c++函数指针
函数指针
- 一、函数指针基础知识
-
- 二、深入探讨函数指针
-
- 三、auto
- 四、使用typedef进行简化
- 五、指针和const
- 1.尽可能使用const
一、函数指针基础知识
完成函数指针需要的工作:
- 获取函数的地址。
- 声明一个函数指针。
- 使用函数指针来调用函数。
获取函数地址:只要使用函数名即可,如think()是一个函数,则think就是该函数的地址,要将函数作为参数进行传递,必须传递函数名。一定要区分传递的是函数的地址还是函数的返回值:
process(think);
thought(think());
//process()调用使得process()函数能够在其内部调用think()函数。
//though()调用首先调用think()函数,然后将think()得返回值传递给thought()函数。
声明函数指针:声明指向数据类型的指针时,必须指定指针指向的类型,声明指向函数的指针时,也必须指定指向的函数类型。如:
double pam(int);
则正确的指针类型声明如下:
double (*pf)(int);
与pam()声明类似,只是将pam替换为了(*pf)。由于pam是函数,因此,(*pf)也是函数。而如果(*pf)是函数,则pf就是函数指针。
为提供正确的运算符优先级,必须在声明中使用括号将*pf括起来。括号的优先级比星号的运算符高,因此*pf(int)意味着pf()是一个返回指针的函数,而(*pf)(int)意味着pf是一个指向函数的指针:
double (*pf)(int);//pf是一个指向函数的指针,所指函数的返回值类型为double
double *pf(int);//pf是函数名,此函数的返回值类型为double指针
//正确的声明pf后,便可以将相应函数的地址赋给它:
double pam(int);
double (*pf)(int);
pf=pam;
//注意,pam()的特征标和返回类型必须与pf相同。
指针来调用函数:(*pf)扮演的角色与函数名相同,因此使用(*pf)时,只需要将它看作函数即可:
double pam(int);
double (*pf)(int);
pf=pam;
double x= pam(4);
double y=(*pf)(5);
//c++也允许像使用函数名那样使用pf:
double y= pf(5);
实例:
#include
二、深入探讨函数指针
使用函数指针时面临挑战,下面一些函数的原型,他们的特征标和返回类型相同:
const double *f1(const double ar[],int n);
const double *f2(const double [],int n);
const double *f3(const double *,int);
这些函数的特征标看似不同,但实际上相同:
-
在函数原型中,参数列表
const double ar [ ]与const double * ar的含义完全相同。 -
在函数原型中,可以省略标识符。因此,
const double ar []可简化为const double [ ], 而const double * ar可简化为const double*。 -
另一方面,函数定义必须提供标识符,因此需要使用
constdouble ar [ ]或const double * ar。
声明一个指针,它可以指向三个函数之一。假定该指针名为p1,则只需将目标函数原型中的函数名替换为(*p1):
const double * (*p1)(const double *,int);
//可在声明的同时进行初始化:
const double * (*p1)(const double *,int)=f1;
//可使用C++11的自动类型推断:
auto p2 = f2;
实例:
cout<<(*p1)(av,3)<<":"<<*(*p1)(av,3)<<endl;
cout<<p2(av,3)<<":"<<*p2(av,3)<<endl;
-
根据前面介绍的知识可知,
(*p1) (av, 3)和p2(av, 3)都调用指向的函数(这里为f1()和f2())并将av和作为参数。 -
因此,显示的是这两个函数的返回值。返回值的类型为
const double*(即double值的地址),因此在每条cout语句中,前半部分显示的都是要将运算符*应用于这些地址,如表达式*(*p 1)(av,3)和*p2(av,3)所示。
若需要使用三个函数,如果有一个函数指针数组将很方便。这样可使用for循环通过指针依次调用每个函数,声明如下:
const double * (*pa[3])(const double *,int)={f1,f2,f3};
//pa是一个包含三个元素的数组,而声明这样的数组,首先需要使用pa[3]。
-
运算符
[]的优先级高于*,因此*pa[3]表明pa是一个包含三个指针的数组。 -
特征标:
const double *,int,且返回类型为:const double *的函数,pa是一个包含三个指针的数组。 -
其中每个指针都指向这样的函数,即将
const double*和int作为参数。并返回一个const double *。
这里不能使用auto,自动类型推断只能用于单值初始化,而不能用于初始化列表,但声明数组pa后,声明同样类型的数组就很简单了:
auto pb = pa;//数组名是指向第一个元素的指针,因此pa和pb都是指向函数指针的指针。
//使用pb和pa调用函数,pa[i]和pb[i]都表示数组中的指针,因此可将任何一种函数调用表示法用于它们:
const double * px = pa[0](av,3);
const double * py = (*pb[1])(av,3);
//获得指向的double值,可以使用运算符*:
double x = *pa[0](av,3);
double y = *(*pb[1])(av,3);
可做的另 一 件事是创建指向整个数组的指针。由于数组名 pa 是指向函数指针的指针,因此指向数组的指针将是这样的指针,即它指向指针的指针。这听起来令人恐怖,但由于可使用单个值对其进行初始化,因此可使用auto:
auto pc = &pa;
若自己声明,这种声明应类似于pa的声明,但由于增加了一层间接,因此需要在某个地方添加 一 个*。
具体地说,若这个指针名为 pd, 则需要指出它是 一 个指针,而不是数组。意味着声明的核心部分应为(*pd)[3],其中的括号让标识符pd与*先结合:
*pd[3] //3个指针数组
(*pd)[3] //指向包含3个元素的数组的指针
//pd是个指针,指向一个包含三个元素的数组,这些元素是什么?由pa的声明的其他部分描述,结果如下:
const double *(*(*pd)[3])(const double *,int) = &pa;
-
既然
pd指向数组,那么*pd就是数组,而(*pd)[i]是数组中的元素,即函数指针。 -
较简单的函数调用是
(*pd)[i](av,3),而*(*pd)[i](av,3)是返回的指针指向的值。 -
可以使用第二种使用指针调用函数的语法:使用
(*(*pd)[i])(av,3)来调用函数,而*(*(*pd)[i])(av,3)是指向的double值。
请注意pa(它是数组名,表示地址)和&pa之间的差别:
-
在大多数情况下, pa都是数组第一个元素的地址,即
&pa[0]。因此,它是单个指针的地址。但&pa是整个数组(即三个指针块)的地址。 -
从数字上说,
pa和&pa的值相同,但它们的类型不同。一种差别是,pa+1为数组中下一个元素的地址,而&pa+1为数组pa后面一个12字节内存块的地址(这里假定地址为4字节)。 -
另一个差别是,要得到第一个元素的值,只需对pa解除一次引用,但需要对&pa解除两次引用:
**&pa == *pa ==pa[0]
实例:
#include 
三、auto
C++11的目标之 一 是让 C++更容易使用,从而让程序员将主要精力放在设计而不是细节上。例:
auto pc= &pa; // C++11 自动类型推导
const double *(*(*pd) [3])(const double*, int)= &pa; // C++98, 手动
-
自动类型推断功能表明,编译器的角色发生了改变。
-
在C++98中,编译器利用其知识帮助您发现错误,而在C++11中,编译器利用其知识帮助您进行正确的声明。
存在一个潜在的缺点。自动类型推断确保变量的类型与赋给它的初值的类型 一 致,但您提供的初值的类型可能不对:
auto pc = *pa; //使用*pa代替&pa
上述声明导致pc的类型与*pa 一 致,在上面程序中,后面使用它时假定其类型与&pa 相同,这将导致编译错误。
四、使用typedef进行简化
除了auto外,C++还提供了其他简化声明的工具,关键字typedef:
typedef const real;
//可以将typedef当做标识符进行声明,并在开头使用关键字typedef。
typedef int(*fn)(int x);//fn为现在类型名
实例:
#include
五、指针和const
将cosnt用于指针,可以用两种不同的方式将const关键字用于指针。
- 第一种:让指针指向一个常量对象,可防止使用该指针来修改所指向的值。
- 第二种:将指针本身声明为常量,防止改变指针指向的位置。
int age= 39;
const int * pt = &age;
//该声明表示,pt指向一个const int ,因此不能使用pt来修改这个值。换句话说,*pt的值为const,不能被修改:
*pt+=1;//无效,pt指向个const int
cin>>*pt;//无效,原因相同
//上面存在个问题。pt的声明并不意味着它指向的值实际上就是个常量,而只是意味着对pt而言,这个值为常量。
//pt指向age,而age不是const。可以直接通过age来修改age的值,但不能使用pt指针来修改它:
*pt = 20;//无效,pt指向个常量int
age = 20;//有效,age没有声明为常量
以前将常规变量的地址赋给常规指针,而这里将常规变量的地址赋给指向cosnt的指针,因此有两种可能:
- 将const变量的地址赋给指向const的指针。
- 将const的地址赋给常规指针。
//这两种操作都可行吗?第一种可以,第二种不可以:
const float g_earch = 9.80;
const float * pe = &g_earth;
const float g_moon=1.63;
float * pm = &g_moon;
-
第一种,既不能使用g_earch来修改值9.80,也不能使用pe来修改。
-
C++禁用第二种原因:如果将g_moon的地址赋给pm,则可以使用pm来修改g_moon的值,这使得g_moon的const状态很荒谬,因此c++禁止将const的地址赋给非const指针。
-
非要这样做,可以使用强制类型转换。
若将指针指向指针,则情况将更复杂。假如涉及到一级间接关系,则将非cosnt指针赋给const指针是可以的:
int age = 39;//age++有效
int * pd = &age;//*pd=41有效
const int * pt = pd;//*pt=42无效
然而,进入二级间接关系,与一级间接关系一样将const和非const混合的指针赋值方式将不再安全。若允许这样做,则可以编写下面的代码:
const int **pp2;
int *p1;
const int n = 13;
pp2 = &p1;//不允许,假设可以
*pp2=&n;//有效,都是常量,DNA将p1设置n
*p1 = 10;//有效,但更改常量n
//上述代码将非const地址(&p1)赋给了const指针(pp2),因此可以使用p1来修改const数据。
//因此,仅当只有一层间接关系(如指针指向基本数据类型)时,才可以将非const地址或指针赋给const指针。
注:如果数据类型本身并不是指针,则可以将const数据或非const数据的地址赋给指向const的指针,但只能将非const数据的地址赋给非const指针。
假设有个由const数据组成的数组:
const int months[12]={31,28,31,30,31,30,31,31,30,31,30,31};
//则禁止将常量数组的地址赋给非常量指针将意味着不能将数组名作为参数传递给使用非常量形参的函数:
int sum(int arr[],int n);//应该是const int arr[]
int j = sum(months ,12);//不允许
//上述函数调用试图将const指针(months)赋给非const指针(arr),编译器将禁止这种函数调用。
1.尽可能使用const
将指针参数声明为指向常量数据的指针有两种理由:
-
可以避免由于无意间修改数据而导致的编程错误。
-
使用const使得函数能够处理const和非const实参,否则将只能接受非const数据。
-
如果条件允许,则应将指针形参声明为指向const的指针。
为说明另一个微妙之处,下面的声明:
int age =39;
const int * pt = &age;
//第二个声明中的const只能防止修改pt指向的值(39),而不能防止修改pt的值。也就是说,可以将一个新地址赋给pt:
int sage = 80;
pt = &sage;//可以指向另一个位置
//但任然不能使用pt来修改它指向的值80。
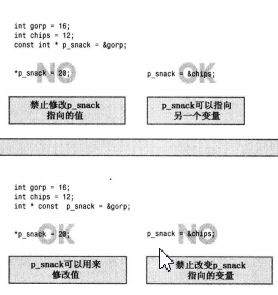
第二种使用const的方式使得无法修改指针的值:
int sloth = 3;
const int * ps = &sloth;//指向const int 指针
int * const finger = &sloth;//指向int常量指针
在最后面一个声明中,关键字cosnt的位置与以前不同。这种声明格式使得finger只能指向sloth,但允许使用finger来修改sloth的值。
中间的声明不允许使用ps来修改sloth的值,但允许将ps指向另一个位置。简而言之,finger和*ps都是const,而*finger和ps不是。
还可以声明指向const对象的const指针:
double trouble = 2.0E30;
const double * const stick = &trouble;
//stick只能指向trouble,而stick不能用来修改trouble的值。简而言之,stick和*stick都是const。
//通常,将指针作为函数参数来传递时,可以使用指向const的指针来保护数据。例如:
void show_array(const double ar[], int n);
在声明中使用const意味着show_array()不能修改传递给它的数组中的值,只要只有一层间接关系,就可以使用这种技术。
例如,这里的数组元素是基本类型,但如果它们是指针或指向指针的指针,则不能使用const。