Oracle执行计划分析及实际生产案例解析
一、SQL优化基础
1.Oracle数据库Where条件执行顺序:自下而上。
由于SQL优化起来比较复杂,并且还会受环境限制,ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。
二、查看执行计划
在SQL语句上,按F5,查看Oracle语句执行计划

或者:F8执行语句
explain plan for select COUNT(*) from taba A,tabb B where a.CITY =591 and B.CITY=591;
select * from table(dbms_xplan.display());
执行计划的常用列字段解释:
ID:个序号,但不是执行的先后顺序。执行的先后根据缩进来判断。
Operation: 当前操作的内容。
基数(Rows):Oracle估计的当前操作的返回结果集行数
字节(Bytes):执行该步骤后返回的字节数
耗费(COST)、CPU耗费:Oracle估计的该步骤的执行成本,用于说明SQL执行的代价,理论上越小越好(该值可能与实际有出入)
时间(Time):Oracle估计的当前操作所需的时间
执行顺序:先执行缩进多的(层次深的),如果层次相同,就从上往下执行。
三、案例解析
1.分区字段不明确,导致用不上分区,生产查询需要100s,优化后变成1s
drop table users;
create table users(
user_id VARCHAR2(15),
home_city number(3),
user_name VARCHAR2(50),
remark VARCHAR2(100),
create_time date
);
create index idx1_users on users(user_id);
create table balance(
);
drop table pay_record;
create table pay_record(
pay_id VARCHAR2(15),
home_city number(3),
out_user_id number(15),
in_user_id number(15),
amount number(10),
status number(1),
pay_time date,
create_time date
)
partition by range(home_city,pay_time)
(
partition pay_time_20210411 values less than (591,to_date('20210411','yyyyMMdd')),
partition pay_time_20210412 values less than (591,to_date('20210412','yyyyMMdd')),
partition pay_time_20210413 values less than (591,to_date('20210413','yyyyMMdd')),
partition pay_time_20210414 values less than (591,to_date('20210414','yyyyMMdd')),
partition pay_time_20210415 values less than (591,to_date('20210415','yyyyMMdd')),
partition pay_time_59220210411 values less than (592,to_date('20210411','yyyyMMdd')),
partition pay_time_59220210412 values less than (592,to_date('20210412','yyyyMMdd')),
partition pay_time_59220210413 values less than (592,to_date('20210413','yyyyMMdd')),
partition pay_time_59220210414 values less than (592,to_date('20210414','yyyyMMdd')),
partition pay_time_59220210415 values less than (592,to_date('20210415','yyyyMMdd'))
);users :索引user_id
pay_record: 分区home_city,pay_time
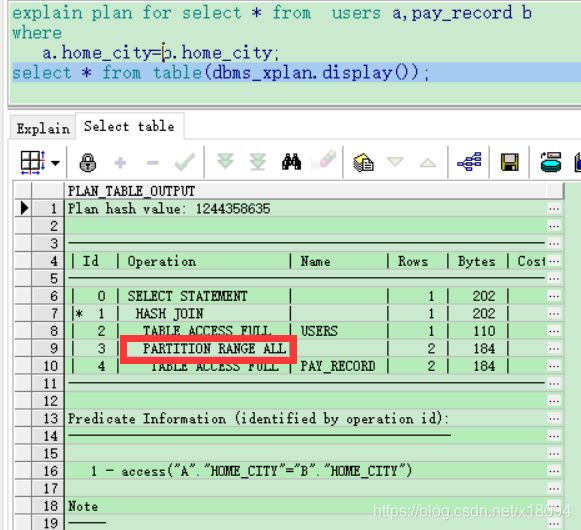
explain plan for select * from users a,pay_record b
where
a.home_city=b.home_city;
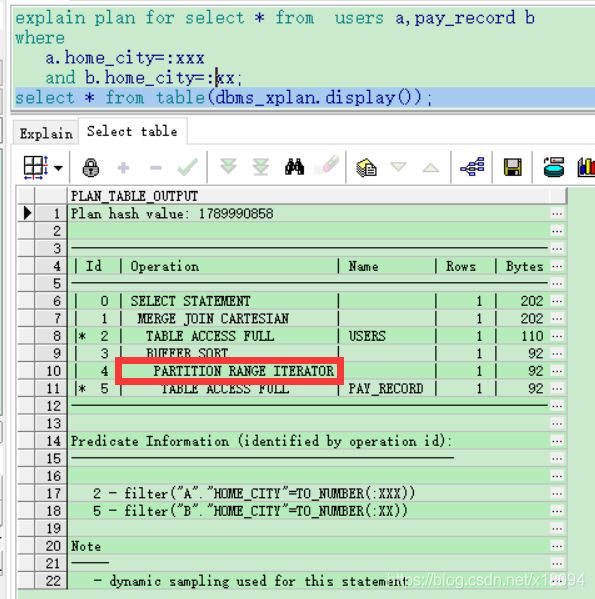
select * from table(dbms_xplan.display());这样的结果是 b表用不上分区,因为home_city不是确定的,无法落到具体的分区上。
此时查询执行计划,发现:
PARTITION RANGE ALL 相当于全表扫描
改成 a.home_city=:xxx and b.home_city=:xxx
PARTITION RANGE ITERATOR 用上分区了