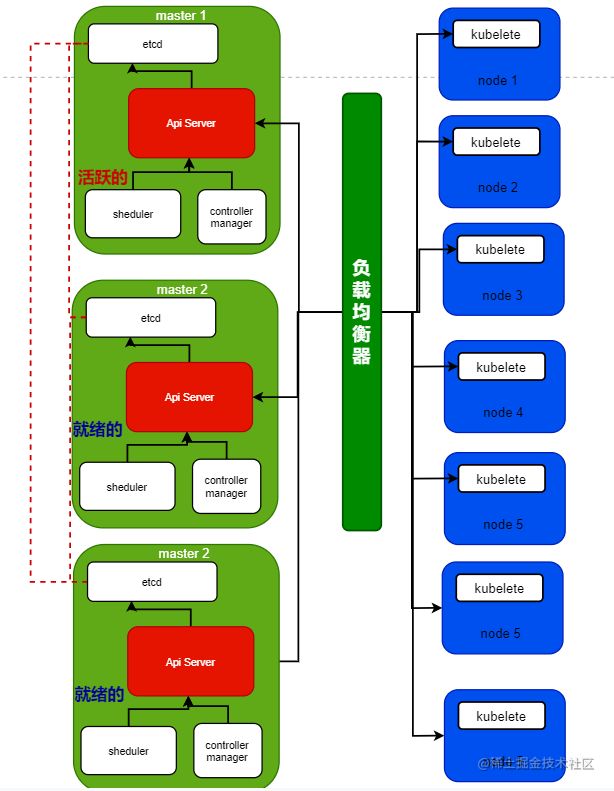
从 ApiServer 来看
从 ApiServer 来看的话,那就更简单的
这个组件本身无状态,且不缓存数据,他会直接和 自己独立的 etcd 进行通信,对于节点里面的组件,请求给到哪一个 master 里面的 ApiServer 都是可以的
因为 ApiServer 后面的 etcd 组件是分布式的,他们的数据是会跨实例复制数据的
在多 master 的时候,worker 和主节点通信的时候,是要经过一个负载均衡器的,这可以让多个节点的流量进行分流,同时还可以保证 worker 的请求可以正确的打到健康的 ApiServer 上
从 调度器 scheduler 和控制器管理器 controller manager 来看
对于 scheduler 和控制器管理器相对就没有 ApiServer 那么简单和方便,因为他们会涉及资源管理的冲突
对于他们来说,他们大部分都是在做监听工作,当有多个控制器监听了到 ApiServer 的中的资源变化
那么,例如 3 个 ReplicaSet 控制器,都监听了 ApiServer 将其对应的副本数增加 2 个
这个时候,3 个 ReplicaSet 控制器 都监听了,为了满足期望,他们便会做满足期望的事情,最终,环境里面会新产生 6 个 pod
自然,这是我们所不期待的,这样搞岂不是乱套了,浪费资源
因此 对于控制器管理器和调度器和他们都会积极的监听集群的状态,为了避免不良竞争,还是要选用上述的类似主备的思想
给他们使用 –leader-elert 选项 , 默认会进行选主,谁是主,谁就做实际的动作,做监听之后需要做的事情,其他的就等着这个主 寿终正寝
好了,今天就是这样
今天就到这里,学习所得,若有偏差,还请斧正
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hmdHOASE-1692190405468)(https://gitee.com/common_dev/mypic/raw/master/97eedfade9134b669f0fe40cd73d2cd5~tplv-k3u1fbpfcp-zoom-1.image)]
好了,本次就到这里
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~
更多的可以查看 零声每晚八点直播:https://ke.qq.com/course/417774