搞懂DEtection TRanformer(DETR)
文章目录
- 1 bipartite matching loss
- 2 模型总体框架
-
- 2.1 backbone
- 2.2 transformer
-
- 2.2.1 encoder
- 2.2.2 decoder
- 2.2.3 prediction heads
- 3 模型效果
- 参考文献
本文描述了笔者在阅读了一些文献之后,对 End-to-end Object Detection with Transformers(DETR) 的理解。DETR是一个令人非常兴奋的目标检测模型,它在思路上完全不同于现有的state-of-art的那些目标检测模型,让人对目标检测这个任务重新思考。一句话概括一下,DETR就是一个不用nms,不用anchor,流程非常简洁明了,且基于transformer的state-of-art的目标检测模型。
1 bipartite matching loss
在讲这篇论文之前,先来说一个这篇论文的精华思想——bipartite matching loss。假设我们现在有两个sets,左边的sets是模型预测得到的 N N N个元素,每个元素里有一个bbox和对这个bbox预测的类别的概率分布,预测的类别可以是空,用 ϕ \phi ϕ来表示;右边的sets是我们的ground truth,每个元素里有一个标签的类别和对应的bbox,如果标签的数量不足 N N N则用 ϕ \phi ϕ来补充,, ϕ \phi ϕ可以认为是background。
两边sets的元素数量都是 N N N,所以我们是可以做一个配对的操作,让左边的元素都能找到右边的一个配对元素,每个左边元素找到的右边元素都是不同的,也就是一一对应。这样的组合可以有 N ! N! N!种,所有组合记作 σ N \sigma_N σN。这个 N N N即是模型可以预测的最大数量。

我们的目的是在这所有的 N ! N! N!种中,找到使得 L m a t c h L_{match} Lmatch最小的那个组合,记作 σ ^ \hat{\sigma} σ^。
L m a t c h = − 1 { c i ≠ ϕ } p ^ σ ( i ) ( c i ) + 1 { c i ≠ ϕ } L b o x ( b i , b ^ σ ( i ) ) L_{match} = -\mathbf{1}_{\{c_i \neq \phi\}}\hat{p}_{\sigma (i)}(c_i) + \mathbf{1}_{\{c_i \neq \phi\}}L_{box}(b_i, \hat{b}_{\sigma (i)}) Lmatch=−1{ci=ϕ}p^σ(i)(ci)+1{ci=ϕ}Lbox(bi,b^σ(i))
其中, 1 \mathbf{1} 1是示1符号,后面括号的内容为真时取值1,否则取值0; i i i表示ground truth中的第 i i i个元素; c i c_i ci是ground truth中的第 i i i个class,即 c l a s s i class_i classi; b i b_i bi是ground truth中的第 i i i个bbox,即 b b o x i bbox_{i} bboxi; σ ( i ) \sigma(i) σ(i)是某个组合中ground truth第i个元素对应于predictions中的index; p ^ σ ( i ) \hat{p}_{\sigma(i)} p^σ(i)表示prediction中第 σ ( i ) \sigma(i) σ(i)个probs,即 p r o b s σ ( i ) probs_{\sigma(i)} probsσ(i); b ^ σ ( i ) \hat{b}_{\sigma(i)} b^σ(i)表示prediction中的第 σ ( i ) \sigma(i) σ(i)个bbox,即 b b o x σ ( i ) bbox_{\sigma(i)} bboxσ(i)。
写成目标函数的形式就是
a r g m i n σ ∈ σ N ∑ i N L m a t c h ( y i , y ^ σ ( i ) ) argmin_{\sigma \in \sigma_N} \sum_{i}^{N} L_{match} (y_i, \hat{y}_{\sigma(i)}) argminσ∈σNi∑NLmatch(yi,y^σ(i))
其中的 y y y可以看成class和bbox的一个组合。
在 σ N \sigma_N σN中找使得 L m a t c h L_{match} Lmatch最小的那个组合的方法用的是Hungarian算法,这里不展开说,总之就是一个高效的可以帮我们找到最有最优 σ i \sigma_{i} σi的启发式算法。
这里还有一个没有说到的就是 L b o x L_{box} Lbox。由于文章中所使用的方法是没有预先设计好的anchor的,是直接预测bbox的,所以如果像其他方法那样直接计算 L 1 L_1 L1 loss的话,就会导致对于大的框和小的框的惩罚力度不一致,所以文章在使用 L 1 L_1 L1 loss的同时,也使用了scale-invariant的IoU loss。
L b o x ( b i , b ^ σ ( i ) ) = λ i o u L i o u ( b i , b ^ σ ( i ) ) + λ L 1 ∣ ∣ b i − b ^ σ ( i ) ∣ ∣ 1 L_{box}(b_i, \hat{b}_{\sigma (i)}) = \lambda_{iou}L_{iou}(b_i, \hat{b}_{\sigma (i)}) + \lambda_{L_1}||b_i - \hat{b}_{\sigma(i)}||_1 Lbox(bi,b^σ(i))=λiouLiou(bi,b^σ(i))+λL1∣∣bi−b^σ(i)∣∣1
其中, λ i o u \lambda_{iou} λiou和 λ L 1 \lambda_{L_1} λL1是超参数。
注意这里的 L m a t c h L_{match} Lmatch是帮我们找最小组合的时候,Hungarian算法所使用的loss,并不是训练模型的loss,并不是训练模型的loss,并不是训练模型的loss!!!
找到match之后,训练模型用的loss是
L H u n g a r i a n ( y , y ^ ) = ∑ 1 N [ − l o g p ^ σ ^ ( i ) ( c i ) + 1 { c i ≠ ϕ } L b o x ( b i , b ^ σ ( i ) ) ] L_{Hungarian}(y, \hat{y}) = \sum_{1}^{N} [-log\hat{p}_{\hat{\sigma} (i)}(c_i) + \mathbf{1}_{\{c_i \neq \phi\}}L_{box}(b_i, \hat{b}_{\sigma (i)})] LHungarian(y,y^)=1∑N[−logp^σ^(i)(ci)+1{ci=ϕ}Lbox(bi,b^σ(i))]
注意这里和 L m a t c h L_{match} Lmatch的区别,在于从 − 1 { c i ≠ ϕ } p ^ σ ( i ) ( c i ) -\mathbf{1}_{\{c_i \neq \phi\}}\hat{p}_{\sigma (i)}(c_i) −1{ci=ϕ}p^σ(i)(ci)变成了 − l o g p ^ σ ^ ( i ) ( c i ) -log\hat{p}_{\hat{\sigma} (i)}(c_i) −logp^σ^(i)(ci)。也就是说我们在找match的时候,把和ground truth类别一致的,且bbox最接近的预测结果对应上就完事了,其他那些 ϕ \phi ϕ,模型预测出来啥,我match并不关心。但是在算训练模型的Hungarian loss时,就不一样了,我不希望模型会预测出乱七八糟的结果, ϕ \phi ϕ就是 ϕ \phi ϕ,没有就是没有,别整得似有似无的,该 ϕ \phi ϕ的时候预测出东西了,就要惩罚你。因为我预测的时候可是没有ground truth的,我没法知道哪几个是对的了。
至于为啥不在 L m a t c h L_{match} Lmatch的时候就用 l o g log log,作者解释说是为了和 L b o x L_{box} Lbox相对称,经验的结果。我估计是用了 l o g log log的话,Hungarian算法计算量会变大吧。
2 模型总体框架
DETR的模型架构非常简单,所以这也使得它在几乎所有深度学习框架下都可以实现,只要有CNN和transformer就可以了。总体框架如下图所以,可以拆分为backbone,encoder,decoder和prediction heads四个部分。
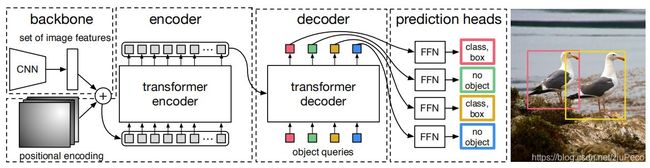
2.1 backbone
backbone就是一个传统的CNN模型,作用是抽取图片的特征信息。假设输入是 H 0 × W 0 × 3 H_0 \times W_0 \times 3 H0×W0×3的一张图片,那么输出就是一个 H 32 × W 32 × 2048 \frac{H}{32} \times \frac{W}{32} \times 2048 32H×32W×2048的一个特征,记作 H × W × C H \times W \times C H×W×C。
2.2 transformer
encoder,decoder和FFN共同构成了transformer,如下图所示,和经典的transformer没有太大的区别,结构上没什么要说的,不了解transformer的小伙伴可以参见我的另一篇博客 – 搞懂transformer。用attention来做的好处就是,attention可以看到全局的信息,大框小框,不管什么奇形怪状的框,分分钟给你搞出来。
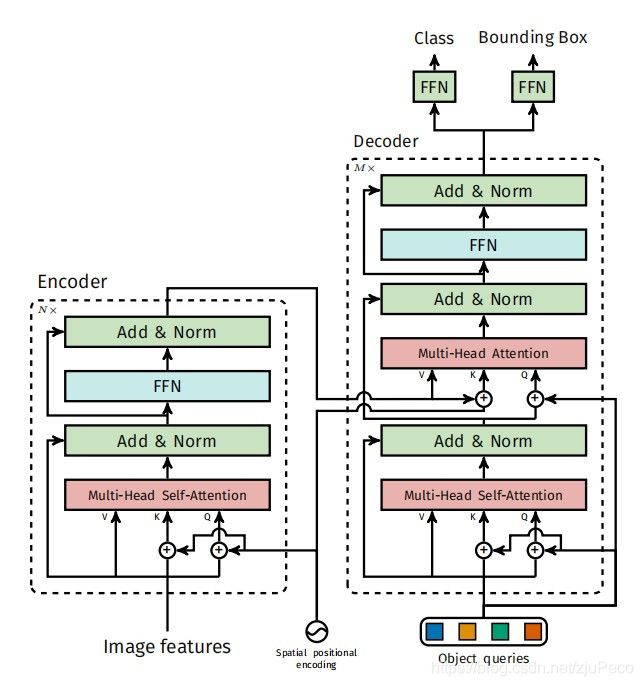
2.2.1 encoder
encoder会接收图像特征,但是在此之前也会过一下一个 1 × 1 1 \times 1 1×1的CNN,用来给特征层压缩,从 C C C降到 d d d。又因为encoder吃的是一个序列,所以还要把这个 H × W × C H \times W \times C H×W×C的拉成 H W × C HW \times C HW×C。
然后把这个特征和一个用于提供图像位置信息的positional encodings一起作为encoder的输入。
2.2.2 decoder
decoder的输入是encoder的输出,positional encodings以及一个叫做object queries的向量。这个object queries是个比较神奇的东西,它是学出来的。我们先来看一下在这些object queries下,预测出来的框是什么样子的。

上图中,每个图都是一个object query在COCO 2017 val set预测出来的框的结果。图中的每个点都是一个框的中心点,绿色表示小框,红色表示横向的大框,蓝色表示纵向的大框。可见每个query都有自己的特点,比如第一个query会一直问左边的小框里是什么,第二个会问中间的大框是什么,等等。我们可以把每个object query看成一个关注于某个区域,某些大小物体的提问者。然后这些提问者就是模型训练出来的提问者,各有所长。
2.2.3 prediction heads
最后的prediction heads就是几层全连接,用来输出预测的类别和框的位置大小。
3 模型效果
不管模型里有多少奇思妙想,最终的效果才是真家伙,是我们最关心的。那么这个DETR的效果如何呢?作者在COCO数据集上把DETR和Faster RCNN做了比较,下表就是比较的结果。
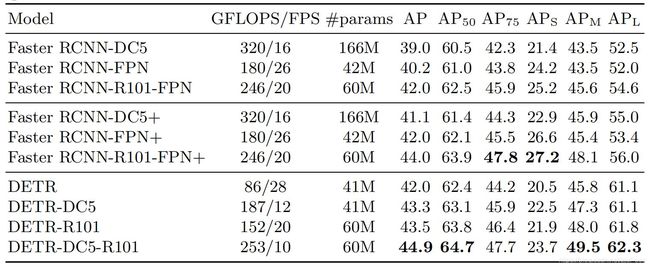
表中两个区域都是Faster RCNN,backbone还都是重复的,别急,这个不是作者顺手多复制了几行。上面的是Detectron2的Faster RCNN的结果,中间的是用了GIoU, random crops train-time augmentation和the long 9x training schedule这些技巧的Faster RCNN的结果,最下面自然是DETR的结果。可见DETR和用了各种技巧的Faster RCNN效果差不多,还是很棒的。
得益于其独特的loss,DETR对于相邻的实例有着很好的区分效果。从下图中可以看出,attention学的很棒。

不够看的话,我们再来看一副把attention对应到原图上的。attention很机智的把物体的边界给学出来了。

除此之外,DETR还可以拓展到全景分割。这块我没怎么看,这里就不细讲了。
参考文献
[1] End-to-end Object Detection with Transformers
[2] https://www.youtube.com/watch?v=T35ba_VXkMY
[3] https://www.kaggle.com/tanulsingh077/end-to-end-object-detection-with-transformers-detr