【深度学习--RNN 循环神经网络--附LSTM情感文本分类】
deep learning 系列 --RNN 循环神经网络
什么是序列模型
包括了RNN LSTM GRU等网络模型,主要用途是自然语言处理、语音识别等方面,比如生成乐曲,音频转换为文字,文本情感分类,机器翻译等等
标准模型的缺陷
以往的标准模型比如CNN,每次的输入不影响下次的输出,也就是说每次输入的图片都是独立的,没有任何关联,但是很多情况下,我们建立的模型与前项甚至后项的输入是相关的。举个例子,我们要从这两句话中识别出人名:
President Teddy was …
Teddy bear was…
这其中都有一个关键且同样的词Teddy,但是这个Teddy可以是个人名,也可以是泰迪,究竟是哪个呢?通常的识别方法是:
1.从之前学习过的人名识别
我们之前的位置可能提取过Teddy是人名, 但CNN网络,并不能共享从不同位置提取到到的特征,因此不可行
2.从本次输入的上下文出发
比如这里下文有 bear,President,但是CNN也不具备这种序列特性,因此也不可行
另外,CNN的网络对于输入的模型的数据长度都是固定的,但是不同的句子长度并不一致,当然我们可以padding,但是不那么好。
因此才有了循环神经网络架构,它可以克服以上的这些问题
循环神经网络
架构
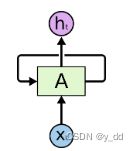
图示是循环神经网络架构, 是有循环的,这个图形是最长用于展示的,但实际并不好理解,这个环实际上是多次的输入和输出,下面这种展开的方式更容易理解
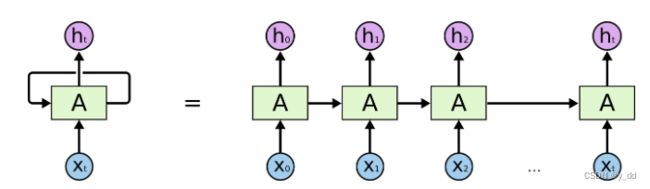
RNN的结构就包括三类输入的权重参数
1.激活值的参数,水平方向的值,每个时间步的激活参数是相同的
2.输入到隐藏层的参数,也就是x到A方向,这个也是每个时间步相同
3.用来预测输出的参数,A到h的方向
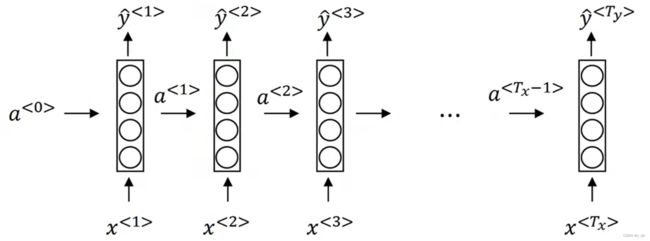
其中y的输出可以用如下表示:
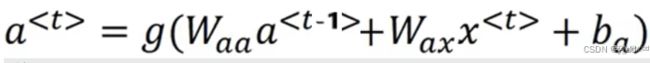
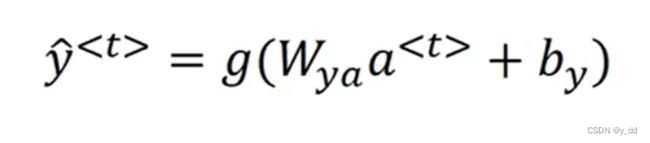
预测值y
BPTT 反向传播
实际上在工具中,反向传播都是自动进行的,原理跟普通的反向传播一致
输入序列后,假设预测的值是0.9,但实际是1,产生损失,这个损失可以用交叉熵损失函数来估量
RNN中的反向传播时将之前所有的箭头都反过来,计算出合适的变量,通过导数相关的计算,利用梯度下降算法更新参数,也就是图示:
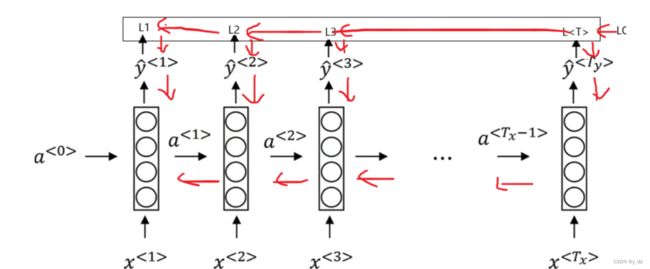
这个传播过程中最重要的就是水平方向时间步的反向,因此又叫做穿越时间的反向传播Back Propagate Through time
不同类型的循环神经网络
-
多对多
比如机器翻译,输入是多个,输出也是多个,且并不对等,此时经常使用的是encode-decoder,encoder编码器获取输入,并输出,而decoder则使用encode编码的输出,执行decoder,这样输入x和输出y的长度就可以不相同了
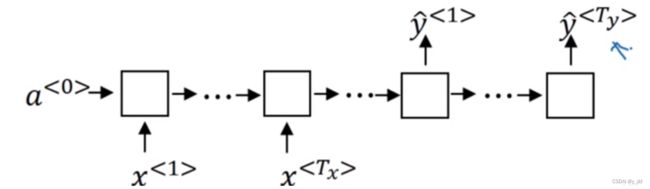
当然输入和输出对等的情况也很多
比如在句子中寻找人名,预测输出y就可以是每个x的对应的每个位置输出y(0表示非人名,1表示是人名) -
多对一
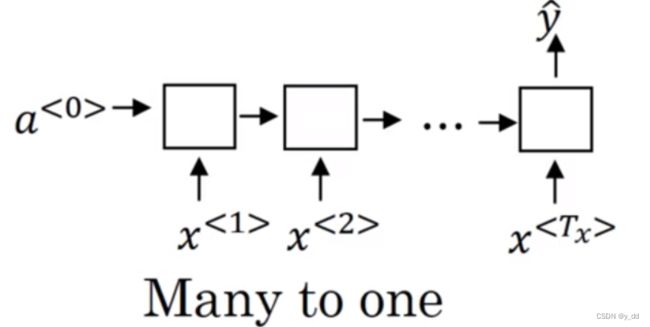
比如进行文本的情感分类,这样输入就有可能是一段文本,而输出我们只需要最后一层最后一个时间步的输出即可,一个0和1就足以标识这段文本是positive还是negative -
一对多
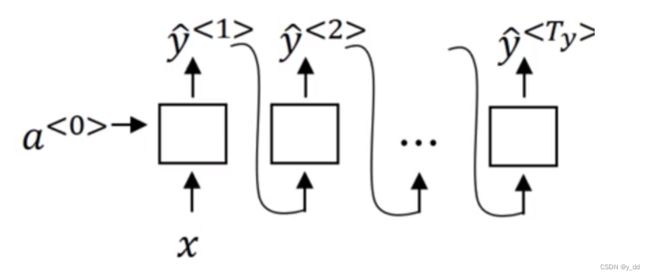
比如生成类的,输入一个音符或者不输入,就可以产生多个输出
RNN的缺陷 梯度消失和梯度爆炸
-
现象:
实际上深度比较大的网络都可能梯度消失或者爆炸,这种现象在在RNN中更加明显
当我们输入的序列为1000的时候,拿最简单的模型举例 y = wx 经过1000次的传播,y1000 的变化

w仅仅变化一点,经过1000次的传播,变化非常的大 -
原因:
发生这样的根本原因是RNN中每一次的输出都将被前面的数据彻底的清洗,而经过长时间的传输,很前面步的影响都后面的影响已经很微弱了,损失的反向调整同样也是,经过长距离的调整,差错已经很难反馈很多个时间步之后了
-
解决办法:
梯度爆炸:进行梯度裁剪即可,比如我们发现输出有很多超大的值的时候,进行裁剪
梯度消失:它很难察觉,也在标准的RNN结构中,可以用GRU或者LSTM解决,而解决梯度消失的实质是通过保留一些前期输入的记忆
LSTM
标准的RNN结构是这样的:
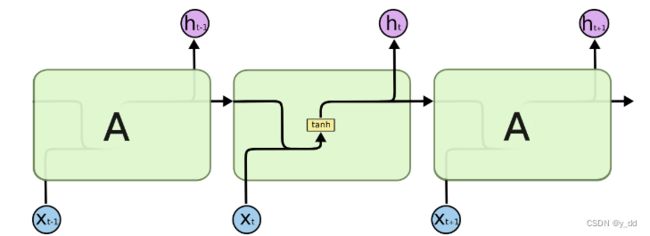
而标准的LSTM加入了四个门控单元
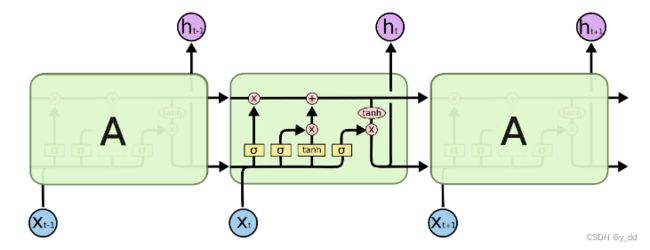
这四个门单元分别是:
it, ft,gt, ot 分别是输入门、遗忘门、cell(记忆)门,以及输出门
他们控制 是否输入,对输入的遗忘和记忆,也控制是否输出,从而控制重要信息的传递,不重要信息遗忘
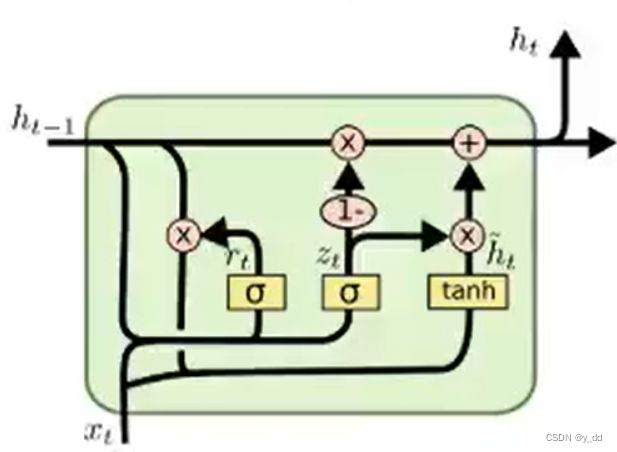
GRU
它比LSTM诞生更晚,是LSTM的变形版本,由于门单元更少,计算简单些,因此训练时间更短一些。
LSTM实例
本实例以IMDB数据集为例,代码篇幅过长,本文仅列示其中LSTM使用相关的重点,后续会有专门的博客详细解析代码。
- 预处理数据
读取IMDB数据集
def read_imdb(datafolder ='train', dataroot=imdb_zip_path):
data=[]
for label in ['pos', 'neg']:
filepath = os.path.join(imdb_zip_path, datafolder, label)
for file in tqdm(os.listdir(filepath)):
with open(os.path.join(filepath,file), 'rb') as f:
content = f.read().decode('utf-8').replace('\n', ' ').lower()
data.append([content, 1 if label == 'pos' else 0])
random.shuffle(data)
return data
IMDB中的数据分词
def get_tokenized(data):
def tokenizer(text):
filters = ['!', '"', '#', '$', '%', '&', '\(', '\)', '\*', '\+', ',', '-', '\.', '/', ':', ';', '<', '=', '>',
'\?', '@', '\[', '\\', '\]', '^', '_', '`', '\{', '\|', '\}', '~', '\t', '\n', '\x97', '\x96', '”', '“', ]
text = re.sub("<.*?>", " ", text, flags=re.S)
text = re.sub("|".join(filters), " ", text, flags=re.S)
return [i.strip().lower() for i in text.split()]
return [tokenizer(context) for context, _ in data]
创建分词后的词典
def get_vocab(data):
counter = collections.Counter(_flatten(data))
return vocab.vocab(counter)
封装dataloader
class ImdbLoader(object):
def __init__(self, set_name='train', batch_size='64'):
super(ImdbLoader, self).__init__()
self.data_set = set_name
self.batch_size = batch_size
def get_data_loader(self):
# train_data = [['"dick tracy" is one of our"', 1],
# ['arguably this is a the )', 1],
# ["i don't just to warn anyone ", 0]]
train_data = read_imdb(self.data_set)
data = preprocess(train_data)
#print(data)
data_set = Data.TensorDataset(*data)
data_loader = Data.DataLoader(data_set, self.batch_size, shuffle=True)
return data_loader
- 创建模型
此处创建了一个模型,包括双向的LSTM层和一个全连接层
class BiRNN(nn.Module):
def __init__(self, vocabulary, embed_len, hidden_len, num_layer):
super(BiRNN, self).__init__()
self.embedding = nn.Embedding(len(vocabulary), embed_len)
self.encoder = nn.LSTM(input_size=embed_len,
hidden_size=hidden_len,
num_layers=num_layer,
bidirectional=True,
dropout = 0.3)
# 本次使用起始和最终时间步的隐藏状态座位全连接层的输入
self.decoder = nn.Linear(2*2*hidden_len, 2)
def forward(self, inputs):
#print('rnn model py: input_shape: ', inputs.shape)
embeddings = self.embedding(inputs)
glove_vab = getGlove()
net.embedding.weight.data.copy_(load_pretrained_embedding(vo.get_itos(), glove_vab))
net.embedding.weight.requires_grad = False
#print('after embed input shape:', embeddings.shape)
embeddings = embeddings.permute(1, 0, 2)
output_sequence, _ = self.encoder(embeddings)
concat_out = torch.cat((output_sequence[0], output_sequence[-1]), -1)
outputs = self.decoder(concat_out)
return outputs
3.模型训练
def train(epoch, imdb_model, lr, train_batch_size):
imdb_model_device = imdb_model.to(device)
# 过滤掉不需要计算梯度的embedding的参数
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, imdb_model_device.parameters()), lr=lr)
loader = ImdbLoader('train', train_batch_size)
data_loader = loader.get_data_loader()
for i in range(epoch):
for idx, (inputs, target) in enumerate(data_loader):
target = target.to(device)
inputs = inputs.to(device)
#print('train.py input shape:', inputs.shape)
optimizer.zero_grad()
output = imdb_model(inputs)
#print('ouput.shape', output.shape)
criterion = nn.CrossEntropyLoss()
loss = criterion(output, target)
loss.backward()
optimizer.step()
if idx % 10 == 0:
predict = torch.max(output, dim=-1, keepdim=False)[-1]
acc = predict.eq(target.data).cpu().numpy().mean() * 100
print('train Epoch:{} processed:[{} / {} ({:.0f}%) Loss: {:.6f}, ACC: {:.6f}]'.format(
i,
idx * len(inputs),
len(data_loader.dataset),
100. * idx / len(data_loader),
loss.item(),
acc))
torch.save(imdb_model.state_dict(), '../../resources/model_save/imdb_net.pkl')
torch.save(optimizer.state_dict(), '../../resources/model_save/imdb_optimizer.pkl')
4.模型评估
def test(imdb_model, test_batch_size):
imdb_model.eval()
imdb_model = imdb_model.to(device)
loader = ImdbLoader('test', test_batch_size)
data_loader = loader.get_data_loader()
with torch.no_grad():
for idx, (inputs, target) in enumerate(data_loader):
target = target.to(device)
inputs = inputs.to(device)
#print(inputs)
output = imdb_model(inputs)
criterion = nn.CrossEntropyLoss()
loss = criterion(output, target)
predict = torch.max(output, dim=-1, keepdim=False)[-1]
correct = predict.eq(target.data).sum()
acc = 100. * predict.eq(target.data).cpu().numpy().mean()
print('idx: {} loss : {}, accurate: {}/{} {:.2f}'.format(idx, loss, correct, target.size(0), acc))
最终效果,当我们执行4个epoch后,准确率基本稳定在80%以上
train Epoch:3 processed:[23680 / 25000 (95%) Loss: 0.325240, ACC: 84.375000]
train Epoch:3 processed:[24320 / 25000 (97%) Loss: 0.449456, ACC: 75.000000]
train Epoch:3 processed:[15600 / 25000 (100%) Loss: 0.438567, ACC: 80.000000]
train Epoch:4 processed:[0 / 25000 (0%) Loss: 0.353131, ACC: 85.937500]
train Epoch:4 processed:[640 / 25000 (3%) Loss: 0.345814, ACC: 89.062500]
train Epoch:4 processed:[1280 / 25000 (5%) Loss: 0.195520, ACC: 93.750000]
train Epoch:4 processed:[1920 / 25000 (8%) Loss: 0.269773, ACC: 87.500000]
train Epoch:4 processed:[2560 / 25000 (10%) Loss: 0.287010, ACC: 85.937500]
train Epoch:4 processed:[3200 / 25000 (13%) Loss: 0.291449, ACC: 90.625000]
参考
colah https://colah.github.io/posts/2015-08-Understanding-LSTMs/
吴恩达 deep learning
https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html#torch.nn.LSTM