【Apollo自动驾驶-从理论到代码】cyber/scheduler模块
/* 作者水平有限,欢迎批评指正,内容持续完善中!!*/
Apollo Cyber Scheduler
- Scheduler介绍
- Cyber/Scheduler目录主要文件
- 类图
- 代码详解
-
- 1.调度器的实例化起点scheduler_factory.cc
- 2.1SchedulerClassic调度器在scheduler_classic.cc中实例化
- 2.2SchedulerClassic中的ClassicContext作用
- 3.SchedulerClassic和SchedulerChoreography的共同执行器Processor
- 4.总结性全局调用逻辑
Scheduler介绍
Scheduler是Apollo自动驾驶平台的调度核心,是协程的调度载体。
Cyber/Scheduler目录主要文件
| 文件名 | 描述 | 作用 |
|---|---|---|
| scheduler.cc | 调度器基类 | 提供整个调度器的基类 |
| scheduler_factory.cc | 调度器工厂类 | 用于实例化调度器 |
| process.cc | 执行器类 | 用于构造执行器,是协程的执行载体,和线程1:1对应 |
| policy/scheduler_classic.cc | 经典策略调度类 | 经典的调度策略,在使用者无法深入了解系统流程情况下 |
| policy/scheduler_choreographr.cc | 编排策略调度类 | 可以按照使用者的策略,定制调度策略 |
| – | – | – |
类图

代码详解
/* 写在前面,由于Apollo采用C++开发,为了避免阅读困难,笔者将会对其中部分C++语法进行相应的注释,方便新手,或者其他语言开发者的学习。如有错误,欢迎指正! */
Apollo中的调度器为单例。在scheduler_factory工厂中,按照配置文件使能对应的调度器策略。调用点在Component组件构造过程中, auto sched = scheduler::Instance(); 下面从Instance()函数开始,逐步展开shceduler模块的内部结构。先用图的方式展现流程。

1.调度器的实例化起点scheduler_factory.cc
// cyber/scheduler/scheduler_factory.cc
namespace apollo {
namespace cyber {
namespace scheduler {
using apollo::cyber::common::GetAbsolutePath;
using apollo::cyber::common::GetProtoFromFile;
using apollo::cyber::common::GlobalData;
using apollo::cyber::common::PathExists;
using apollo::cyber::common::WorkRoot;
namespace {
std::atomic<Scheduler*> instance = {nullptr}; // 用于多线程环境,避免竞争。
std::mutex mutex;
} // namespace
Scheduler* Instance() {
// 多线程编程下,内存一致性编程技巧。
Scheduler* obj = instance.load(std::memory_order_acquire);
if (obj == nullptr) {
std::lock_guard<std::mutex> lock(mutex);
obj = instance.load(std::memory_order_relaxed);
if (obj == nullptr) {
std::string policy("classic"); // 默认策略为classic
std::string conf("conf/"); // 策略配置文件目录
conf.append(GlobalData::Instance()->ProcessGroup()).append(".conf");
auto cfg_file = GetAbsolutePath(WorkRoot(), conf);
apollo::cyber::proto::CyberConfig cfg;
// 判断策略文件路径,并加载策略
if (PathExists(cfg_file) && GetProtoFromFile(cfg_file, &cfg)) {
policy = cfg.scheduler_conf().policy();
} else {
AWARN << "No sched conf found, use default conf.";
}
// 根据策略policy,实例化调度器,如果policy无法使用默认classic调度器
if (!policy.compare("classic")) {
obj = new SchedulerClassic();
} else if (!policy.compare("choreography")) {
obj = new SchedulerChoreography();
} else {
AWARN << "Invalid scheduler policy: " << policy;
obj = new SchedulerClassic();
}
instance.store(obj, std::memory_order_release);
}
}
return obj;
}
// 资源释放
void CleanUp() {
Scheduler* obj = instance.load(std::memory_order_acquire);
if (obj != nullptr) {
obj->Shutdown();
}
}
} // namespace scheduler
} // namespace cyber
} // namespace apollo
总结:上述代码为工厂方法,会根据配置文件产生对应的调度器。只会执行一次,从代码角度分析,会在第一个Component组件构造的过程中执行。后面会详细介绍Component组件的代码执行流程。
下面将会介绍两个调度器的实例化过程。
2.1SchedulerClassic调度器在scheduler_classic.cc中实例化
namespace apollo {
namespace cyber {
namespace scheduler {
// 使用的外部类
using apollo::cyber::base::ReadLockGuard;
using apollo::cyber::base::WriteLockGuard;
using apollo::cyber::common::GetAbsolutePath;
using apollo::cyber::common::GetProtoFromFile;
using apollo::cyber::common::GlobalData;
using apollo::cyber::common::PathExists;
using apollo::cyber::common::WorkRoot;
using apollo::cyber::croutine::RoutineState;
// SchedulerClassic构造函数
SchedulerClassic::SchedulerClassic() {
std::string conf("conf/");
conf.append(GlobalData::Instance()->ProcessGroup()).append(".conf");
auto cfg_file = GetAbsolutePath(WorkRoot(), conf);
// 加载配置文件,CyberConfig 为Cyber的配置文件,里面包含四种配置文件,分别为
//1.scheduler_conf,调度配置文件。
//2.transport_conf
//3.run_mode_conf
//4.perf_conf
//上述配置的原型定义在/cyber/proto/目录中
apollo::cyber::proto::CyberConfig cfg;
if (PathExists(cfg_file) && GetProtoFromFile(cfg_file, &cfg)) {
// inner_thr_confs_的定义为std::unordered_map inner_thr_confs_;
// 背景知识,什么是内部线程?主要是支持框架运行的线程,和自动驾驶组件执行无关。
// 目前Apollo中主要有async_log 、io_poller 、shm 、timer 、shm_disp几个内部线程。
for (auto& thr : cfg.scheduler_conf().threads()) {
inner_thr_confs_[thr.name()] = thr;
}
// process_level_cpuset: "0-7,16-23" # all threads in the process are on the cpuset
// process_level_cpuset为字符串类型,描述了线程可以运行的CPU编号。
if (cfg.scheduler_conf().has_process_level_cpuset()) {
process_level_cpuset_ = cfg.scheduler_conf().process_level_cpuset();
//绑定CPU
ProcessLevelResourceControl();
}
// 获取Classic配置文件
classic_conf_ = cfg.scheduler_conf().classic_conf();
//遍历所有的组
for (auto& group : classic_conf_.groups()) {
auto& group_name = group.name();
// 遍历组中的所有task
for (auto task : group.tasks()) {
task.set_group_name(group_name);
// std::unordered_map cr_confs_;存放task信息
cr_confs_[task.name()] = task;
}
}
} else {
// if do not set default_proc_num in scheduler conf
// give a default value
// 如果没有配置文件,使用默认配置
uint32_t proc_num = 2;
auto& global_conf = GlobalData::Instance()->Config();
if (global_conf.has_scheduler_conf() &&
global_conf.scheduler_conf().has_default_proc_num()) {
proc_num = global_conf.scheduler_conf().default_proc_num();
}
task_pool_size_ = proc_num;
// 设置默认组名
auto sched_group = classic_conf_.add_groups();
sched_group->set_name(DEFAULT_GROUP_NAME);
sched_group->set_processor_num(proc_num);
}
// 创建执行器,此为线程运行的载体
CreateProcessor();
}
void SchedulerClassic::CreateProcessor() {
// 此处根据构造函数解析初始化的配置文件,创建执行器
for (auto& group : classic_conf_.groups()) {
auto& group_name = group.name();
auto proc_num = group.processor_num();
if (task_pool_size_ == 0) {
task_pool_size_ = proc_num;
}
auto& affinity = group.affinity();
auto& processor_policy = group.processor_policy();
auto processor_prio = group.processor_prio();
std::vector<int> cpuset;
ParseCpuset(group.cpuset(), &cpuset);
// 对于每个组中的每个proc创建执行器。
for (uint32_t i = 0; i < proc_num; i++) {
// 创建执行器的上下文,并放入全局的pctxs_队列中。后面将进一步介绍该队列的作用。
auto ctx = std::make_shared<ClassicContext>(group_name);
pctxs_.emplace_back(ctx);
// 创建执行器,并将上面创建的上下文与之关联。并放入全局的processors_队列中。
auto proc = std::make_shared<Processor>();
proc->BindContext(ctx);
SetSchedAffinity(proc->Thread(), cpuset, affinity, i);
SetSchedPolicy(proc->Thread(), processor_policy, processor_prio,
proc->Tid());
processors_.emplace_back(proc);
}
}
}
// 分发协程到对应的执行器上。
bool SchedulerClassic::DispatchTask(const std::shared_ptr<CRoutine>& cr) {
// we use multi-key mutex to prevent race condition
// when del && add cr with same crid
MutexWrapper* wrapper = nullptr;
if (!id_map_mutex_.Get(cr->id(), &wrapper)) {
{
std::lock_guard<std::mutex> wl_lg(cr_wl_mtx_);
if (!id_map_mutex_.Get(cr->id(), &wrapper)) {
wrapper = new MutexWrapper();
id_map_mutex_.Set(cr->id(), wrapper);
}
}
}
std::lock_guard<std::mutex> lg(wrapper->Mutex());
{
WriteLockGuard<AtomicRWLock> lk(id_cr_lock_);
if (id_cr_.find(cr->id()) != id_cr_.end()) {
return false;
}
id_cr_[cr->id()] = cr;
}
// 在cr_confs配置文件中查找是否存在当前协程的配置信息,如果存在使用该配置为协程配置关键参数,否使用默认值
if (cr_confs_.find(cr->name()) != cr_confs_.end()) {
ClassicTask task = cr_confs_[cr->name()];
cr->set_priority(task.prio());
cr->set_group_name(task.group_name());
} else {
// croutine that not exist in conf
cr->set_group_name(classic_conf_.groups(0).name());
}
// 矫正协程的调度优先级,如果超过最大值,使用最大值。
if (cr->priority() >= MAX_PRIO) {
AWARN << cr->name() << " prio is greater than MAX_PRIO[ << " << MAX_PRIO
<< "].";
cr->set_priority(MAX_PRIO - 1);
}
// Enqueue task.
{
// 将协程添加到对应group_name的对应priority的优先级队列中。
WriteLockGuard<AtomicRWLock> lk(
ClassicContext::rq_locks_[cr->group_name()].at(cr->priority()));
ClassicContext::cr_group_[cr->group_name()]
.at(cr->priority())
.emplace_back(cr);
}
ClassicContext::Notify(cr->group_name());
return true;
}
bool SchedulerClassic::NotifyProcessor(uint64_t crid) {
if (cyber_unlikely(stop_)) {
return true;
}
{
ReadLockGuard<AtomicRWLock> lk(id_cr_lock_);
if (id_cr_.find(crid) != id_cr_.end()) {
auto cr = id_cr_[crid];
if (cr->state() == RoutineState::DATA_WAIT ||
cr->state() == RoutineState::IO_WAIT) {
cr->SetUpdateFlag();
}
ClassicContext::Notify(cr->group_name());
return true;
}
}
return false;
}
bool SchedulerClassic::RemoveTask(const std::string& name) {
if (cyber_unlikely(stop_)) {
return true;
}
auto crid = GlobalData::GenerateHashId(name);
return RemoveCRoutine(crid);
}
bool SchedulerClassic::RemoveCRoutine(uint64_t crid) {
// we use multi-key mutex to prevent race condition
// when del && add cr with same crid
MutexWrapper* wrapper = nullptr;
if (!id_map_mutex_.Get(crid, &wrapper)) {
{
std::lock_guard<std::mutex> wl_lg(cr_wl_mtx_);
if (!id_map_mutex_.Get(crid, &wrapper)) {
wrapper = new MutexWrapper();
id_map_mutex_.Set(crid, wrapper);
}
}
}
std::lock_guard<std::mutex> lg(wrapper->Mutex());
std::shared_ptr<CRoutine> cr = nullptr;
{
WriteLockGuard<AtomicRWLock> lk(id_cr_lock_);
if (id_cr_.find(crid) != id_cr_.end()) {
cr = id_cr_[crid];
id_cr_[crid]->Stop();
id_cr_.erase(crid);
} else {
return false;
}
}
return ClassicContext::RemoveCRoutine(cr);
}
} // namespace scheduler
} // namespace cyber
} // namespace apollo
上面介绍完了SchedulerClassic的执行流程。其中用到了几个类,分别为Process、 ClassicContext。下面将介绍这些类的作用。
2.2SchedulerClassic中的ClassicContext作用
在SchedulerClassic中将ClassicContext和Processor进行了绑定。那么ClassicContext的作用是什么?代码流程又是什么呢?下面将会进行介绍。
class ClassicContext : public ProcessorContext {}

通过上面类的继承关系可知,ClassicContext是执行器的执行上下文。这里的构造函数主要完成当前组的执行上下文的初始化,最终的代码调用执行实在执行器中执行。
namespace apollo {
namespace cyber {
namespace scheduler {
using apollo::cyber::base::AtomicRWLock;
using apollo::cyber::base::ReadLockGuard;
using apollo::cyber::base::WriteLockGuard;
using apollo::cyber::croutine::CRoutine;
using apollo::cyber::croutine::RoutineState;
alignas(CACHELINE_SIZE) GRP_WQ_MUTEX ClassicContext::mtx_wq_;
alignas(CACHELINE_SIZE) GRP_WQ_CV ClassicContext::cv_wq_;
alignas(CACHELINE_SIZE) RQ_LOCK_GROUP ClassicContext::rq_locks_;
alignas(CACHELINE_SIZE) CR_GROUP ClassicContext::cr_group_;
alignas(CACHELINE_SIZE) NOTIFY_GRP ClassicContext::notify_grp_;
ClassicContext::ClassicContext() { InitGroup(DEFAULT_GROUP_NAME); }
ClassicContext::ClassicContext(const std::string& group_name) {
InitGroup(group_name);
}
void ClassicContext::InitGroup(const std::string& group_name) {
// 多优先级队列 MULTI_PRIO_QUEUE *multi_pri_rq_ = nullptr;
multi_pri_rq_ = &cr_group_[group_name];
// 队列锁
lq_ = &rq_locks_[group_name];
// 互斥锁
mtx_wrapper_ = &mtx_wq_[group_name];
// 条件变量
cw_ = &cv_wq_[group_name];
// 组通知队列
notify_grp_[group_name] = 0;
current_grp = group_name;
}
std::shared_ptr<CRoutine> ClassicContext::NextRoutine() {
if (cyber_unlikely(stop_.load())) {
return nullptr;
}
// 在当前组的优先级队列中,找到优先级最高的协程任务返回。
// 注意:i为高,为高优先级。
for (int i = MAX_PRIO - 1; i >= 0; --i) {
ReadLockGuard<AtomicRWLock> lk(lq_->at(i));
for (auto& cr : multi_pri_rq_->at(i)) {
//如果请求失败,继续执行
if (!cr->Acquire()) {
continue;
}
// 只返回就绪协程,特别关注!!!
if (cr->UpdateState() == RoutineState::READY) {
return cr;
}
// 释放未就绪协程
cr->Release();
}
}
return nullptr;
}
void ClassicContext::Wait() {
std::unique_lock<std::mutex> lk(mtx_wrapper_->Mutex());
cw_->Cv().wait_for(lk, std::chrono::milliseconds(1000),
[&]() { return notify_grp_[current_grp] > 0; });
if (notify_grp_[current_grp] > 0) {
notify_grp_[current_grp]--;
}
}
void ClassicContext::Shutdown() {
stop_.store(true);
mtx_wrapper_->Mutex().lock();
notify_grp_[current_grp] = std::numeric_limits<unsigned char>::max();
mtx_wrapper_->Mutex().unlock();
cw_->Cv().notify_all();
}
void ClassicContext::Notify(const std::string& group_name) {
(&mtx_wq_[group_name])->Mutex().lock();
notify_grp_[group_name]++;
(&mtx_wq_[group_name])->Mutex().unlock();
cv_wq_[group_name].Cv().notify_one();
}
bool ClassicContext::RemoveCRoutine(const std::shared_ptr<CRoutine>& cr) {
auto grp = cr->group_name();
auto prio = cr->priority();
auto crid = cr->id();
WriteLockGuard<AtomicRWLock> lk(ClassicContext::rq_locks_[grp].at(prio));
auto& croutines = ClassicContext::cr_group_[grp].at(prio);
for (auto it = croutines.begin(); it != croutines.end(); ++it) {
if ((*it)->id() == crid) {
auto cr = *it;
cr->Stop();
while (!cr->Acquire()) {
std::this_thread::sleep_for(std::chrono::microseconds(1));
AINFO_EVERY(1000) << "waiting for task " << cr->name() << " completion";
}
croutines.erase(it);
cr->Release();
return true;
}
}
return false;
}
} // namespace scheduler
} // namespace cyber
} // namespace apollo
3.SchedulerClassic和SchedulerChoreography的共同执行器Processor
上面介绍了那么多内容,又是类、上下文、执行器。一个根本问题就是,谁去执行上面的代码,换句话说,上面的代码由谁执行(废话)。
下面就来介绍所谓的执行器的概念,还记得前面绑定执行上下文的过程吗?将一个Context与一个Processor进行绑定。
下面的是Processor.cc的源码:
// cyber/scheduler/Processor.cc
namespace apollo {
namespace cyber {
namespace scheduler {
using apollo::cyber::common::GlobalData;
Processor::Processor() { running_.store(true); }
Processor::~Processor() { Stop(); }
// 执行器的运行入口(线程的循环入口)
void Processor::Run() {
tid_.store(static_cast<int>(syscall(SYS_gettid)));
AINFO << "processor_tid: " << tid_;
snap_shot_->processor_id.store(tid_);
while (cyber_likely(running_.load())) {
if (cyber_likely(context_ != nullptr)) {
// 遍历当前组的执行上下文的优先级队列中是否存在就绪协程
auto croutine = context_->NextRoutine();
if (croutine) {
snap_shot_->execute_start_time.store(cyber::Time::Now().ToNanosecond());
snap_shot_->routine_name = croutine->name();
// 协程恢复执行
croutine->Resume();
// 协程释放执行
croutine->Release();
} else {
snap_shot_->execute_start_time.store(0);
context_->Wait();
}
} else {
std::unique_lock<std::mutex> lk(mtx_ctx_);
cv_ctx_.wait_for(lk, std::chrono::milliseconds(10));
}
}
}
void Processor::Stop() {
if (!running_.exchange(false)) {
return;
}
if (context_) {
context_->Shutdown();
}
cv_ctx_.notify_one();
if (thread_.joinable()) {
thread_.join();
}
}
// 绑定过程,核心思想就是将Context与thread进行绑定。
void Processor::BindContext(const std::shared_ptr<ProcessorContext>& context) {
context_ = context;
std::call_once(thread_flag_,
[this]() { thread_ = std::thread(&Processor::Run, this); });
}
std::atomic<pid_t>& Processor::Tid() {
while (tid_.load() == -1) {
cpu_relax();
}
return tid_;
}
} // namespace scheduler
} // namespace cyber
} // namespace apollo
4.总结性全局调用逻辑
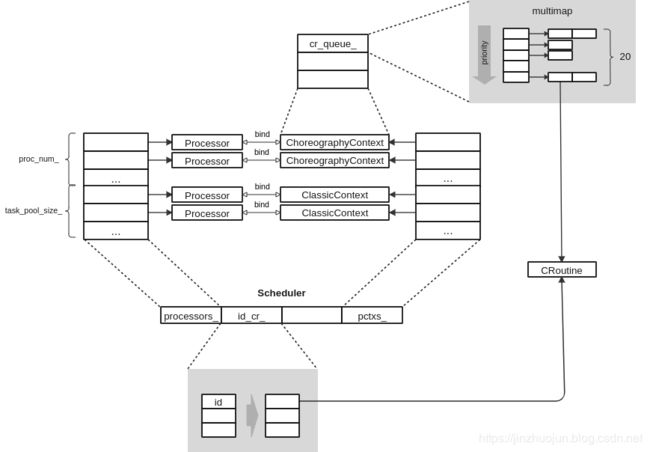
盗个图链接: 自动驾驶平台Apollo 5.5阅读手记:Cyber RT中的任务调度
该博主充分生动的展示了Processor、Context、Scheduler等元素之间的关系。介绍完了代码流程后,我们回来看看配置文件的具体内容。
图片:
图片: 
【未完。。。】