CentOS7 搭建Spark集群环境
1、服务器配置
| IP 地址 | 主机名称 | 是否master |
| 192.168.60.204 | master | 是 |
| 192.168.60.205 | node1 | 否 |
2、安装Scala
从https://www.scala-lang.org/download/下载scala 2.13.8,并安装到/usr/local/scala目录下。执行如下命令:
mkdir -p /usr/local/scala #创建scala 文件夹
tar zxvf scala-2.12.8.tgz # 解压官网下载的*.tgz 包接下来配置环境变量,执行命令:vi /etc/profile,打开profile文件,在文件末尾添加scala配置:
export SCALA_HOME=/usr/local/scala/scala-2.12.8
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$HADOOP_HOME/bin:$SQOOP_HOME/bin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin:$HBASE_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin配置好scala环境变量后,执行命令:source /etc/profile,使环境配置生效。
3、搭建Spark集群
从http://spark.apache.org/downloads.html下载spark 2.4.3,在2个服务器中都安装配置Spark。在安装Spark前,先在搭建Hadoop集群,Hadoop集群搭建可以参考:https://blog.csdn.net/zhouzhiwengang/article/details/94549964
第一步:安装Spark 执行如下指令:
mkdir -p /usr/local/spark #创建spark 文件夹
tar -zxvf spark-2.4.3-bin-hadoop2.7.tgz #解压spark 官网下载的spark 包
mv spark-2.4.3-bin-hadoop2.7 spark-2.4.3 # spark 重命名接下来配置环境变量,执行命令:vi /etc/profile,打开profile文件,在文件末尾添加spark配置:
# 配置全局环境变量
vi /etc/profile
#编辑内容如下:
export SPARK_HOME=/usr/local/spark/spark-2.4.3
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$HADOOP_HOME/bin:$SQOOP_HOME/bin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin:$HBASE_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin
#重新定义预编译source /etc/pfofile 文件
第二步:配置Spark
执行命令:cd /usr/local/spark/spark-2.4.3/conf,进入Spark配置目录,执行如下命令复制配置文件:
cp spark-env.sh.template spark-env.sh编辑spark-env.sh
配置jdk、scala、hadoop、ip、master等信息,SPARK_MASTER_IP和 SPARK_MASTER_HOST配置master服务器域名,SPARK_LOCAL_IP为对应spark节点的IP地址,配置如下:
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64
export SCALA_HOME=/usr/local/scala/scala-2.12.8
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.0.3
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-3.0.3/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_MASTER_HOST=master
export SPARK_LOCAL_IP=192.168.60.204
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=1
export SPARK_HOME=/usr/local/spark/spark-2.4.3执行命令:cd /usr/local/spark/spark-2.4.3/conf,进入Spark配置目录,执行如下命令复制配置文件:
cp slaves.template slaves编辑slaves,清除源文件所有内容,配置从节点如下:
node1第三步:spark 拷贝
将master 服务器上配置的spark 拷贝至node1 服务器,执行如下指令:
scp -c /usr/local/spark/* root@node1:/usr/local/spark第四步:启动Spark
在Spark集群中进入master服务器,进入Spark bin目录,如下:
cd /usr/local/spark/spark-2.4.3/sbin在该目录下执行命令:./start-all.sh,即可启动Spark集群。这里要注意一点,在哪个服务器上执行该命令,该服务器将成为主节点,其余服务器都是从节点。
Spark集群启动后,可以执行命令:spark-shell进入集群,并在shell中执行scala命令,如下图所示:
[root@master bin]# spark-shell
2019-07-09 18:06:56,090 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://master:4040
Spark context available as 'sc' (master = local[*], app id = local-1562666830326).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_181)
Type in expressions to have them evaluated.
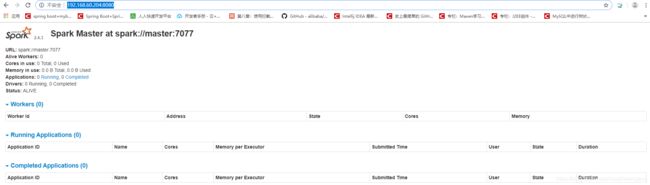
Type :help for more information.也可以打开web页面,端口是8080:http://192.168.60.204:8080/,如下图所示: