C++STL实现原理
前言
万字长文记录STL常见容器底层实现原理。
推荐阅读:《STL源码剖析》
| 层级 | 类 |
|---|---|
| 第八层 | unordered_map.h、unordered_set.h |
| 第七层 | algorithm.h、astring.h、hashtable.h、map.h、queue.h、set.h、stack.h |
| 第六层 | algo.h、basic_string.h、deque.h、lish.h、rb_tree.h、vector.h |
| 第五层 | memory.h |
| 第四层 | allocator.h、uninitialized.h |
| 第三层 | algobase.h、construct.h、heap_algo.h、numeric.h、set_algo.h |
| 第二层 | iterator.h、util.h |
| 第一层 | exceptdef.h、functional.h、type_traits.h |
| 底层 | cstddef、ctime、cstring、new、iostream、initializer_list、stdexcept、cassert、cstdlib、climits、type_traits |
表格中,加粗部分是自己写过的,红黑树以及set、map没有写。有些头文件里面的内容比较简单,本文就简单提一提,不做多余说明。
本人写的过程中采用valgrind
文章目录
- 前言
- 一、什么是STL,包括那些?
-
- template实例化与特化
- 二、type_traits.h
- 三、functional.h
-
- 3.1 什么是仿函数?
- 3.2 仿函数跟普通函数比,有什么优点?
- 3.3 hash函数对象
- 3.4 function template参数推导
- 四、exceptdef.h
-
- 4.1 什么是异常安全?
- 五、util.h
-
- 5.1 什么是万能引用
- 5.2 什么是引用折叠
- 5.3什么是移动语义和完美转发
- 六、iterator.h
-
- 6.1 迭代器有几种类型,分别有什么特点?
- has_iterator_cat
- 七、construct.h
-
- 7.1 `new`、`placement new`、`operator new`的区别与联系
- 八、allocator.h
-
- 8.1 `allocate、deallocate`和`construct、destroy`
- 8.2 `new/delete`和`malloc/free`的区别
- 九、algobase.h
-
- 9.1 `*p++`和`*++p`的结果
- 9.2 explicit关键字
- 十、algo_heap.h
-
- 10.1 什么是堆排序
- 十二、numeric.h
- 十三、set_algo.h
- 十四、uninitialized.h
-
- 14.1 浅拷贝和深拷贝的区别
- 十五、memory.h
-
- 15.1`ptrdiff_t`和`size_t`
- 15.2什么是智能指针
- 十六、vector.h
-
- 16.1 vector最大可申请空间是多少?
- 16.2 `at()`和`operator[]()`的区别
- 16.3 vector的扩容机制
- 16.4 什么是迭代器失效?vector中可能造成失效的函数
- 16.5 `resize()`和`reserve()`的区别
- 16.6 vector的元素类型可以是引用吗?
- 16.7 const可以用于函数重载吗?
- 十七、algo.h
-
- 17.1 `random_shuffle`
- 17.2 `premutation`
- 17.3 `sort`
- 十八、list.h
-
- 18.1 什么是lamba?
- 18.2 list.splice函数
- 十九、deque.h
- 二十、basic_string.h
-
- 20.1 POD类型
- 20.2 `friend function`
- 二十一、hashtable.h
- 二十二、unordered_set.h
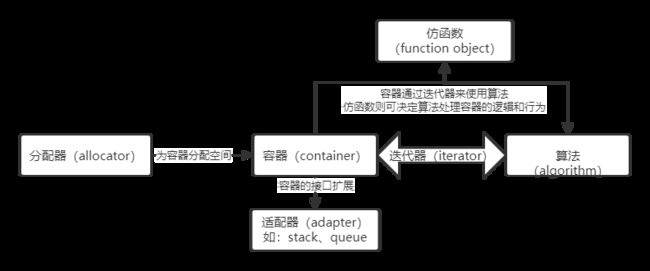
一、什么是STL,包括那些?
标准模板库(standard template library)
STL主要有:容器、算法、迭代器、适配器、分配器、仿函数
template实例化与特化
void swap(int &a, int &b){} // 普通的函数
template<class T> void swap(T &a, T &b){} // 模板
template<> void swap<int>(int &a, int &b)
{自己再具体实现,与模板的逻辑不同} // 特化的模板函数
template void swap<int>(int &a, int &b); // 显式实例化,这个只用声明就行,提高效率
实例化:用具体类型去代替模版的参数这一行为,代码逻辑没有改变。
特化:由于某种类型的逻辑需要特殊考虑,模版的范型不能描述。所以对这种特殊情况需要单独写一个特例模版。
二、type_traits.h
此头文件用于提取类型信息。
template <class T, T v>
struct integral_constant
{
static constexpr T value = v;//设置为static才能直接访问,属于所有对象共享的数据
};
template <bool b>
using bool_constant = integral_constant<bool, b>;
typedef bool_constant<true> true_type;
typedef bool_constant<false> false_type;
false_type true_type 是integral_constant模板类的实例化。
这两个类是为后面模板函数和模板类在不同类型和条件下执行不同代码而准备的。
三、functional.h
此头文件包含常见仿函数与hash函数对象。
3.1 什么是仿函数?
仿函数也叫函数对象,就是一个类,重载了operator(),因此表现出像一个函数一样。
3.2 仿函数跟普通函数比,有什么优点?
- 仿函数可以拥有自己的数据成员和成员变量,这意味着这意味着仿函数拥有状态。而普通函数没有。
- 每个仿函数有自己的型别。
- 仿函数通常比一般函数有更快的速度。在编译期就可确定。
例子:有些算法只能传入unary_function,如果想传入binary_function,普通函数无法做到。而仿函数可以使用成员变量来记录第二个参数,使用有参构造函数来传入。
vector<string> vec;
//统计长度小于len的string的个数
bool lengthlessthan(string& str,int len)
{
return str.length()<len;
}
int res=count_if(vec.begin(),vec.end(),lengthlessthan);
//可以看到,count_if只能传入unary_function,因此会报错
class lengthcount
{
public:
lengthcount(int maxlen):len(maxlen){}
bool operator()(string& str) const {
return str.length<len;
}
private:
int len;
};
res=count_if(vec.begin(),vec.end(),lengthcount(length));
3.3 hash函数对象
/*对于大部分类型,hash function 什么都不用做*/
template<typename T>
struct hash {};
/*针对指针的特化*/
template<typename T>
struct hash<T*>
{
size_t operator()(T* p) const noexcept
{
return reinterpret_cast<size_t>(p);
}
};
/* 对于整型,只是返回原值 特化*/
#define TRIVIAL_HASH_FUN(Type) \
template<> struct hash<Type> \
{ \
size_t operator()(Type val) const noexcept \
{ return static_cast<size_t>(val); } \
};
3.4 function template参数推导
//获得template中迭代器所指之物的型别
template<typename I, typename T>
void func_impl(I iter, T t)
{
T tmp;//这里解决了问题,T就是迭代器所指之物的型别
// ........这里做原本func()应该做的全部工作
}
template<typename I>
void func(I iter)
{
func_impl(iter, *iter);//func的工作全部转移到func_impl中
}
四、exceptdef.h
#include标准的异常类
std::length_error(what)
std::out_of_range(what)
std::runtime_error(what)
#include断言
4.1 什么是异常安全?
当程序在异常发生的时候,程序可以回退的很干净——函数在发生异常的时候不会泄露资源或者不会发生任何数据结构的破坏。
异常安全分为三个级别:
- 基本级别:可能发生异常,且在异常发生的时候代码保证做了任何必要的清理工作,即程序在合法阶段,但是一些数据结构可能已经被函数更改,不一定是调用之前的状态,基本是保证符合对象正常的要求的;
- 强烈级别:可能发生异常,且在发生异常时代码保证函数对数据做的任何修改都可以被回滚。即如果调用成功,则完全成功;如果调用失败,则对象依旧是调用之前的状态;
- 无异常:即函数保证不会抛出异常(比如标准库的swap函数等)。
资源泄漏问题解决方案
对于资源泄漏问题,解决方案是我们可以用对象来管理资源(即RAII技术,对于指针变量,也可以使用RAII技术进行管理)
数据破坏问题解决方案
对于数据破坏问题,一个策略是copy and swap。就是:先对原对象作出一个副本,在副本上作必要的修改。如果出现任何异常,原对象仍然能保持不变
五、util.h
包含通用工具: move forward swap等函数,以及pair等。
5.1 什么是万能引用
与右值引用写法相同:T&&
当有类型推导时为万能引用,既可以为左值引用又可以为右值引用
万能引用中的T,推导的是表达式的值类型,当传入左值时,T推导为T&;当传入一个右值时,T推导为T&&
5.2 什么是引用折叠
只有T&& &&才会折叠为T&&;其余均为T&(如:T& &&、T&& &)
5.3什么是移动语义和完美转发
/* move 移动 右值引用*/
template<typename T> //这里的参数就是万能引用,T既能被推导为T&又能被推导为T&&
typename std::remove_reference<T>::type&& move(T&& arg) noexcept
{
return static_cast<typename std::remove_reference<T>::type&&>(arg);
}
/* forward 完美转发*/
/*右值传入函数后会变为左值
为了使传入的右值始终为右值
forward()可以完成,并且传入左值不改变*/
template<typename T> //传入左值,T推导为T&
T&& forward(typename std::remove_reference<T>::type& arg) noexcept
{ //引用折叠 T& && -> T&
return static_cast<T&&>(arg);
}
template<typename T> //传入右值,T推导为T&&
T&& forward(typename std::remove_reference<T>::type&& arg) noexcept
{
static_assert(!std::is_lvalue_reference<T>::value, "bad forward");
//引用折叠 T&& && -> T&&
return static_cast<T&&>(arg);
}
六、iterator.h
此头文件为迭代器设计
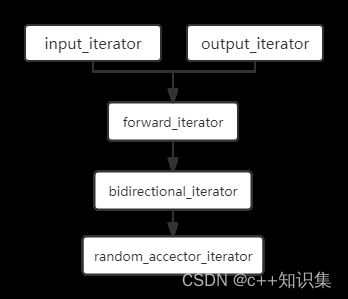
6.1 迭代器有几种类型,分别有什么特点?
有五种类型:
input_iterator:读元素,也就是解引用只能出现在赋值运算符的右边。只能用于单边扫描算法。
output_iterator:写元素,也就是解引用只能出现在赋值运算符的左边。只能用于单边扫描算法。
forward_iterator:输入迭代器与输出迭代器操作的结合。可用于多遍扫描算法。
bidirectional_iterator:支持所有前向迭代器操作的基础上,支持递减运算符,也就是支持双向移动。可用于多遍扫描算法。
random_access_iterator:在支持双向移动的基础上,支持前后位置的比较、随机存取、直接移动n个距离。可用于多遍扫描算法。
has_iterator_cat
template <class T>
struct has_iterator_cat
{
private:
struct two { char a; char b; };
template <class U> static two test(...);
template <class U> static char test(typename U::iterator_category* = 0);
public:
static const bool value = sizeof(test<T>(0)) == sizeof(char);
};
用于判断是迭代器还是普通指针。
重载两个test函数,但无需实现,主要是在实例化的时候,根据模板失败而非错误,判断T::iterator_category是否存在,如果不存在则第二个test函数不会实例化成功,此时value为false,反之true
迭代器萃取(总结的不好):

七、construct.h
此头文件包含两个函数:
- construct:负责对象构造
- destroy:负责对象析构
7.1 new、placement new、operator new的区别与联系
new为操作符,无法被重载,通常说的重载其实是operator new(此为函数,因此可被重载)
假设有一个class A;
A* a=new A;分为三步:
(1)调用operator new分配内存,operator new (sizeof(A))
(2)调用构造函数生成类对象,A::A()
(3)返回分配指针
placement new本质上是对operator new的重载:
new(ptr) A();它不分配内存,调用合适的构造函数在ptr所指的地方构造一个对象,之后返回实参指针ptr。用于需要反复创建并删除的对象上,可以降低分配释放内存的性能消耗。
/*construct 构造对象*/
template<typename T>
void construct(T* ptr)
{ //使用placement new:指定在ptr地址上构造对象
//并没有分配内存,即默认ptr地址有足够的内存空间
::new ((void*)ptr) T();
}
八、allocator.h
此头文件包含一个模板类allocator,用于管理内存分配,释放,对象的构造、析构。
8.1 allocate、deallocate和construct、destroy
allocate():使用operator new向系统申请一个内存空间
construct():使用placement new在allocate()中的一个位置上构造对象并初始化其值
deallocate:使用operator delete释放内存
destroy:调用对象的析构函数,内存空间还在
8.2 new/delete和malloc/free的区别
| 特征 | new/delete | malloc/free |
|---|---|---|
| 分配内存的位置 | 自由存储区 | 堆 |
| 内存分配成功返回值 | 完整类型指针 | void* |
| 内存分配失败返回值 | 默认抛出异常 | 返回NULL |
| 分配内存的大小 | 由编译器根据类型计算得出 | 必须显式指定字节数 |
| 处理数组 | 有处理数组的new版本new[] | 需要用户计算数组的大小后进行内存分配 |
| 已分配内存的扩充 | 无法直观地处理 | 使用realloc简单完成 |
| 是否相互调用 | 可以,看具体的operator new/delete实现 | 不可调用new |
| 分配内存时内存不足 | 客户能够指定处理函数或重新制定分配器 | 无法通过用户代码进行处理 |
| 函数重载 | 允许 | 不允许 |
| 构造函数与析构函数 | 调用 | 不调用 |
九、algobase.h
此头文件包含基本算法
9.1 *p++和*++p的结果
*p++:先解引用*p,然后++
*++p:先p++,然后解引用
运算规律:
- 1.如果 *和++/–都在指针变量的左边,结合方向为从右到左;
- 2.如果 *和++/–分别在指针变量的左边/右边,结合方向为从左到右;
- 3.有括号的先执行括号的表达式,然后在执行规律 1 或者规律 2;
9.2 explicit关键字
explicit关键字:只能修饰只有一个参数的构造函数,或者有多个参数,但是除第一个参数外其他的参数都有默认值。它的作用是表明必须显式调用构造函数。
此关键字只能对用户自己定义的对象起作用,不对默认构造函数起作用。
此关键字只能够修饰构造函数。而且构造函数的参数只能有一个。
1、何时用explicit
当我们不希望自动类型转换的时候用,标准库好多构造函数都是explicit的。
比如说vector //这种定义看起来一目了然
不能写成vector//此种定义让程序员感到疑惑。
2、何时不用explicit
当我们需要隐式转换的时候。比如说String类的一个构造函数String(const char*);
十、algo_heap.h
此头文件包含heap的四个算法:
push_heap:自底向上调整
pop_heap:自顶向下调整一次,再自底向上调整一次
sort_heap:不断pop_heap即可
make_heap:从尾到头,不断进行adjust_heap
10.1 什么是堆排序
大顶堆:
//自上向下调整,从start位置开始向下g调整
void heap_adjust(vector<int>& nums,int start,int end)
{
int parent=start;
int child=parent*2+1;
while(child<=end)
{
if(child+1<=end&&nums[child+1]>nums[child])
child++;
if(nums[parent]>nums[child])
return;
swap(nums[parent],nums[child]);
parent=child;
child=parent*2+1;
}
}
void heap_sort(vector<int>& nums,int len)
{
//建堆
for(int i=len/2-1;i>=0;--i)
heap_adjust(nums,i,len-1);
for(int i=len-1;i>=0;--i)
{
swap(nums[0],nums[i]);
heap_adjust(nums,0,i-1);
}
}
这个实现应该算最简单的了,比较容易记。只需要写一个从上向下调整的函数heap_adjust,然后直接在heap_sort函数里,自下向上建堆。然后交换堆顶和堆尾,再调用heap_adjust函数就行。
十二、numeric.h
此头文件包含了数值算法,比较简单。
十三、set_algo.h
此头文件包含set的四种算法:
union:S1 U S2
intersection:S1 n S2
difference:S1 - S2
symmetric_difference:(S1 - S2) U (S2 - S1)
所有函数都要求序列有序。
十四、uninitialized.h
此头文件用于在未初始化空间上构造元素。
初始化对象需要区分浅拷贝和深拷贝。
14.1 浅拷贝和深拷贝的区别
假如对象里面有一个指针,指针指向了一块内存。
浅拷贝只能拷贝指针,其指向的仍然是原内存
深拷贝创建一个一模一样的对象,新指针指向新内存,新内存中的内容与原内存相同。
十五、memory.h
此头文件负责更高级的动态内存管理,包含一些基本函数、空间配置器、未初始化的储存空间管理,以及一个模板类auto_ptr。
15.1ptrdiff_t和size_t
ptrdiff_t类型变量通常用来保存两个指针减法操作的结果类型。
size_t 类型用于指明数组长度,它必须是一个正数;ptrdiff_t 类型则应保证足以存放同一数组中两个指针之间的差距,它有可能是负数。
difference_type是signed类型,表示迭代器差距,vector
ptrdiff_t与difference_type区别,前面的是c++定义的标准,后面则是STL定义的。
15.2什么是智能指针
智能指针其实是一个类,可以通过将普通指针作为参数传入智能指针的构造函数实现绑定。只不过通过运算符重载让它“假装”是一个指针,也可以进行解引用等操作。既然智能指针是一个类,对象都存在于栈上,那么创建出来的对象在出作用域的时候(函数或者程序结束)会自己消亡,所以在这个类中的析构函数中写上delete就可以完成智能的内存回收。
auto_ptr:独享、const reference是智能指针作为参数传递的底线、有很多问题。 不支持复制(拷贝构造函数)和赋值(operator =),但复制或赋值的时候不会提示出错。因为不能被复制,所以不能被放入容器中。
unique_ptr:替代了auto_ptr、也不支持复制和赋值,但比auto_ptr好,直接赋值会编译出错。实在想赋值的话,需要使用:std::move。
shared_ptr:多个指针指向相同的对象。shared_ptr使用引用计数,每一个shared_ptr的拷贝都指向相同的内存。每使用他一次,内部的引用计数加1,每析构一次,内部的引用计数减1,减为0时,自动删除所指向的堆内存。shared_ptr内部的引用计数是线程安全的,但是对象的读取需要加锁。
weak_ptr:引用计数有一个问题就是互相引用形成环,这样两个指针指向的内存都无法释放。需要手动打破循环引用或使用weak_ptr。顾名思义,weak_ptr是一个弱引用,只引用,不计数。如果一块内存被shared_ptr和weak_ptr同时引用,当所有shared_ptr析构了之后,不管还有没有weak_ptr引用该内存,内存也会被释放。所以weak_ptr不保证它指向的内存一定是有效的,在使用之前需要检查weak_ptr是否为空指针。
十六、vector.h
此头文件包含一个模板类vector,默认构造分配16个元素大小。
//成员变量
iterator begin_; /*表示目前使用空间的头部*/
iterator end_; /*表示目前使用空间的尾部*/
iterator cap_; /*表示目前储存空间的尾部*/
//成员函数
/*迭代器相关操作*/
begin();
end();
rbegin();//反向
rend();
cbegin();//const begin
cend();
/*容量相关操作*/
empty();
size();
max_size();//vector容器最大可申请的空间
capacity();
reserve(size_type n);
shrink_to_fit();
/*访问元素相关操作*/
operator[](size_type n);//可能超出边界,但不会报错
at(size_type n);//会在运行时捕获非法索引
front();
back();
data();//返回vector首地址
/*修改容器相关操作*/
assign(size_type n, const value_type& value);//赋值,会覆盖原来的数据
assign(Iter first, Iter last);
emplace(const_iterator pos, Args& ...args);
emplace_back(Args& ...args);
push_back(const value_type& value);
push_back(value_type&& value);//调用emplace_back(),并使用move()转化为右值
pop_back();
insert(const_iterator pos, const value_type& value);
insert(const_iterator pos, value_type&& value);//调用emplace(),并使用move()转化为右值
insert(const_iterator pos, size_type n, const value_type& value);
insert(const_iterator pos, Iter first, Iter last);
erase(const_iterator pos);
erase(const_iterator first, const_iterator last);
clear() { erase(begin(), end()); }
resize(size_type new_size)
{ return resize(new_size, value_type()); }
resize(size_type new_size, const value_type& value);
reverse();
swap(vector& rhs);
16.1 vector最大可申请空间是多少?
size_type max_size() const noexcept
{ return static_cast<size_type>(-1) / sizeof(T); }
size_type为size_t 是无符号整数,一般为32位。
max_size()是vector最大可以申请到的空间,-1采用的补码形式因此所有位全为1,然后强制类型转换为无符号整数,最后除以T类型的大小便可以得到最大能够申请到的空间。
16.2 at()和operator[]()的区别
vec.v[]和vec.at()都可以对vec中元素进行访问,并且访问元素时都不能越界,比如vec有10个元素,则vec[10]或vec.at(10)这样的使用会报错。
区别在于,operator[]不做边界检查, 哪怕越界了也会返回一个引用,当然这个引用是错误的引用,如果不小心调用了这个引用对象的方法,会直接导致应用退出。而由于at会做边界检查,如果越界,会抛出异常,应用可以try catch这个异常,那么应用还能继续运行。
16.3 vector的扩容机制
申请新空间,拷贝元素,释放旧空间。
项目中vector扩容采用1.5倍扩容:
当扩容的倍数为2的时候,那么这个扩容容量总是大于之前所有的扩容总和,这样的话,之前扩容的空间不能使用,这样对缓存并不友好。因此选定的倍数应该是1到2之间。
选择1.5的原因应该是:不至于太浪费内存空间,有可能使用之前释放过的空间,同时也不需要太多次的赋值数组内容。
有些采用2倍的原因:我能查到的理由是,均摊时间复杂度最低。
16.4 什么是迭代器失效?vector中可能造成失效的函数
迭代器失效:因一些操作,导致容器原先内存空间变化,而迭代器所指位置还是原来的内存空间,从而造成迭代器不再指向容器中的有效位置。
insert:可能造成插入位置及之后位置的迭代器失效,如果超过capacity,则会重新分配内存,造成所有位置迭代器失效。
erase:删除位置及之后位置的迭代器失效。
其实,只要是可能造成元素位置相对改变的或者容器重新分配内存,都可能使迭代器失效,比如assign、resize、swap等等
16.5 resize()和reserve()的区别
其实根据函数名也可以进行一些区分。
- reserve是预留,保留的意思,调用此函数就可以提前告诉vector容器需要准备的空间大小,其参数只有一个n,改变的是capacity。从而可以减少多次开辟、释放空间的问题。
- resize主要是改变size的,即想要使用的空间大小,此函数可以有多个参数,如果其参数n大于了capacity,则会重新分配内存,capacity和size都会被改变。
16.6 vector的元素类型可以是引用吗?
vector的底层实现要求连续的对象排列,引⽤并非对象,没有实际地址,因此vector的元素类型不能是引⽤。
可以是指针。
16.7 const可以用于函数重载吗?
const可用于重载,但参数中的const要分情况才能重载:
fun(int i) 和 fun(const int i),不能重载
二者是一样的,是因为函数调用中存在实参和形参的结合。假如我们用的实参是 int a,那么这两个函数都不会改变 a 的值,这两个函数对于 a 来说是没有任何区别的,所以不能通过编译,提示重定义。
fun(char *a) 和 fun(const char *a),可以重载
因为 char *a 中 a 指向的是一个字符串变量,而 const char *a 指向的是一个字符串常量,所以当参数为字符串常量时,调用第二个函数,而当函数是字符串变量时,调用第一个函数。
fun(char *a) 和fun(char * const a) ,不能重载
这两个都是指向字符串变量,不同的是 char *a 是指针变量 而 char* const a 是指针常量,这就和 int i 和 const int i 的关系一样了,所以也会提示重定义。
const在成员函数的重载
在成员函数声明那一行的末尾有无const,const 函数重载可看做是对隐含的指针this的参数重载。
const成员函数不能更新类的成员变量,也不能调用该类中没有用const修饰的成员函数,只能调用const成员函数。
非常量对象也可以调用const成员函数,但是如果有重载的非const成员函数则会调用非cosnt成员函数。
十七、algo.h
此头文件包含一系列算法。有些挺复杂的。
主要关注一下归并、快排、堆排等等。
17.1 random_shuffle
template<typename RandomIter>
void random_shuffle(RandomIter first, RandomIter last)
{
if(first == last)
return;
srand((unsigned)time(0));
for(auto i = first + 1; i != last; ++i)
mystl::iter_swap(i, first + (rand() % (i - first + 1)));
}
1、当n=1时,所以元素arr[0]在任何一个位置的概率为1/1,命题成立。
2、假设当n=k时,命题成立,即原数组中任何一个元素在任何一个位置的概率为1/k。
3、则当n=k+1时,当算法执行完k次时,前k个元素在前k个位置的概率均为1/k。当执行最后一步时,前k个元素中任何一个元素被替换到第k+1位置的概率为:(1-1/(k+1)) * 1/k = 1/(k+1); 在前面k个位置任何一个位置的概率为(1-1/(k+1)) * 1/k = 1/(k+1);故前k个元素在任意位置的的概率都为1/(k+1)所以,对于前k个元素,它们在k+1的位置上概率为1/(k+1)。对于第k+1个元素,其在原位置的概率为1/k+1,在前k个位置任何一个位置的概率为:(1-k/(k+1)) * (1/k)=1/(k+1),所以对于第k+1个元素,其在整个数组前k+1个位置上的概率也均为1/k+1。
综上所述,对于任意n,只要按照方案中的方法,即可满足每个元素在任何一个位置出现的概率均为1/n。
17.2 premutation
next_permutation:让字典序变大但又不能太大
bool next_permutation(Iter first, Iter last)
{
auto i = last;
if(first == last || first == --i)
return false;
for(;;)
{
auto ii = i;
if(*--i < *ii)//从i位置向前找到第一个比*i小的位置
{
auto j = last;
while(!(*i < *--j));//从尾向前找到大于*i的位置
swap(*i, *j);
reverse(ii, last);
return true;
}
if(i == first)
{
reverse(first, last);
return false;
}
}
}
17.3 sort
quick_sort: nlogn insert_sort: n^2
当logn < n 时 使用quick_sort,反之使用insert_sort
- 针对大数据量,使用快排,时间复杂度是
O(NlogN); - 若快排递归深度超过阈值
__depth_limit,改用堆排序,防止快排递归过深,同时保持时间复杂度仍是O(NlogN); - 当数据规模小于阈值
_S_threshold时,改用插入排序
template<typename RandomIter, typename Size>
void intro_sort(RandomIter first, RandomIter last, Size depth_limit)
{
while(static_cast<size_t>(last - first) > kSmallSectionSize)
{
if(depth_limit == 0)
{
/* 到达最大分割深度,改用heap_sort*/
leptstl::partial_sort(first, last, last);
return;
}
--depth_limit;
auto mid = leptstl::median(*first, *(first + (last - first) / 2),
*(last - 1));
auto cut = leptstl::unchecked_partition(first, last, mid);
leptstl::intro_sort(cut, last, depth_limit);
last = cut;
}
}
每次先进入右分支,在下个循环进入左分支
相比较常规快排实现,最直观的感受,就是减少一次函数调用的开销。此外,进入左分支后,可能就不满足last - first > kSmallSectionSize限制条件,那么当前循环就退出了,避免递归。
因此,当 intro_sort函数因不满足kSmallSectionSize阈值条件,逐层返回到sort函数中时,完整的[first, last)区间中会有许多元素个数小于kSmallSectionSize的无序区间,他们的有序性留给最后的插入排序final_insertion_sort函数来完成。
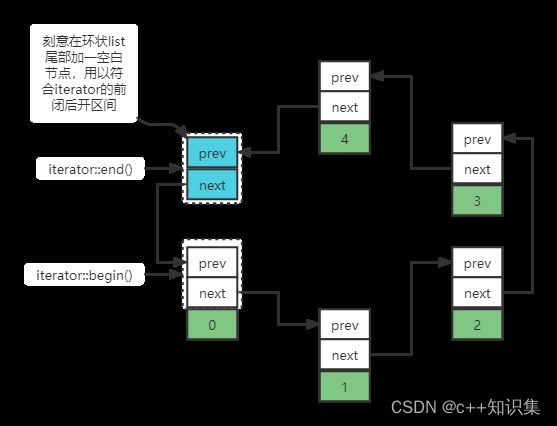
十八、list.h
typedef list_node_base<T>* base_ptr;
typedef list_node<T>* node_ptr;
struct list_node_base
{
base_ptr prev;/*前一节点*/
base_ptr next;/*后一节点*/
}
struct list_node : public list_node_base
{
T value;
}
class list
{ //成员变量,申请内存是以list_node来申请的
base_ptr node_;//指向dummy节点,连接头尾。因为,要统一迭代器前闭后开区间
size_type size_;//大小
//迭代器相关操作
begin();
end();
rbegin();
rend();
cbegin();
cend();
//容器相关操作
empty();
size();
max_size();
//访问元素相关操作
front();
back();
//调整容器相关操作
assign(size_type n, const value_type& value);
assign(Iter first, Iter last);
emplace_front(Args&& ...args);
emplace_back(Args&& ...args);
emplace(const_iterator pos, Args&& ...args);
insert(const_iterator pos, const value_type& value);
insert(const_iterator pos, value_type&& value);
insert(const_iterator pos, size_type n, const value_type& value);
insert(const_iterator pos, Iter first, Iter last);
push_front(const value_type& value);
push_front(value_type&& value);
push_back(const value_type& value);
push_back(value_type&& value);
pop_front();
pop_back();
erase(const_iterator pos);
erase(const_iterator first, const_iterator last);
resize(size_type new_size) { resize(new_size, value_type()); };
resize(size_type new_size, const value_type& value);
swap(list& rhs);
//list相关操作
splice(const_iterator pos, list& other);
splice(const_iterator pos, list& other, const_iterator it);
splice(const_iterator pos, list& other, const_iterator first, const_iterator last);
remove(const value_type& value);
remove_if(UnaryPred pred);
unique();
unique(BinaryPredicate pred);
merge(list& x);
merge(list& x, Compared comp);
sort();
sort(Compared comp);
reverse();
}
18.1 什么是lamba?
[ capture ] ( params ) opt -> ret { body; };
lambda 表达式还可以通过捕获列表捕获一定范围内的变量:
[] 不捕获任何变量。
[&] 捕获外部作用域中所有变量,并作为引用在函数体中使用(按引用捕获)。
[=] 捕获外部作用域中所有变量,并作为副本在函数体中使用(按值捕获)。
[=,&foo] 按值捕获外部作用域中所有变量,并按引用捕获 foo 变量。
[bar] 按值捕获 bar 变量,同时不捕获其他变量。
[this] 捕获当前类中的 this 指针,让 lambda 表达式拥有和当前类成员函数同样的访问权限。如果已经使用了 & 或者 =,就默认添加此选项。捕获 this 的目的是可以在 lamda 中使用当前类的成员函数和成员变量。
按值捕获得到的外部变量值是在 lambda 表达式定义时的值。此时所有外部变量均被复制了一份存储在 lambda 表达式变量中。此时虽然修改 lambda 表达式中的这些外部变量并不会真正影响到外部,我们却仍然无法修改它们。
如果希望 lambda 表达式在调用时能够即时访问外部变量,我们应当使用引用方式捕获。
那么如果希望去修改按值捕获的外部变量应当怎么办呢?这时,需要显式指明 lambda 表达式为 mutable:
int a = 0;
auto f1 = [=]{ return a++; }; // error,修改按值捕获的外部变量
auto f2 = [=]() mutable { return a++; }; // OK,mutable
需要注意的一点是,被 mutable 修饰的 lambda 表达式就算没有参数也要写明参数列表。
18.2 list.splice函数
list::splice实现list拼接的功能。将源list的内容部分或全部元素删除,并插入到目的list的position位置之后。
函数有以下三种声明:
一:void splice ( iterator position, list
二:void splice ( iterator position, list
三:void splice ( iterator position, list
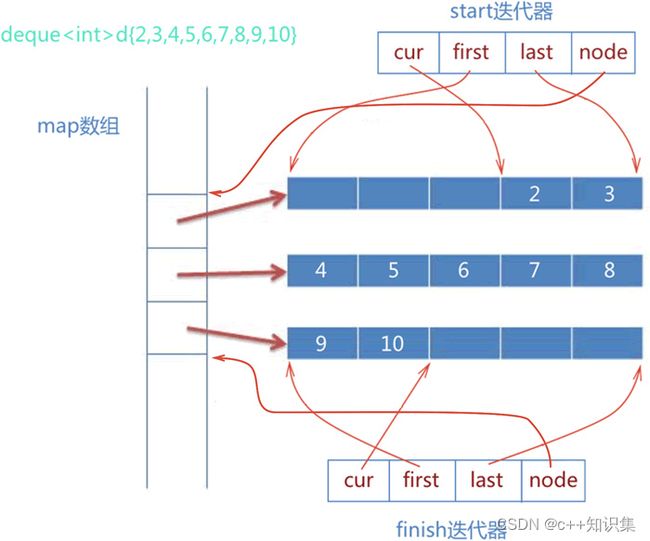
十九、deque.h
具体实现原理可以参考这篇文章:deque底层实现原理!
struct deque_iterator
{
/* 迭代器所含成员数据*/
value_pointer cur; /* 指向所在缓冲区的当前元素*/
value_pointer first; /* 指向所在缓冲区的头部*/
value_pointer last; /* 指向所在缓冲区的尾部*/
map_pointer node; /* 缓冲区在map上的节点位置*/
}
class deque
{
/* 用以下四个数据表现一个deque*/
iterator begin_; /* 指向第一个节点*/
iterator end_; /* 指向最后一个节点*/
map_pointer map_; /* 指向一块map, map中的每个元素都是指针,指向一个缓冲区*/
size_type map_size_; /* map内指针数目*/
//迭代器相关操作
begin();
end();
rbegin();
rend();
cbegin();
cend();
//容器相关操作
empty();
size();
max_size();
resize(size_type new_size) { resize(new_size, value_type()); }
resize(size_type new_size, const value_type& value);
//访问元素相关操作
operator[](size_type n);
at(size_type n);
front();
back();
//修改容器相关操作
assign(size_type n, const value_type& value);
assign(IIter first, IIter last);
assign(std::initializer_list<value_type> ilist);
emplace_front(Args&& ...args);
emplace_back(Args&& ...args);
emplace(iterator pos, Args&& ...args);
push_front(const value_type& value);
push_back(const value_type& value);
push_front(value_type&& value) { emplace_front(mystl::move(value)); }
push_back(value_type&& value) { emplace_back(mystl::move(value)); }
pop_front();
pop_back();
insert(iterator position, const value_type& value);
insert(iterator position, value_type&& value);
insert(iterator position, size_type n, const value_type& value);
insert(iterator position, IIter first, IIter last);
erase(iterator position);
erase(iterator first, iterator last);
clear();
swap(deque& rhs);
}
二十、basic_string.h
初始化大小默认32字节。
class basic_string
{
iterator buffer_; /* 储存字符串起始位置*/
size_type size_; /* 大小*/
size_type cap_; /* 容量*/
//迭代器相关操作
begin();
end();
rbegin();
rend();
cbegin();
cend();
//容量相关操作
empty();
size();
length();
capaciity();
max_size();
reserve();
shrink_to_fit();
//访问元素相关操作
operator[](size_type n);
at(size_type n);
front();
back();
data();
c_str();
//修改容器相关操作
push_back(value_type ch);
pop_back();
append(size_type count, value_type ch);
append(const basic_string& str);
append(const basic_string& str, size_type pos);
append(const basic_string& str, size_type pos, size_type count);
append(const_pointer s);
append(const_pointer s, size_type count);
append(Iter first, Iter last);
insert(const_iterator pos, value_type ch);
insert(const_iterator pos, size_type count, value_type ch);
insert(const_iterator pos, Iter first, Iter last);
erase(const_iterator pos);
erase(const_iterator first, const_iterator last);
resize(size_type count){ resize(count, value_type()); }
resize(size_type count, value_type ch);
clear();
//basic_string相关操作
compare(const basic_string& other) const;
compare(size_type pos1, size_type count1, const basic_string& other) const;
compare(size_type pos1, size_type count1, const basic_string& other,size_type pos2, size_type count2 = npos) const;
compare(const_pointer s) const;
compare(size_type pos1, size_type count1, const_pointer s) const;
compare(size_type pos1, size_type count1, const_pointer s, size_type count2) const;
substr(size_type index, size_type count = npos);
replace(size_type pos, size_type count, const basic_string& str);
replace(const_iterator first, const_iterator last, const basic_string& str);
replace(size_type pos, size_type count, const_pointer str);
replace(const_iterator first, const_iterator last, const_pointer str);
replace(size_type pos, size_type count, const_pointer str, size_type count2);
replace(const_iterator first, const_iterator last, const_pointer str, size_type count);
replace(size_type pos, size_type count, size_type count2, value_type ch);
replace(const_iterator first, const_iterator last, size_type count, value_type ch);
replace(size_type pos1, size_type count1, const basic_string& str,size_type pos2, size_type count2 = npos);
replace(const_iterator first, const_iterator last, Iter first2, Iter last2);
reverse();
swap(basic_string& rhs) noexcept;
...
}
20.1 POD类型
POD 是 Plain Old Data 的缩写,是 C++ 定义的一类数据结构概念,比如 int、float 等都是 POD 类型的。Plain 代表它是一个普通类型,Old 代表它是旧的,与几十年前的 C 语言兼容,那么就意味着可以使用 memcpy() 这种最原始的函数进行操作。两个系统进行交换数据,如果没有办法对数据进行语义检查和解释,那就只能以非常底层的数据形式进行交互,而拥有 POD 特征的类或者结构体通过二进制拷贝后依然能保持数据结构不变。也就是说,能用 C 的 memcpy() 等函数进行操作的类、结构体就是 POD 类型的数据。
20.2 friend function
类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。尽管友元函数的原型有在类的定义中出现过,但是友元函数并不是成员函数。
友元可以是一个函数,该函数被称为友元函数;友元也可以是一个类,该类被称为友元类,在这种情况下,整个类及其所有成员都是友元。
如果要声明函数为一个类的友元,需要在类定义中该函数原型前使用关键字 friend
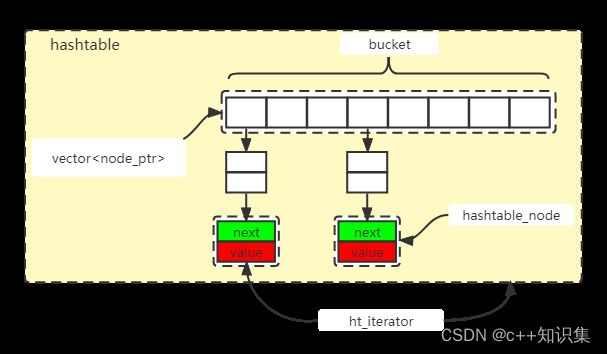
二十一、hashtable.h
哈希的查找就是下面两个步骤:
<1>使用哈希函数将被查找的键转化为数组的索引。在理想的状态下,不同的键会被转化成不同的索引值。但是那是理想状态,我们实践当中是不可能一直是理想状态的。当不同的键生成了相同的索引的时候,也就是我们所说的冲突,我们这个时候就要处理冲突。
<2> 处理冲突的方法很多,拉链法和线性探索法。
此头文件使用开链法解决冲突。
struct hashtable_node
{
hashtable_node* next; /* 指向下一个节点*/
T value; /* 储存实际值*/
}
struct ht_iterator_base
{
node_ptr node; //当前所指节点 node_ptr == hashtable_node*
contain_ptr ht;//保持与容器的连接 contain_ptr == hashtable*
}
class hashtable
{
/* 用以下六个参数来表现 hashtable*/
bucket_type buckets_; /*桶数组,使用vector*/
size_type bucket_size_; /*桶数量*/
size_type size_; /*元素数量*/
float mlf_; /*最大桶装载比例*/
hasher hash_; /*哈希仿函数*/
key_equal equal_; /*键值相等的比较仿函数*/
};
bucket使用质数减少冲突:101开始,乘以1.5后的最接近>=的质数。项目中的好像算错了。101*1.5=151.5,下一个最接近的质数为157。
二十二、unordered_set.h
class unordered_set
{
hashtable ht_;
//迭代器相关操作
begin();
end();
rbegin();
rend();
cbegin();
cend();
//容量相关操作
empty();
size();
max_size();
emplace(Arg&& ...args);
insert(const value_type& value);
insert(value_type&& value);
insert(const_iterator hint, const value_type& value);
insert(const_iterator hint, value_type&& value);
insert(InputIterator first, InputIterator last);
erase(iterator it);
erase(iterator first, iterator last);
erase(const key_type& key);
clear();
swap(unordered_set& other);
//查找相关操作
count(const key_type& key);
find(const key_type& key);
equal_range(const key_type& key);
//bucket interface
begin(size_type n);/*选择bucket上的index为n的位置*/
bucket_count();/* 返回bucket的容量*/
max_bucket_count();/*返回bucket能达到的最大容量*/
bucket_size(size_type n);/*返回bucket[n]的node数*/
bucket(const key_type& key);/*返回key对应的bucket位置*/
};
就是对hashtable的接口调用。