数据分析 | 调用Optuna库实现基于TPE的贝叶斯优化 | 以随机森林回归为例
1. Optuna库的优势
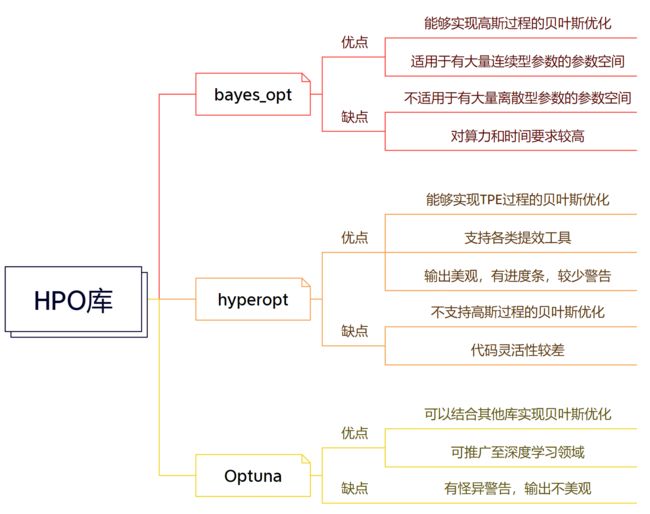
对比bayes_opt和hyperoptOptuna不仅可以衔接到PyTorch等深度学习框架上,还可以与sklearn-optimize结合使用,这也是我最喜欢的地方,Optuna因此特性可以被使用于各种各样的优化场景。
2. 导入必要的库及加载数据
用的是sklearn自带的房价数据,只是我把它保存下来了。
import optuna
import pandas as pd
import numpy as np
from sklearn.model_selection import KFold,cross_validate
print(optuna.__version__)
from sklearn.ensemble import RandomForestRegressor as RFR
data = pd.read_csv(r'D:\2暂存文件\Sth with Py\贝叶斯优化\data.csv')
X = data.iloc[:,0:8]
y = data.iloc[:,8]3. 定义目标函数与参数空间
Optuna相对于其他库,不需要单独输入参数或参数空间,只需要直接在目标函数中定义参数空间即可。这里以负均方误差为损失函数。
def optuna_objective(trial) :
# 定义参数空间
n_estimators = trial.suggest_int('n_estimators',10,100,1)
max_depth = trial.suggest_int('max_depth',10,50,1)
max_features = trial.suggest_int('max_features',10,30,1)
min_impurtity_decrease = trial.suggest_float('min_impurity_decrease',0.0, 5.0, step=0.1)
# 定义评估器
reg = RFR(n_estimators=n_estimators,
max_depth=max_depth,
max_features=max_features,
min_impurity_decrease=min_impurtity_decrease,
random_state=1412,
verbose=False,
n_jobs=-1)
# 定义交叉过程,输出负均方误差
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
validation_loss = cross_validate(reg,X,y,
scoring='neg_mean_squared_error',
cv=cv,
verbose=True,
n_jobs=-1,
error_score='raise')
return np.mean(validation_loss['test_score'])4. 定义优化目标函数
在Optuna中我们可以调用sampler模块进行选用想要的优化算法,比如TPE、GP等等。
def optimizer_optuna(n_trials,algo):
# 定义使用TPE或GP
if algo == 'TPE':
algo = optuna.samplers.TPESampler(n_startup_trials=20,n_ei_candidates=30)
elif algo == 'GP':
from optuna.integration import SkoptSampler
import skopt
algo = SkoptSampler(skopt_kwargs={'base_estimator':'GP',
'n_initial_points':10,
'acq_func':'EI'})
study = optuna.create_study(sampler=algo,direction='maximize')
study.optimize(optuna_objective,n_trials=n_trials,show_progress_bar=True)
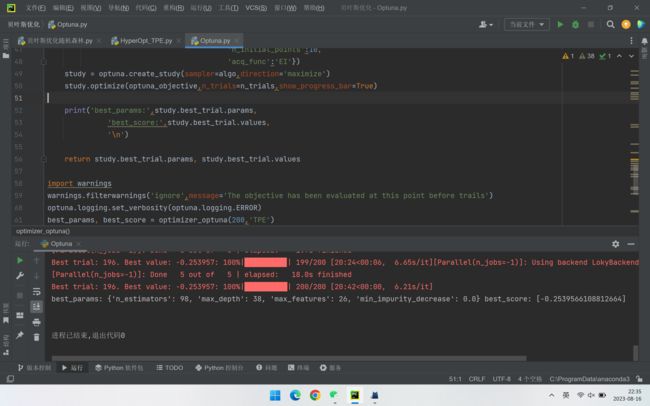
print('best_params:',study.best_trial.params,
'best_score:',study.best_trial.values,
'\n')
return study.best_trial.params, study.best_trial.values5. 执行部分
import warnings
warnings.filterwarnings('ignore',message='The objective has been evaluated at this point before trails')
optuna.logging.set_verbosity(optuna.logging.ERROR)
best_params, best_score = optimizer_optuna(200,'TPE')6. 完整代码
import optuna
import pandas as pd
import numpy as np
from sklearn.model_selection import KFold,cross_validate
print(optuna.__version__)
from sklearn.ensemble import RandomForestRegressor as RFR
data = pd.read_csv(r'D:\2暂存文件\Sth with Py\贝叶斯优化\data.csv')
X = data.iloc[:,0:8]
y = data.iloc[:,8]
def optuna_objective(trial) :
# 定义参数空间
n_estimators = trial.suggest_int('n_estimators',10,100,1)
max_depth = trial.suggest_int('max_depth',10,50,1)
max_features = trial.suggest_int('max_features',10,30,1)
min_impurtity_decrease = trial.suggest_float('min_impurity_decrease',0.0, 5.0, step=0.1)
# 定义评估器
reg = RFR(n_estimators=n_estimators,
max_depth=max_depth,
max_features=max_features,
min_impurity_decrease=min_impurtity_decrease,
random_state=1412,
verbose=False,
n_jobs=-1)
# 定义交叉过程,输出负均方误差
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
validation_loss = cross_validate(reg,X,y,
scoring='neg_mean_squared_error',
cv=cv,
verbose=True,
n_jobs=-1,
error_score='raise')
return np.mean(validation_loss['test_score'])
def optimizer_optuna(n_trials,algo):
# 定义使用TPE或GP
if algo == 'TPE':
algo = optuna.samplers.TPESampler(n_startup_trials=20,n_ei_candidates=30)
elif algo == 'GP':
from optuna.integration import SkoptSampler
import skopt
algo = SkoptSampler(skopt_kwargs={'base_estimator':'GP',
'n_initial_points':10,
'acq_func':'EI'})
study = optuna.create_study(sampler=algo,direction='maximize')
study.optimize(optuna_objective,n_trials=n_trials,show_progress_bar=True)
print('best_params:',study.best_trial.params,
'best_score:',study.best_trial.values,
'\n')
return study.best_trial.params, study.best_trial.values
import warnings
warnings.filterwarnings('ignore',message='The objective has been evaluated at this point before trails')
optuna.logging.set_verbosity(optuna.logging.ERROR)
best_params, best_score = optimizer_optuna(200,'TPE')