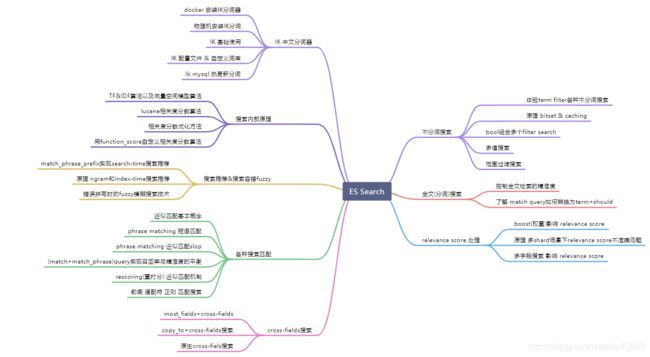
ElasticSearch 7.7.0 高级篇-搜索技术
前言
有了前面的理论知识和上机实操的经验,那么下面我们将使用程序开发es。当然本篇说白了就是前面知识的总结和回顾。
一 ES不分词(exact value)搜索
1.1 实战体验term filter各种不分词搜索
term filter/query:对搜索文本不分词,它直接拿条件去倒排索引中匹配。
例如:term :“hello world” --> “hello world”,直接去倒排索引中匹配“hello world”。
反过来如果对搜索文本分词的话。则“helle world” --> “hello”和“world”,两个词分别去倒排索引中匹配。
term filter/query::根据exact value搜索,数字、boolean、date天然支持
1.1.1 初始化数据
POST /forum/_bulk
{ "index": { "_id": 1 }}
{ "articleID" : "XHDK-A-1293-#fJ3", "userID" : 1, "hidden": false, "postDate": "2017-01-01" }
{ "index": { "_id": 2 }}
{ "articleID" : "KDKE-B-9947-#kL5", "userID" : 1, "hidden": false, "postDate": "2017-01-02" }
{ "index": { "_id": 3 }}
{ "articleID" : "JODL-X-1937-#pV7", "userID" : 2, "hidden": false, "postDate": "2017-01-01" }
{ "index": { "_id": 4 }}
{ "articleID" : "QQPX-R-3956-#aD8", "userID" : 2, "hidden": true, "postDate": "2017-01-02" }1.1.2 数字不分词搜索测试
查询ueserId=1的数据,结果应该是两个
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"userID": 1
}
}
}
}
}1.1.3 boolean不分词搜索测试
搜索没有隐藏的帖子hidden=false ,结果应该是3条
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"hidden": false
}
}
}
}
}1.1.4 Date不分词搜索测试
搜索发帖日期 postDate=2017-01-01 的帖子,结果应该是2条
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"postDate": "2017-01-01"
}
}
}
}
}1.1.5 Text 利用keyword不分词搜索
我们如果直接搜索 articleID=XHDK-A-1293-#fJ3 的帖子,看上去结果应该有1条,其实是没有的。因为 用搜索文本(XHDK-A-1293-#fJ3) 去匹配 分词 xhdk,a,1293,fj3,肯定匹配不到。
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"articleID": "XHDK-A-1293-#fJ3"
}
}
}
}
}我们可以查看下分词
GET /forum/_analyze
{
"field": "articleID",
"text": "XHDK-A-1293-#fJ3"
}articleID 默认是analyzed的text类型的field,建立倒排索引的时候,就会对所有的articleID分词,分词以后,原本的articleID就没有了,只有分词后的各个word存在于倒排索引中,即 XHDK-A-1293-#fJ3 --> xhdk,a,1293,fj3。
term 是不对搜索文本分词的(即 XHDK-A-1293-#fJ3 --> XHDK-A-1293-#fJ3);但是articleID建立索引是分词的(即XHDK-A-1293-#fJ3 --> xhdk,a,1293,fj3),因此他们不能匹配上。
keyword 不分词搜索
articleID.keyword,是es最新版本内置建立的field,就是不分词的。所以一个articleID过来的时候,会建立两次索引,一次是自己本身,是要分词的,分词后放入倒排索引;另外一次是基于articleID.keyword,不分词,保留256个字符最多,直接一个字符串放入倒排索引中。
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"articleID.keyword": "XHDK-A-1293-#fJ3"
}
}
}
}
}所以term filter,对text过滤,可以考虑使用内置的field.keyword来进行匹配。但是有个问题,默认就保留256个字符。所以尽可能还是自己去手动建立索引。
1.1.6 Text 自定义不分词搜索
自定义mapping
DELETE /forum
PUT /forum
{
"mappings": {
"properties": {
"articleID": {
"type": "keyword"
}
}
}
}
POST /forum/_bulk
{"index":{"_id":1}}
{"articleID":"XHDK-A-1293-#fJ3","userID":1,"hidden":false,"postDate":"2017-01-01"}
{"index":{"_id":2}}
{"articleID":"KDKE-B-9947-#kL5","userID":1,"hidden":false,"postDate":"2017-01-02"}
{"index":{"_id":3}}
{"articleID":"JODL-X-1937-#pV7","userID":2,"hidden":false,"postDate":"2017-01-01"}
{"index":{"_id":4}}
{"articleID":"QQPX-R-3956-#aD8","userID":2,"hidden":true,"postDate":"2017-01-02"}articleID已经设置为不分词(即XHDK-A-1293-#fJ3 --> XHDK-A-1293-#fJ3),且 term 是不对搜索文本分词的(即 XHDK-A-1293-#fJ3 --> XHDK-A-1293-#fJ3)因此他们不能匹配上。
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"articleID": "XHDK-A-1293-#fJ3"
}
}
}
}1.2 原理 bitset & caching
假设 一个倒排索引
| word |
doc1 |
doc2 |
doc3 |
| 2017-01-01 |
* |
* |
|
| 2017-02-02 |
|
* |
* |
| 2017-03-03 |
* |
* |
* |
- filter :2017-02-02条件 去获取匹配的doc list doc2,doc3
- 构建一个bitset,就是一个二进制的数组,数组每个元素都是0或1,用来标识一个doc对一个filter条件是否匹配,如果匹配就是1,不匹配就是0,即 [0, 1, 1]。(为啥用 0,1二进制表示,而不是用 true false来的更直观)因为对计算机而言 二进制语言 是最基本的机器语言,因此节省了一堆转化,提升内存空间和性能,因此我们以后设计功能的时候往往优先考虑最简单的数据结构。
- 遍历每个过滤条件对应的bitset,优先从最稀疏(匹配比较少的,即1最少的)的开始搜索。先遍历比较稀疏的bitset,就可以先过滤掉尽可能多的数据。
- 例如:请求:filter,postDate=2017-01-01,userID=1
假设bitset 1 是:postDate: [0, 0, 1, 1, 0, 0]
假设bitset 2 是:userID: [0, 1, 0, 1, 0, 1]
则 返回第四个结果,即doc4 给client。
- caching bitset,跟踪query,在最近256个query中超过一定次数的过滤条件,缓存其bitset。对于小segment(<1000,或<3%),不缓存bitset。
例如postDate=2017-01-01,[0, 0, 1, 1, 0, 0],可以缓存在内存中,这样下次如果再有这个条件过来的时候,就不用重新扫描倒排索引,反复生成bitset,可以大幅度提升性能。
在最近的256个filter中,有某个filter超过了一定的次数(次数不固定),就会自动缓存这个filter对应的bitset
segment,filter针对小segment获取到的结果,可以不缓存,segment记录数<1000,或者segment大小 segment数据量很小,此时哪怕是扫描也很快;segment会在后台自动合并,小segment很快就会跟其他小segment合并成大segment,此时就缓存也没有什么意义,segment很快就消失了 针对一个小segment的bitset,[0, 0, 1, 0] filter比query的好处就在于会caching,但是之前不知道caching的是什么东西,实际上并不是一个filter返回的完整的doc list数据结果。而是filter bitset缓存起来。下次不用扫描倒排索引了。 搜索发帖日期为2017-01-01,或者帖子ID为XHDK-A-1293-#fJ3的帖子,同时要求帖子的发帖日期绝对不为2017-01-02 sql语法为: where (post_date='2017-01-01' or article_id='XHDK-A-1293-#fJ3') and post_date!='2017-01-02' es 语法为: 搜索帖子ID为XHDK-A-1293-#fJ3,或者是帖子ID为JODL-X-1937-#pV7而且发帖日期为2017-01-01的帖子 sql语法为: where article_id='XHDK-A-1293-#fJ3' or (article_id='JODL-X-1937-#pV7' and post_date='2017-01-01') es 语法为: 注意 bool must should must_not是可以嵌套的 我们前面都是单个值搜索 即,term: {"field": "value"},多值搜索 即terms: {"field": ["value1","value2"]} sql语法为: col in ("value1", "value2") 我们还是沿用前面的数据,这里插入些测试数据:为帖子数据增加tag字段 搜索articleID为KDKE-B-9947-#kL5或QQPX-R-3956-#aD8的帖子, 搜索tag中包含java的帖子 新增字段 tag_cnt 表示几个 tag标签 ,如果仅仅是java 则是 tag_cnt=1 为帖子数据增加浏览量的字段 view_cnt 表示帖子浏览次数 gte 大于等于 gt 大于 lte 小于等于 lt 小于 准备数据 查询语法 now||-30d 即当前时间的前30天 为帖子增加标题字段 match query 是负责进行全文检索的。当然如果要检索的field是not_analyzed类型的,那么match query也相当于term query。 结果是包含 java、elasticsearch、java&elasticsearch 的三种情况都有的 如果你是希望所有的搜索关键字java elasticsearch都要匹配的,那么就用and,可以实现单纯match query无法实现的效果 minimum_should_match 指定一些关键字中,必须至少匹配其中的多少个关键字,才能作为结果返回 默认情况下,should是可以不匹配任何一个的,比如上面的搜索中,this is java blog,就不匹配任何一个should条件,但是有个例外的情况,如果没有must的话,那么should中必须至少匹配一个才可以 比如下面的搜索,should中有4个条件,默认情况下,只要满足其中一个条件,就可以匹配作为结果返回 但是可以精准控制,should的4个条件中,至少匹配几个才能作为结果返回 搜索条件的权重,boost,可以将某个搜索条件的权重加大,此时当匹配这个搜索条件和匹配另一个搜索条件的document,计算relevance score时,匹配权重更大的搜索条件的document,relevance score会更高,当然也就会优先被返回回来。 默认情况下,搜索条件的权重都是一样的,都是1 需求:搜索标题中必须包含blog的帖子,然后标题中至少包含一个或0个: java || hadoop || elasticsearch || spark,并且spark优先。 如果你的一个index有多个shard的话,可能搜索结果会不准确。 因为搜索 会打到多个shard中 比如 节点1 包含java的doc有10个 ,那么10个doc的相关度就会拉低(数量多被平均了),节点2 包含java的doc有1个,那么他的相关度分数就很高,反而排在前面。 计算一个doc的相关度分数的时候,就会将所有shard对的local IDF计算一下,获取出来,在本地进行global IDF分数的计算,会将所有shard的doc作为上下文来进行计算,也能确保准确性。但是production生产环境下,不推荐这个参数,因为性能很差。 为帖子数据增加content字段 搜索title或content中包含java或solution的帖子 id 2 排在前面因为 tile 包含java content 包含java , id 5 排在2后面 只有content 包含 java solution。 很容易得知符合多个条件(field)的doc排在前面,而符合某一个条件field,就算符合度比较高(即条件的值都符合),也只能排在后面。因为relevance score 的计算方式决定的。 relevance score 的计算方式: 假设: 两个条件都匹配,一个条件不匹配, 即 匹配1:是x字段 score 假设 2分 匹配2: 是y字段 score 假设 2分 不匹配1:z字段,0分 则得知: matched query count 是 2 (匹配两个条件) query count 是3(一个三个条件) relevance score=(2[x的分数]+2[y的分数])* 2[matched query count]/3[query count]=2.666666 按照这个公式 (doc2=(2+2)*2/2=4 )> (doc5=(2)*2/2=2) ,当然排在前面。这种策略也无可厚非。 但是我们往往不关心条件的匹配总数量,而是关心某一个条件最高的匹配度,比如doc5 ,虽然两个条件只匹配上了conent,但是他匹配conent的两个值。所以希望doc5 排在前面。因此es提供了best fields策略,即优先某一个field中匹配到了尽可能多的关键词。 best fields策略 它是指某一个field中匹配到了尽可能多的关键词,排在前面;而不是尽可能多的field匹配到了少数的关键词,排在了前面。因此他只关心 某一个field 匹配的值越多越靠前。 搜索title或content中包含java beginner的帖子 dis_max,只是取分数最高的那个query的分数而已,完全不考虑其他query的分数,使用tie_breaker将其他query的分数也考虑进去。 tie_breaker参数的意义,在于说,将其他query的分数,乘以tie_breaker,然后综合与最高分数的那个query的分数,综合在一起进行计算。 tie_breaker的值,在0~1之间。 minimum_should_match 去长尾 ,控制搜索结果的精准度,只有匹配一定数量的关键词的数据,才能返回。 xxx^2 即权重2倍 等同于下面的方式 best-fields策略,主要是说将某一个field匹配尽可能多的关键词的doc优先返回回来 most-fields策略,主要是说尽可能返回更多field匹配到某个关键词的doc,优先返回回来 设置mapping 新增字段 查询测试 doc1 ( learning more courses) doc2 ( learned a lot of course) 分数一样,那么为啥不应该是 doc2在最前面,最高。 sub_title用的是enligsh analyzer,所以还原了单词,就会将单词还原为其最基本的形态 learning --> learn learned --> learn courses --> course sub_titile: learned course --> learn course 因此他两就是一样了,没法排序。 但是我们前面新增了不处理时态的分词器。 很显然 doc2 最匹配排在最前面 doc1 ( learning more courses) sub_title 匹配数:3 sub_title.std 匹配数: 0 doc2 ( learned a lot of course) sub_title 匹配数:2 sub_title.std 匹配数: 1 如果是best_fields 那么doc1 排在前面,以为他关心匹配数最大的field ,field的匹配数越大越靠前 如果是most_fields 那么doc2 排在前面,他关心匹配上的field的数量,即field匹配的数量越多越靠前 cross-fields搜索,一个唯一标识,跨了多个field。比如一个人,标识,是姓名;一个建筑,它的标识是地址。姓名可以散落在多个field中,比如first_name和last_name中,地址可以散落在country,province,city中。 跨多个field搜索一个标识,比如搜索一个人名,或者一个地址,就是cross-fields搜索 初步来说,如果要实现,可能用most_fields比较合适。因为best_fields是优先搜索单个field最匹配的结果。 问题1:只是找到尽可能多的field匹配的doc,而不是某个field完全匹配的doc 问题2:most_fields,没办法用minimum_should_match去掉长尾数据,就是匹配的特别少的结果 问题3:TF/IDF算法,比如Peter Smith和Smith Williams,搜索Peter Smith的时候,由于first_name中很少有Smith的,所以query在所有document中的频率很低,得到的分数很高,可能Smith Williams反而会排在Peter Smith前面 用copy_to,将多个field组合成一个field。 用了这个copy_to语法之后,就可以将多个字段的值拷贝到一个字段中,并建立倒排索引 什么是近似匹配。 举个例子: java is my favourite programming language, and I also think spark is a very good big data system. java spark are very related, because scala is spark's programming language and scala is also based on jvm like java. match query,搜索java spark { "match": { "content": "java spark" } } match query,只能搜索到包含java和spark的document,但是不知道java和spark是不是离的很近 如果说,要实现两个需求: 1、java spark,就靠在一起,中间不能插入任何其他字符,就要搜索出来这种doc 2、java spark,但是要求,java和spark两个单词靠的越近,doc的分数越高,排名越靠前 要实现上述两个需求,用match做全文检索,是搞不定的,必须得用proximity match,近似匹配 phrase match:短语匹配 proximity match:近似匹配 插入一个短语 match_phrase语法 虽然是短语匹配,他其实还是去分词的,只不过,他首先过滤到 必须包含 两个分词的doc,然后比较java的position 与spark的position,必须是spark的position减去java的position等于1 ,即spark在java的后面。 slop 的值表示的是最多移动几次能匹配上。 结果是 : doc2 [ this is java blog] doc1 [this is java and elasticsearch blog] doc4 [this is java, elasticsearch, hadoop blog] 所以 doc2 移动0次 就可以匹配 ,doc1 移动两次 就能匹配 doc4 移动两次就能匹配 并且 移动距离越近,排名越靠前 召回率(recall) 比如你搜索一个java spark,总共有100个doc,能返回多少个doc作为结果,就是召回率,recall 精准度(precision) 比如你搜索一个java blog,能不能尽可能让包含java blog,或者是java和blog离的很近的doc,排在最前面,precision 近似匹配的时候,召回率比较低,精准度太高了。 就是优先满足召回率,即,java blog,包含java的也返回,包含blog的也返回,包含java和blog的也返回;同时兼顾精准度,就是包含java和blog,同时java和blog离的越近的doc排在最前面 此时可以用bool组合match query和match_phrase query一起,来实现上述效果 第一个匹配就是全文检索,第二个匹配就是利用相似匹配提供精准度。即java blog 排在了前面。 match和phrase match(proximity match)区别是: match --> 只要简单的匹配到了一个term,就可以理解将term对应的doc作为结果返回。 phrase match --> 首先扫描到所有term的doc list; 找到包含所有term的doc list; 然后对每个doc都计算每个term的position,是否符合指定的范围; slop,需要进行复杂的运算,来判断能否通过slop移动,匹配一个doc match query的性能比phrase match和proximity match(有slop)要高很多。因为后两者都要计算position的距离。 match query比phrase match的性能要高10倍,比proximity match的性能要高20倍。 但是别太担心,因为es的性能一般都在毫秒级别,match query一般就在几毫秒,或者几十毫秒,而phrase match和proximity match的性能在几十毫秒到几百毫秒之间,所以也是可以接受的。 优化proximity match的性能,一般就是减少要进行proximity match搜索的document数量。主要思路就是,用match query先过滤出需要的数据,然后再用proximity match来根据term距离提高doc的分数,同时proximity match只针对每个shard的分数排名前n个doc起作用,来重新调整它们的分数,这个过程称之为rescoring,重计分。因为一般用户会分页查询,只会看到前几页的数据,所以不需要对所有结果进行proximity match操作。 用我们刚才的说法,match + proximity match同时实现召回率和精准度 默认情况下,match也许匹配了1000个doc,proximity match全都需要对每个doc进行一遍运算,判断能否slop移动匹配上,然后去贡献自己的分数 但是很多情况下,match出来也许1000个doc,其实用户大部分情况下是分页查询的,所以可能最多只会看前几页,比如一页是10条,最多也许就看5页,就是50条 proximity match只要对前50个doc进行slop移动去匹配,去贡献自己的分数即可,不需要对全部1000个doc都去进行计算和贡献分数 rescore:重打分 match:1000个doc,其实这时候每个doc都有一个分数了; proximity match,前50个doc,进行rescore,重打分,即可; 让前50个doc,term举例越近的,排在越前面 假设三个字段 C3D0-KD345 、C3K5-DFG65、C4I8-UI365 则 C3 --> 上面这两个都搜索出来 --> 根据字符串的前缀去搜索 准备测试数据 前缀搜索测试 前缀搜索的原理 prefix query不计算relevance score,与prefix filter唯一的区别就是,filter会cache bitset 扫描整个倒排索引,前缀越短,要处理的doc越多,性能越差,尽可能用长前缀搜索。 假设字符串 C3-D0-KD345 C3-K5-DFG65 C4-I8-UI365 word doc1 doc2 doc3 c3 * * d0 * kd345 * k5 * dfg65 * * i8 * ui365 * match 全文搜索 c3 --> 扫描倒排索引 --> 一旦扫描到c3,就可以停了,因为带c3的就2个doc,已经找到了 没有必要继续去搜索其他的term了,因此match性能往往是很高的。 不分词 c3 --> 先扫描到了C3-D0-KD345,找到了一个前缀带c3的字符串 --> 还是要继续搜索的,因为后面还有一个C3-K5-DFG65,也许还有其他很多的前缀带c3的字符串 ,必须继续搜索直到扫描完整个的倒排索引,才能结束,因此 prefix性能很差。 他跟前缀搜索类似,功能更加强大 C3D0-KD345 C3K5-DFG65 C4I8-UI365 5字符-D任意个字符55?-*5:通配符去表达更加复杂的模糊搜索的语义 ?:任意字符 *:0个或任意多个字符 性能一样差,必须扫描整个倒排索引,才ok C[0-9].+ [0-9]:指定范围内的数字 [a-z]:指定范围内的字母 .:一个字符 +:前面的正则表达式可以出现一次或多次 wildcard和regexp,与prefix原理一致,都会扫描整个索引,性能很差。在实际应用中,能不用尽量别用。性能太差了。 搜索推荐,search as you type,搜索提示 原理跟match_phrase类似,唯一的区别,就是把最后一个term作为前缀去搜索 java 就是去进行match,搜索对应的doc。b,会作为前缀,去扫描整个倒排索引,找到所有b开头的doc 然后找到所有doc中,即包含java,又包含b开头的字符的doc。 也可以根据你的slop去计算,看在slop范围内,能不能让java b,正好跟doc中的java和b开头的单词的position相匹配 也可以指定slop,但是只有最后一个term会作为前缀 max_expansions:指定prefix最多匹配多少个term,超过这个数量就不继续匹配了,限定性能 默认情况下,前缀要扫描所有的倒排索引中的term,去查找b打头的单词,但是这样性能太差。可以用max_expansions限定,b前缀最多匹配多少个term,就不再继续搜索倒排索引了。 尽量不要用,因为,最后一个前缀始终要去扫描大量的索引,性能可能会很差 ngram 其实就是单词拆分的步长。例如: quick,5种长度下的ngram ngram length=1,q u i c k ngram length=2,qu ui ic ck ngram length=3,qui uic ick ngram length=4,quic uick ngram length=5,quick 什么是edge ngram,首字母后进行ngram。例如 q qu qui quic quick 切分单词后 保存在倒排索引中。 搜索的时候,不用再根据一个前缀,然后扫描整个倒排索引了; 简单的拿前缀去倒排索引中匹配即可,如果匹配上了,那么就好了; match,全文检索 如果用match,只有hello的也会出来,全文检索,只是分数比较低 推荐使用match_phrase,要求每个term都有,而且position刚好靠着1位,符合我们的期望的 搜索的时候,可能输入的搜索文本会出现误拼写的情况 doc1: hello world doc2: hello java 搜索:hallo world fuzzy搜索技术 --> 自动将拼写错误的搜索文本,进行纠正,纠正以后去尝试匹配索引中的数据 surprize --> 拼写错误 --> surprise --> s -> z surprize --> surprise -> z -> s,纠正一个字母,就可以匹配上,所以在fuziness指定的2范围内 surprize --> surprised -> z -> s,末尾加个d,纠正了2次,也可以匹配上,在fuziness指定的2范围内 surprize --> surprising -> z -> s,去掉e,ing,3次,总共要5次,才可以匹配上,始终纠正不了 fuzzy搜索以后,会自动尝试将你的搜索文本进行纠错,然后去跟文本进行匹配 fuzziness,你的搜索文本最多可以纠正几个字母去跟你的数据进行匹配,默认如果不设置,就是2 1.boolean model 类似and这种逻辑操作符,先过滤出包含指定term的doc query "hello world" --> 过滤 --> hello / world / hello & world bool --> must/must not/should --> 过滤 --> 包含 / 不包含 / 可能包含 doc --> 不打分数 --> 正或反 true or false --> 为了减少后续要计算的doc的数量,提升性能 2.TF/IDF 单个term在doc中的分数 假设: query: hello world --> doc.content doc1: java is my favourite programming language, hello world !!! doc2: hello java, you are very good, oh hello world!!! 则: a. TF: term frequency b. IDF:inversed document frequency 找到hello在所有的doc中出现的次数,这里3次一个term在所有的doc中,出现的次数越多,那么最后给 的相关度评分就会越低 c. length norm hello搜索的那个field的长度,field长度越长,给的相关度评分越低; field长度越短,给的相关度评越高 最后,会将hello这个term,对doc1的分数,综合TF,IDF,length norm,计算出来一个综合性的分数 hello world --> doc1 --> hello对doc1的分数,world对doc1的分数 --> 但是最后hello world query要对doc1有一个总的分数 --> vector space model 多个term对一个doc的总分数 hello world --> es会根据hello world在所有doc中的评分情况,计算出一个query vector,query向量 假设:query 'java world ' , query vector=[2,5] doc1 一个包含1个term:hello 其doc vector=[2,0]、 doc2 一个包含1个term: world 其doc vector=[0,5]、 doc3一个包含2个term :hello world 其doc vector=[2,5] hello这个term,给的基于所有doc的一个评分就是2,world这个term,给的基于所有doc的一个评分就是5会给每一个doc,拿每个term计算出一个分数来,hello有一个分数,world有一个分数,再拿所有term的分数组成一个doc vector 每个doc vector计算出对query vector的弧度,最后基于这个弧度给出一个doc相对于query中多个term的总分数,弧度越大,分数越低; 弧度越小,分数越高 深入讲解TF/IDF算法,在lucene中,底层 Lucene 提供一个 practical scoring function,来计算一个query对一个doc的分数的公式,该函数会使用一个公式来计算。 这个公式的最终结果,就是说是一个query(叫做q),对一个doc(叫做d)的最终的总评分 对相关度评分进行调节和优化的常见的4种方法 重构查询结果,在es新版本中,影响越来越小了。一般情况下,没什么必要的话,大家不用也行。 搜索包含java,不包含spark的doc,但是这样子很死板 搜索包含java,尽量不包含spark的doc,如果包含了spark,不会说排除掉这个doc,而是说将这个doc的分数降低,即包含了negative term的doc,分数乘以negative boost,分数降低 如果你压根儿不需要相关度评分,直接走constant_score加filter,所有的doc分数都是1,没有评分的概念了 我们可以做到自定义一个function_score函数,自己将某个field的值,跟es内置算出来的分数进行运算,然后由自己指定的field来进行分数的增强 给所有的帖子数据增加follower数量 将对帖子搜索得到的分数,跟follower_num进行运算,由follower_num在一定程度上增强帖子的分数 看帖子的人越多,那么帖子的分数就越高 重启es docker ps -a | grep elasticsearch | awk '{print $1 }' | xargs docker container restart ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合; ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。 所以一般选择ik_max_word 查看分词分析 搜索测试 每年都会涌现一些特殊的流行词,网红,蓝瘦香菇,喊麦,鬼畜,一般不会在ik的原生词典里,需要自己补充自己的最新的词语,到ik的词库里面去。 自己建立词库 IKAnalyzer.cfg.xml 的属性ext_dict里配置路径,custom/mydict.dic 补充自己的词语,然后需要重启es,才能生效 自己建立停用词库:比如了,的,啥,么,我们可能并不想去建立索引,让人家搜索 custom/ext_stopword.dic,已经有了常用的中文停用词,可以补充自己的停用词,然后重启es 热更新 es不停机,直接我们在外部某个地方添加新的词语,es中立即热加载到这些新词语。 手动添加新词语: 热更新的方案 https://github.com/medcl/elasticsearch-analysis-ik/tree/v7.7.0 Dictionary类,169行:Dictionary单例类的初始化方法,在这里需要创建一个我们自定义的线程,并且启动 它 HotDictReloadThread类:就是死循环,不断调用Dictionary.getSingleton().reLoadMainDict(),去重新加载 词典 Dictionary类,389行:this.loadMySQLExtDict(); Dictionary类,683行:this.loadMySQLStopwordDict(); target\releases\elasticsearch-analysis-ik-7.7.0.zip 将mysql驱动jar,放入ik的目录下 观察日志,日志中就会显示我们打印的那些东西,比如加载了什么配置,加载了什么词语,什么停用词
1.3 实战 bool组合多个filter search
1.3.1 多个条件 或 且
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"should": [
{
"term": {
"postDate": "2017-01-01"
}
},
{
"term": {
"articleID": "XHDK-A-1293-#fJ3"
}
}
],
"must_not": {
"term": {
"postDate": "2017-01-02"
}
}
}
}
}
}
}
1.3.2 多个条件 或 且
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"should": [
{
"term": {
"articleID": "XHDK-A-1293-#fJ3"
}
},
{
"bool": {
"must": [
{
"term": {
"articleID": "JODL-X-1937-#pV7"
}
},
{
"term": {
"postDate": "2017-01-01"
}
}
]
}
}
]
}
}
}
}
}1.4 实战 多值搜索
1.4.1 初始化数据
POST /forum/_bulk
{"update":{"_id":"1"}}
{"doc":{"tag":["java","hadoop"]}}
{"update":{"_id":"2"}}
{"doc":{"tag":["java"]}}
{"update":{"_id":"3"}}
{"doc":{"tag":["hadoop"]}}
{"update":{"_id":"4"}}
{"doc":{"tag":["java","elasticsearch"]}}1.4.2 多值搜索不限定匹配值的个数
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"terms": {
"articleID": [
"KDKE-B-9947-#kL5",
"QQPX-R-3956-#aD8"
]
}
}
}
}
}GET /forum/_search
{
"query" : {
"constant_score" : {
"filter" : {
"terms" : {
"tag" : ["java"]
}
}
}
}
}1.4.3 多值搜索优化限定匹配值的个数
POST /forum/_bulk
{"update":{"_id":"1"}}
{"doc":{"tag_cnt":2}}
{"update":{"_id":"2"}}
{"doc":{"tag_cnt":1}}
{"update":{"_id":"3"}}
{"doc":{"tag_cnt":1}}
{"update":{"_id":"4"}}
{"doc":{"tag_cnt":2}}
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"must": [
{
"term": {
"tag_cnt": 1
}
},
{
"terms": {
"tag": [
"java"
]
}
}
]
}
}
}
}
}1.5 实战 范围过滤搜索
1.5.1 准备数据
POST /forum/_bulk
{"update":{"_id":"1"}}
{"doc":{"view_cnt":30}}
{"update":{"_id":"2"}}
{"doc":{"view_cnt":50}}
{"update":{"_id":"3"}}
{"doc":{"view_cnt":100}}
{"update":{"_id":"4"}}
{"doc":{"view_cnt":80}}1.5.2 搜索浏览量在30~60之间的帖子
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"view_cnt": {
"gt": 30,
"lt": 60
}
}
}
}
}
}1.5.3 搜索发帖日期在最近1个月的帖子
POST /forum/_bulk
{"index":{"_id":5}}
{"articleID":"DHJK-B-1395-#Ky5","userID":3,"hidden":false,"postDate":"2017-03-01","tag":["elasticsearch"],"tag_cnt":1,"view_cnt":10}GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"postDate": {
"gt": "2017-03-10||-30d"
}
}
}
}
}
}二 ES 全文检索(分词检索)
2.1 实战 控制全文检索的精准度
2.1.1 准备数据
POST /forum/_bulk
{"update":{"_id":"1"}}
{"doc":{"title":"this is java and elasticsearch blog"}}
{"update":{"_id":"2"}}
{"doc":{"title":"this is java blog"}}
{"update":{"_id":"3"}}
{"doc":{"title":"this is elasticsearch blog"}}
{"update":{"_id":"4"}}
{"doc":{"title":"this is java, elasticsearch, hadoop blog"}}
{"update":{"_id":"5"}}
{"doc":{"title":"this is spark blog"}}2.1.2 match query 不控制精度
GET /forum/_search
{
"query": {
"match": {
"title": "java elasticsearch"
}
}
}2.1.3 match query 控制精度(operator=and)
GET /forum/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch",
"operator": "and"
}
}
}
}2.1.4 match query 控制精度(minimum_should_match=xxx)
GET /forum/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch spark hadoop",
"minimum_should_match": "75%"
}
}
}
}2.1.5 match query 控制精度(bool多个条件)
GET /forum/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": "java"
}
},
"must_not": {
"match": {
"title": "spark"
}
},
"should": [
{
"match": {
"title": "hadoop"
}
},
{
"match": {
"title": "elasticsearch"
}
}
]
}
}
}2.1.6 match query 控制精度(bool多个条件+minimum_should_match)
GET /forum/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "java"
}
},
{
"match": {
"title": "elasticsearch"
}
},
{
"match": {
"title": "hadoop"
}
},
{
"match": {
"title": "spark"
}
}
],
"minimum_should_match": 3
}
}
}2.1.7 了解多个搜索条件如何计算relevance score
2.2 了解 match query如何转换为term+should
2.2.1 match query 如何转化 term+should
//from
{
"match": { "title": "java elasticsearch"}
}
//to
{
"bool": {
"should": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }}
]
}
}2.2.2 and match如何转换为term+must
//from
{
"match": {
"title": {
"query": "java elasticsearch",
"operator": "and"
}
}
}
//to
{
"bool": {
"must": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }}
]
}
}2.2.3 minimum_should_match如何转换
//from
{
"match": {
"title": {
"query": "java elasticsearch hadoop spark",
"minimum_should_match": "75%"
}
}
}
//to
{
"bool": {
"should": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }},
{ "term": { "title": "hadoop" }},
{ "term": { "title": "spark" }}
],
"minimum_should_match": 3
}
}三 ES搜索relevance score处理
3.1 实战 boost(权重)影响 relevance score
GET /forum/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "blog"
}
}
],
"should": [
{
"match": {
"title": {
"query": "java"
}
}
},
{
"match": {
"title": {
"query": "hadoop"
}
}
},
{
"match": {
"title": {
"query": "elasticsearch"
}
}
},
{
"match": {
"title": {
"query": "spark",
"boost": 5
}
}
}
]
}
}
}3.2 原理 多shard场景下relevance score不准确问题
3.2.1 造成relevance score不准确问题原因

3.2.2 如何解决relevance score不准确问题
3.3 实战 多字段搜索 影响 relevance score
3.3.1 准备实验数据
POST /forum/_bulk
{"update":{"_id":"1"}}
{"doc":{"content":"i like to write best elasticsearch article"}}
{"update":{"_id":"2"}}
{"doc":{"content":"i think java is the best programming language"}}
{"update":{"_id":"3"}}
{"doc":{"content":"i am only an elasticsearch beginner"}}
{"update":{"_id":"4"}}
{"doc":{"content":"elasticsearch and hadoop are all very good solution, i am a beginner"}}
{"update":{"_id":"5"}}
{"doc":{"content":"spark is best big data solution based on scala ,an programming language similar to java"}}3.3.2 multi-field搜索默认relevance score
GET /forum/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "java solution"
}
},
{
"match": {
"content": "java solution"
}
}
]
}
}
}3.3.3 best fields(dis_max)影响relevance score
GET /forum/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}3.3.4 tie_breake(系数)relevance score
GET /forum/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": "java beginner"
}
},
{
"match": {
"content": "java beginner"
}
}
]
}
}
}
GET /forum/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": "java beginner"
}
},
{
"match": {
"content": "java beginner"
}
}
],
"tie_breaker": 0.3
}
}
}
3.3.5 multi_match(best_fields+boost)影响relevance score
GET /forum/_search
{
"query": {
"multi_match": {
"query": "java solution",
"type": "best_fields",
"fields": [
"title^2",
"content"
],
"tie_breaker": 0.3,
"minimum_should_match": "50%"
}
}
}GET /forum/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": {
"query": "java beginner",
"minimum_should_match": "50%",
"boost": 2
}
}
},
{
"match": {
"content": {
"query": "java beginner",
"minimum_should_match": "30%"
}
}
}
],
"tie_breaker": 0.3
}
}
}3.3.6 multi_match(most fiels)影响relevance score
POST /forum/_mapping
{
"properties": {
"sub_title": {
"type": "text",
"analyzer": "english",
"fields": {
"std": {
"type": "text",
"analyzer": "standard"
}
}
}
}
}POST /forum/_bulk
{"update":{"_id":"1"}}
{"doc":{"sub_title":"learning more courses"}}
{"update":{"_id":"2"}}
{"doc":{"sub_title":"learned a lot of course"}}
{"update":{"_id":"3"}}
{"doc":{"sub_title":"we have a lot of fun"}}
{"update":{"_id":"4"}}
{"doc":{"sub_title":"both of them are good"}}
{"update":{"_id":"5"}}
{"doc":{"sub_title":"haha, hello world"}}GET /forum/_search
{
"query": {
"match": {
"sub_title": "learned course"
}
}
}GET /forum/_search
{
"query": {
"multi_match": {
"query": "learned mores courses",
"type": "most_fields",
"fields": [ "sub_title", "sub_title.std" ]
}
}
}四 ES cross-fields搜索
4.1 实战体验 most_fields+cross-fields
4.1.1 初始化数据
POST /forum/_bulk
{"update":{"_id":"1"}}
{"doc":{"author_first_name":"Peter","author_last_name":"Smith"}}
{"update":{"_id":"2"}}
{"doc":{"author_first_name":"Smith","author_last_name":"Williams"}}
{"update":{"_id":"3"}}
{"doc":{"author_first_name":"Jack","author_last_name":"Ma"}}
{"update":{"_id":"4"}}
{"doc":{"author_first_name":"Robbin","author_last_name":"Li"}}
{"update":{"_id":"5"}}
{"doc":{"author_first_name":"Tonny","author_last_name":"Peter Smith"}}4.1.2 执行most_fields+cross-fields搜索
GET /forum/_search
{
"query": {
"multi_match": {
"query": "Peter Smith",
"type": "most_fields",
"fields": [
"author_first_name",
"author_last_name"
]
}
}
}4.2 copy_to+cross-fields搜索
PUT /forum/_mapping/
{
"properties": {
"new_author_first_name": {
"type": "text",
"copy_to": "new_author_full_name"
},
"new_author_last_name": {
"type": "text",
"copy_to": "new_author_full_name"
},
"new_author_full_name": {
"type": "text"
}
}
}PUT /forum/_mapping/
{
"properties": {
"new_author_first_name": {
"type": "text",
"copy_to": "new_author_full_name"
},
"new_author_last_name": {
"type": "text",
"copy_to": "new_author_full_name"
},
"new_author_full_name": {
"type": "text"
}
}
}
GET /forum/_search
{
"query": {
"match": {
"new_author_full_name": "Peter Smith"
}
}
}4.3 原生cross-fiels搜索
GET /forum/_search
{
"query": {
"multi_match": {
"query": "Peter Smith",
"type": "cross_fields",
"operator": "and",
"fields": [
"author_first_name",
"author_last_name"
]
}
}
}五 ES搜索匹配
5.1 近似匹配基本概念
5.2 phrase matching 短语匹配
POST /forum/_update/5
{
"doc": {
"content": "spark is best big data solution based on scala ,an programming language similar to java spark"
}
}GET /forum/_search
{
"query": {
"match_phrase": {
"content": "java spark"
}
}
}5.3 phrase matching 近似匹配slop
GET /forum/_search
{
"query": {
"match_phrase": {
"title": {
"query": "java blog",
"slop": 2
}
}
}
}5.4(match+match_phrase)query实现召回率与精准度的平衡
GET /forum/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": {
"query": "java blog"
}
}
},
"should": {
"match_phrase": {
"title": {
"query": "java blog",
"slop": 50
}
}
}
}
}
}5.5 rescoring(重打分) 近似匹配机制
GET /forum/_search
{
"query": {
"match": {
"content": "java spark"
}
},
"rescore": {
"window_size": 50,
"query": {
"rescore_query": {
"match_phrase": {
"content": {
"query": "java spark",
"slop": 50
}
}
}
}
}
}5.6 前缀 通配符 正则 匹配搜索
5.6.1 前缀搜索
PUT hzm_index
{
"mappings": {
"properties": {
"title": {
"type": "keyword"
}
}
}
}
POST /hzm_index/_bulk
{"index":{"_id":1}}
{"title":"C3D0-KD345"}
{"index":{"_id":2}}
{"title":"C3K5-DFG65"}
{"index":{"_id":3}}
{"title":"C4I8-UI365"}GET hzm_index/_search
{
"query": {
"prefix": {
"title": {
"value": "C3"
}
}
}
}
c4
5.6.2 通配符搜索
GET hzm_index/_search
{
"query": {
"wildcard": {
"title": {
"value": "C?K*5"
}
}
}
}5.6.3 正则搜索
GET hzm_index/_search
{
"query": {
"regexp": {
"title": "C[0-9].+"
}
}
}六 ES 搜索推荐&fuzzy
6.1 match_phrase_prefix实现search-time搜索推荐
GET forum/_search
{
"query": {
"match_phrase_prefix": {
"title": "java b"
}
}
}6.2 原理 ngram和index-time搜索推荐
6.2.1 准备数据
DELETE /hzm_index
PUT /hzm_index
{
"settings": {
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"autocomplete": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
}
}
PUT /hzm_index/_mapping
{
"properties": {
"title": {
"type": "text",
"analyzer": "autocomplete",
"search_analyzer": "standard"
}
}
}
POST /hzm_index/_bulk
{"index":{"_id":1}}
{"title":"hello world"}
{"index":{"_id":2}}
{"title":"hello win"}
{"index":{"_id":3}}
{"title":"hello dog"}
GET /hzm_index/_search
{
"query": {
"match_phrase": {
"title": "hello w"
}
}
}
6.3 实战错误拼写时的fuzzy模糊搜索技术
POST /hzm_index/_bulk
{"index":{"_id":1}}
{"text":"Surprise me!"}
{"index":{"_id":2}}
{"text":"That was surprising."}
{"index":{"_id":3}}
{"text":"I wasn't surprised."}
GET /hzm_index/_search
{
"query": {
"fuzzy": {
"text": {
"value": "surprize",
"fuzziness": 2
}
}
}
}GET /hzm_index/_search
{
"query": {
"fuzzy": {
"text": {
"value": "surprize",
"fuzziness": 2
}
}
}
}七 ES 搜索内部原理
7.1 原理TF&IDF算法以及向量空间模型算法
7.1.1 vector space model
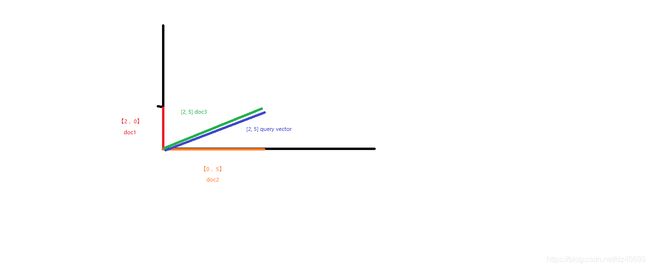
7.2 原理 lucene相关度分数算法
score(q,d) =
queryNorm(q)
//queryNorm = 1/√sumOfSquaredWeights
//sumOfSquaredWeights = 所有term的IDF分数之和,开一个平方根,然后做一个平方根分之1
//主要是为了将分数进行规范化 --> 开平方根,首先数据就变小了 --> 然后还用1去除以这个平方根,分数就会很小 --> 1.几 / 零点几
//分数就不会出现几万,几十万,那样的离谱的分数
//是用来让一个doc的分数处于一个合理的区间内,不要太离谱,举个例子,一个doc分数是10000,一个doc分数是0.1
· coord(q,d) //简单来说,匹配更多value的doc,进行一些分数上的成倍的奖励
//成倍的奖励分=(匹配每个值的分数相加)*匹配值的个数/query value的个数
· ∑ (
tf(t in d) //计算每一个term对doc的分数的时候,就是TF/IDF算法
· idf(t)2 //计算每一个term对doc的分数的时候,就是TF/IDF算法
· t.getBoost() //权重越大 分数变大
· norm(t,d) //field length 越长,分数越小
) (t in q)
//query中每个term对doc的分数,进行求和,多个term对一个doc的分数,组成一个vector space,然后计算吗,就在这一步7.3实战 相关度分数优化方法
7.3.1 query-time boost
score(q,d) =
queryNorm(q)
//queryNorm = 1/√sumOfSquaredWeights
//sumOfSquaredWeights = 所有term的IDF分数之和,开一个平方根,然后做一个平方根分之1
//主要是为了将分数进行规范化 --> 开平方根,首先数据就变小了 --> 然后还用1去除以这个平方根,分数就会很小 --> 1.几 / 零点几
//分数就不会出现几万,几十万,那样的离谱的分数
//是用来让一个doc的分数处于一个合理的区间内,不要太离谱,举个例子,一个doc分数是10000,一个doc分数是0.1
· coord(q,d) //简单来说,匹配更多value的doc,进行一些分数上的成倍的奖励
//成倍的奖励分=(匹配每个值的分数相加)*匹配值的个数/query value的个数
· ∑ (
tf(t in d) //计算每一个term对doc的分数的时候,就是TF/IDF算法
· idf(t)2 //计算每一个term对doc的分数的时候,就是TF/IDF算法
· t.getBoost() //权重越大 分数变大
· norm(t,d) //field length 越长,分数越小
) (t in q)
//query中每个term对doc的分数,进行求和,多个term对一个doc的分数,组成一个vector space,然后计算吗,就在这一步7.3.2 重构查询结构
GET /forum/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"content": "java"
}
},
{
"match": {
"content": "spark"
}
},
{
"bool": {
"should": [
{
"match": {
"content": "solution"
}
},
{
"match": {
"content": "beginner"
}
}
]
}
}
]
}
}
}7.3.3 negative boost
GET /forum/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"content": "java"
}
}
],
"must_not": [
{
"match": {
"content": "spark"
}
}
]
}
}
}GET /forum/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"content": "java"
}
},
"negative": {
"match": {
"content": "spark"
}
},
"negative_boost": 0.2
}
}
}7.3.4 constant_score
GET /forum/_search
{
"query": {
"bool": {
"should": [
{
"constant_score": {
"filter": {
"match": {
"title": "java"
}
}
}
},
{
"constant_score": {
"filter": {
"match": {
"title": "spark"
}
}
}
}
]
}
}
}7.4 实战用function_score自定义相关度分数算法
7.4.1 准备数据
POST /forum/_bulk
{"update":{"_id":"1"}}
{ "doc" : {"follower_num" : 5} }
{ "update": { "_id": "2"} }
{ "doc" : {"follower_num" : 10} }
{ "update": { "_id": "3"} }
{ "doc" : {"follower_num" : 25} }
{ "update": { "_id": "4"} }
{ "doc" : {"follower_num" : 3} }
{ "update": { "_id": "5"} }
{ "doc" : {"follower_num" : 60} }GET /forum/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "java spark",
"fields": [
"tile",
"content"
]
}
},
"field_value_factor": {
"field": "follower_num",
"modifier": "log1p",
"factor": 0.5
},
"boost_mode": "sum",
"max_boost": 2
}
}
}
八 IK 分词器
8.1 docker 安装IK分词器
docker exec -it a515f73f2115 /bin/bash
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.7.0/elasticsearch-analysis-ik-7.7.0.zip8.2 物理机安装IK分词
8.3 IK 基础使用
8.3.1 准备数据
DELETE hzm_index
PUT /hzm_index
{
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
POST /hzm_index/_bulk
{"index":{"_id":"1"}}
{"text":"男子偷上万元发红包求交女友 被抓获时仍然单身"}
{"index":{"_id":"2"}}
{"text":"16岁少女为结婚“变”22岁 7年后想离婚被法院拒绝"}
{"index":{"_id":"3"}}
{"text":"深圳女孩骑车逆行撞奔驰 遭索赔被吓哭(图)"}
{"index":{"_id":"4"}}
{"text":"女人对护肤品比对男票好?网友神怼"}
{"index":{"_id":"5"}}
{"text":"为什么国内的街道招牌用的都是红黄配?"}8.3.2 搜索测试
GET /hzm_index/_analyze
{
"text": "男子偷上万元发红包求交女友 被抓获时仍然单身",
"analyzer": "ik_max_word"
}GET /hzm_index/_search
{
"query": {
"match": {
"text": "16岁少女结婚好还是单身好?"
}
}
}8.4 实战 IK 配置文件 & 自定义词库
8.4.1 配置文件了解
8.4.2 自定义词库
8.5 Ik mysql 热更新分词(未完成后面调整)