抢滩大模型,抢单公有云,Databricks和Snowflake用了哪些“阳谋”?
原创:谭婧
漫步云上,得数据PaaS者,得天下。
数据PaaS分三类:
数据库,数据分析,人工智能(AI)。
数据PaaS后来者居上,因为
第一,向IT专业开发人员提供传统编程环境的这类PaaS平台成熟且普及;第二,大模型创造惊喜,AI异军突起。
数据库按下不表。
数据PaaS其他两类关联度高,可以理解为一个大赛道。
这个赛道美国领先,不仅分工细,生态好,而且有两个很能打的巨头。
Databricks和Snowflake。
Databricks是一家Data+AI(数据+人工智能)公司,见长于存储、处理、分析PaaS,还未上市。根据上一轮融资,其估值已达到380亿美金。Databricks从Spark起家,做计算(处理)层面的东西,慢慢做到存储层面。
Snowflake是一家向着Data Cloud(数据云)方向前进的公司,做了传统品类数据仓库,也做了新品类AI平台。正想做成一站式,2020年上市,目前市值579.2亿美金(2023年8月1日)。
同时,它俩也是云原生数据平台公司。
互为竞品,狭路相逢。
且都抓住了云原生基础架构升级的红利。
要我说,两位带头大哥本质很像。
近几年,野心越来越大,做的事情也越来越全面。
你看Snowflake,一边说着心里话:
“A data cloud on top of cloud.”
一边大步向前,想把云上数据仓库SaaS的易用性和性能费用比做到极致。
我想,只要做到了Snowflake的那句心里话,无论在多大的云厂商面前,都泰山崩而色不改,底气十足。
凭什么说两位带头大哥很能打?
他们抢滩大模型,抢单公有云。
前者时兴,后者是长久积累,所以,后者内容有点长,5063个字。
既然Databricks和Snowflake抢单公有云,那为什么和三朵公(AWS、微软、谷歌)又多少有些战略合作?
在文章的最后,谈谈我的理解。
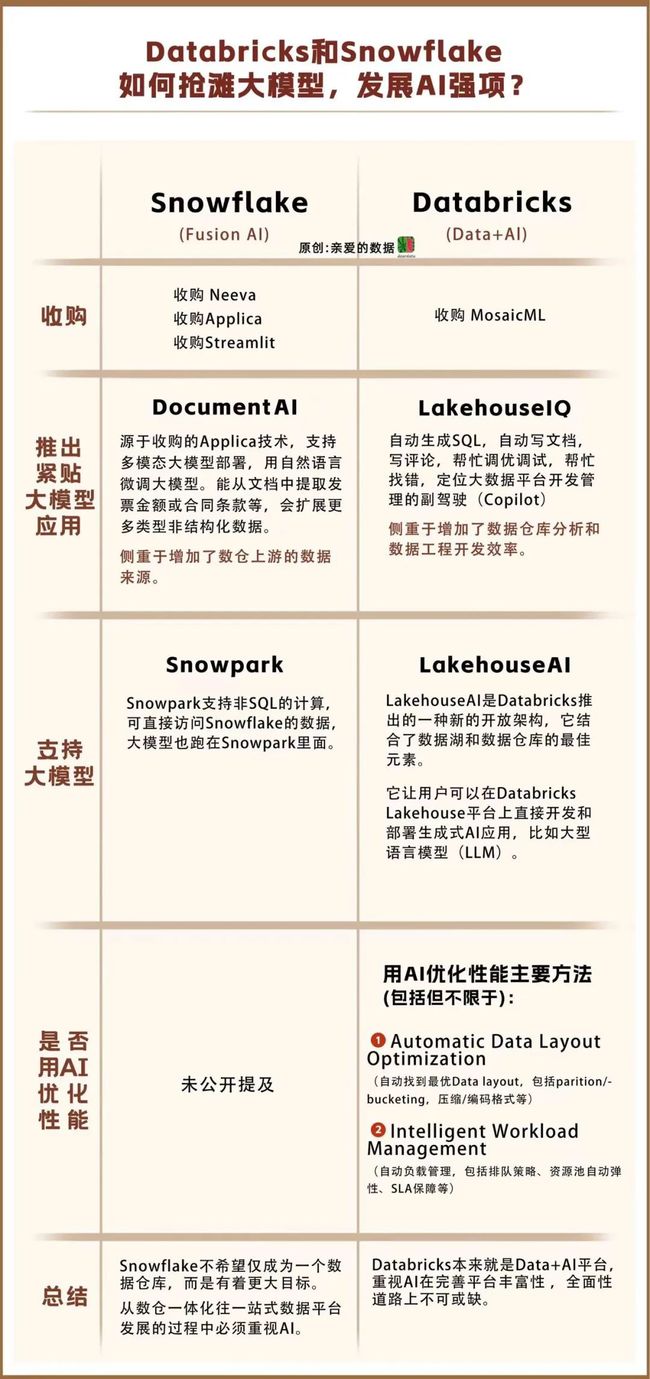
一. 抢滩大模型
废话不说,细节见表:
二. 抢单公有云
我先总结一笔当下云原生数据平台的两个趋势性重点:
第一,湖仓兴起
把数据从一个地方拷贝到另一个地方,在权限和安全都管理好的前提下,这件事一开始只是一个技术问题,数据工程师会说:我只想用一套系统管理数据,不要多套割裂的系统, 不要造成数据竖井(Data silo)。
后来,加入商业和决策,事情变复杂了。
把复杂变得简单,是一个商机。
未来,不要分裂的系统,分裂的架构,只要“统一”。
现在还没有一个东西(产品),100%地支持统一,这就是机会。
“统一”是一个好词,请大家留意,后面还会频繁出现(点题)。
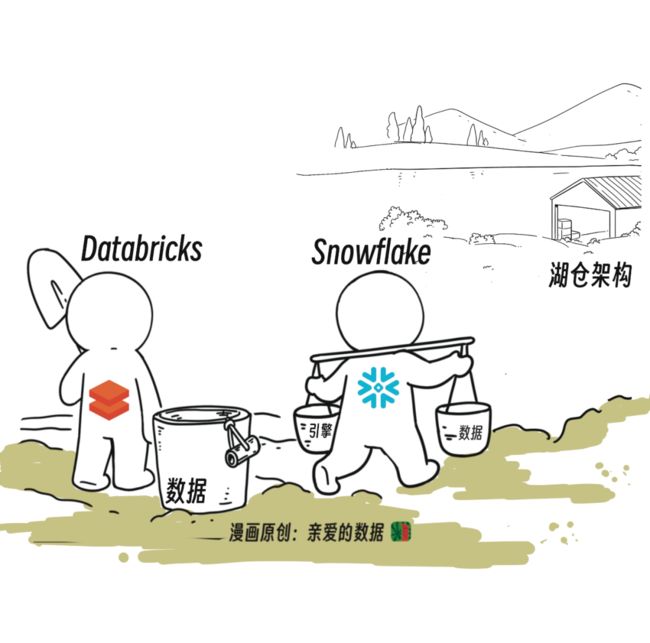
将数据湖、数据仓库、湖仓看成三个架构,
有关架构的三家之争,业界已有定论,湖仓胜出。
但是,还不能说全面胜利,胜利的战场是实时处理、机器学习、数据科学等非传统BI类数据应用场景)。
不过,所有人都会向湖仓前进,只是道路崎岖不同,山水险阻有异。
有趣的是,Snowflake常常“影帝”附体,避而不谈湖仓。
嘴上不谈,身体却很诚实。
因为“湖仓”是Databricks的营销术语。
小结一句:
Databricks从湖(数据湖)出发,Snowflake从仓(数据仓库)出发,双方都努力把湖仓(一体化系统)打造成一个完整产品,取代纷乱局面(一堆产品的组合解决方案)。
第二,仓内实时
实时化是一个大课题。
毫无疑问,仓内实时化是目前数据平台上数据仓库产品的共同目标。
或者说,实时化能带来明确的业务价值,一直是平台服务商追求的目标。
既往平台很难兼顾性能、成本、新鲜度(Freshness),才有流计算引擎横空出世。
从离线到实时,用一个引擎统一来解决所有问题,淘汰掉多个引擎组装。这种对Kappa架构的追求,是业内各界人士的长期目标。
展开聊三个小故事。
第一个故事

“开源数据湖仓表格式”
这是一个“头号厂商,不是头号玩家”的故事。
猛一看,“表格式(format for tables)”是件小事,细看则不然。
表格式也叫文件组织管理的格式标准,它是流入湖仓所有数据的基础。
从整体上讲,这是战略级别的事情也不过分。
数据湖表格式是存储架构的组成部分,既然选择了开放式存储架构,那对表格式的选择就很关键。
如若世上只有一个统一的开源数据湖仓表格式就好了,可惜不是。
较早的是Apache Hudi(发音像“Hoody”,IT工程师必备帽衫),大约在2016年左右出现,Uber公司大数据团队主导开发。而Databricks的Delta Lake内部研发时间线也差不多。随后,Netflix公司开发开源的Apache Iceberg出头露面。
所以,表格式有三种:
Hudi,Delta Lake,Iceberg。
市场上,有两个巨头,三个开源表格式。
博弈至此,格外精彩。
送分(命)题来了,三个选项,怎么选?
Databricks内心OS:既要也要。
既推出自己最新的表格式Delta Lake 3.0,也接纳Iceberg和Hudi。
实际上,Databricks 一开始也没完全开源,可能面临来自Iceberg强大的竞争压力,只得开源。
开源后又被批评开得没诚意,终于有了3.0。
业界似乎形成了一致观点:这场开源更像一种商业决策。
Snowflake内心OS:当然不会选敌方标准。
永别了,Delta Lake。
剩下的只有Hudi和Iceberg。
正好Iceberg势头强,Delta Lake势头弱,选Iceberg,给Delta Lake下分。
在奔赴湖仓的路上,双巨头做出相同动作:“拥抱”表格式Iceberg。
虽然动作相同,但背后逻辑不同。
数据湖的本质是开放,Databricks从湖出发,“做事”须符合湖的开放性的一贯要求。
要我说,趋势是Databricks要从统一的元数据管理角度,把数据湖的开放性推到极致。
Snowflake则不同,开始玩的是封闭。
内心诉求是转型,从数据仓库向湖仓转型。
回忆从前,Snowflake数据仓库进入后就不能被别的引擎计算。
今非昔比,Snowflake通过支持Iceberg就可以和主流开放引擎对接,比如Spark、Trino等。
Snowflake从封闭走向“开放”。
行文至此,我不禁感慨,强者不畏变,而畏不变。
守旧的公司依然守旧,而Snowflake为了大踏步地向湖仓前进,一改旧貌,果断“开放”,彰显大境界。
我请教云器数据CTO关涛一个问题:
“Iceberg声势锐不可当,您认为背后的原因是什么?”
先用一句话概括他给的观点:“Iceberg在三者之中,更体现中立性,甚至可以说是一个完全中立的第三方标准。”
他展开说来:
“无论跟底层,还是上层结合,它只有一套格式。既不像Hudi,那么贴近Hive;也不像Delta贴近Spark。若是从技术角度,答案可以拆得更细,值得做出一套表格一条一条详细地对比优劣。总之,无论技术还是生态,都是Iceberg做得更好。”
业界观点一:
“选择一个第三方的表格式,跟谁(巨头厂商)都没有依附关系的表格式,这是一个标准性质产品的天然的选型逻辑。”
业界观点二:
“纵观Spark历史,各方面原因导致开源不彻底,使得大家用Spark就会担心被绑定。Spark看上去是开源生态,顶上的引擎是Databricks的,底下的format是Databricks的,中间这个层也是Databricks的,用到最后实际上被绑定了。”
业界观点三:
“现在看来,Iceberg发展得好与不好,这两个巨头左右不了。几年之前,Databricks就试图用自己的一张牌Delta Lake去跟Iceberg抗衡,结果落败了。好在用Databricks商业版的客户几乎100%会选择Delta table格式。
总之,在这个细分领域里,即使是双巨头,也不能左右社区生态。”
我斗胆评论一句,随着两大巨头均站队Iceberg,历时大概五年的“表格式标准”纷争,距离谜底揭开不远。Iceberg可能是最后赢家。
第二个故事
数据目录和DLT并肩作战“实时化”。
既然是并肩作战,就先讲数据目录,再讲DLT,以及它俩如何并肩作战。
诚然,数据目录这么老的一个产品也能开拓出新战场。
老产品的历史遗留问题多。
那些一早采购了数据目录的客户,也没用好。
当然,有些人更惨,连个“数据目录”都没有。
我们对数据目录的狭隘理解是,有什么数据资源,记录下来,好比账本。
这是从产品诞生以来就有的老思路。
而联合利华北亚区数据和AI负责人杨荟博士表示,
今时今日,它早已不止是“目录”,而是“能自动更新的资产账本” 。
数据目录自上个世纪九十年代出现以来,
一直是IT部门的暗藏“神器”,别人用不了。
姑且称之为第一代。
当历史的车轮前进到第二代,有人尝试把业务部门也纳入进 “数据目录用户名单”。
于是,把有强业务属性,且管理维护需大量业务领域知识的那些数据集的访问和所有权让渡给产生这些数据集的业务流程所对应的业务部门(如供应链,销售,市场,研发)。
好消息是用数据目录和对数据负责的人群在壮大。
这一代创新者也成功了,Collibra和Alation是典型代表。
但此时,数据目录仍是静止的。
要反映数据资产的变动依赖于用户的主动更新,而主动更新数据目录这个工作有个特点:“做对没奖,做错背锅,吃力不讨好”。
所以,很少有人真心维护,导致第二代数据目录仍然是“静态账本”。
敢问:一个静态的工具,怎么管理一个动态发展的事物?
淘汰是时间问题。
数据目录需要从“二代”走到“三代”。
先看看,客户的切肤之痛在哪里。
云器数据CTO关涛和我聊了一个段子:
一家大型企业,假如没有数据目录,那么有什么资产,有什么数据集,数据集有多少维度,
数据上游哪里来,数据下游哪里被消费,
统统不清楚。
只有数据集的原始创建者才会知根知底,而别人一概不知。
如此糟糕,我都忍不住笑出了声。
为了生动展示有多难受,再补两刀:


如何实现数据目录的动态自动更新?
第一,用一个目录把所有的数据工程开发、数据工程运维的工作一步步地全部“串联”起来。
第二,现有数据集的每一次更新或者是开发的时候衍生出的新数据集自动被记录。
Unity Catalog是Databricks的数据目录。
2023峰会上,我们能看到,Databricks Lakehouse Federation能将数据源连接到Unity Catalog,可以处理、查询和治理散落于各处的数据,按生产逻辑打通,形成一种新能力。
让我们起立,致以掌声。
另外,“打通”有个前提:在平台上操作,平台以外则不行。
这就是为什么我们非要一个统一的数据平台。
无平台,则无动态。
平台越是全链路,动态越能做得彻底。
理论上,所有的公有云厂商,如果有数据PaaS层的话,可做同样的事。
于是,第三代厂商还包括三朵云等厂商。
可惜,在座各位公有云厂商都没Databricks做得好。
Databricks Unity Catalog做到了支持Datasets、Models、Application的统一元数据管理。
于是,数据目录的上半场战事已近尾声。
可惜还顾不上高兴,下半场战事已在眼前。
AI大模型声势浩大,雷声滚滚。
转眼已是一等公民。
而AI强调“半”和“非”数据处理能力。
云器数据CTO关涛的观点是:
在过去几十年里,结构化数据相关技术一直是主流。
而今,半结构化和非结构化数据(下文简称“半”和“非”数据)已成为数据平台的焦点。
怎么去管好“半”和“非”数据成为当前重点,而且技术难度比管理结构化数据大很多(数据没有被Schematize)。
对此,Databricks不仅有所准备,还利用大企业在市占率上的优势,竭尽全力想把它的产品往事实标准上推。
第二个故事看似结束了,实则没有,它给第三个故事开了个头。
因为仅靠数据目录不够,要和Delta Live Tables(DLT)并肩作战。
第三个故事
拆掉Lambda。
我们看到,两位带头大哥已经在“亲身示范”。
先向我们走来的是Snowflake,气定神凝:
实时全链路,Snowpipe Streaming+Dynamic Table能做到1分钟级别实时刷新链路。
再向我们挥手的是Databricks,意气轩昂:
在过去一年,DLT强劲增长177%,有54% 的客户使用。
177%意味着什么?
这个数字是Databricks平台产品平均增长率的3倍多。
它意味着,数据仓库实时化对Databricks的客户已是常态(国内则不然,请另行理解)。
首先,细看如何Databricks用DLT做数据仓库实时?
Databricks的一句话答案是,用DLT统一,做到全链路实时化。
就此,杨荟博士谈道:
“Dremio比Databricks更早做出和DLT同类功能,叫做Virtual Data Sets(VDS),我在2021年就开始使用VDS。但是,国内公有云上的Databricks版本的产品至今还没有上线这个功能,所以,国内知道和使用DLT的人少。”
那么问题来了,DLT这么好,价值如何体现?
在DLT问世之前,数据工程师的工作,每一步数据处理都要保存下来,这个规定动作就是“存盘”。
比如,跨表查询,交叉索引,JOIN之后的数据,包括原始数据,脏数据清理后的数据;
再有,一些月度、年度汇总数据。
总之,数据处理的每个“阶段”(Stage)会“产生”一些新的数据集。
过去的做法是每一个步骤都把中间结果(数据)保存下来,以方便接下来用。
这个过程中,物理存储避免不了。
而DLT带来一种新玩法。
DLT把中间的那些“步骤过程数据(集)”虚拟化,
代码还是一样写,数据集还是一样创建。
但是,并不物理存盘,而是操作于一个虚拟数据集上。
表面上一切都没有改变。
但是,DLT降低了在数据处理中存储的时间成本。
一旦虚拟化之后,数据集就不用步步存盘。
以前,共享物理数据集,
需把这个数据集所在的文件和它的元数据所对应的文件等等,全部分享。
而虚拟化的数据集被视为数据平台当中的一个数据对象。
不仅如此,一个数据集能被多个项目和团队同时开发。
当数据管线(Pipeline)分成AB两道管线。
每个管线各有十步,前五步一样。
在有DLT的情况下,B管线可接着A管线中间结果(第六步)继续工作,
无需从头开始。

这就好比,超级开卷考试。
每个人的试卷题目,既有相同又有不同。
DLT能让所有同学无缝互助(作弊),学渣解题解了几步不会了,学霸接着做。
最后,全班同学都满分。
Live Table是什么?
“表(Table)”的概念已经在数据库里存在几十年了。
何苦要在“表”上造新词。
Databricks推这个概念,是想“改写”静态表的历史。
DLT有两层含义:
第一,虚拟数据集。
第二,动态数据流。
确切表达是:
一个流式(Streaming table)动态更新的虚拟数据集(Materialized view)。
这里并不是和英文一一对应翻译,经过与审稿专家的讨论,此种翻译,最为妥帖。
DLT本质是流计算,而流计算又是实现实时数据仓库的手段。
所以,Databricks想用DLT来替代流式计算,从而做到实时。
这是Kappa架构的做法。
从某种程度上讲,Databricks放弃了基于Spark streaming构建独立实时数据仓库的方案。
从Lambda 到理想化的Kappa是数据厂商集体转型的大方向。
不止是带头大哥们在以重磅之力推动以一体化的方式做到实时。
技术趋势已经明确,未来会有很多优秀企业往这个方向突破。
旧式组装的特点是已有离线引擎,需要做数据新鲜度的时候,再加一个流式引擎。
这俩引擎分别独立。
多系统各自独立需要分别管理,且需要很多数据同步,开发维护成本很高;
还带来了一系列问题,比如元数据、数据存储不统一;
未来,组装法被淘汰,一体化来解决。
经此一役,那些和Databricks 有直接竞争的厂商,以及三朵云同类产品也包括在内,需集体面对“尴尬”。
AWS:被动了。
微软云:俺也一样。
谷歌云:俺也一样
第三个故事是一个拆掉Lambda,建设理想中的Kappa的故事。
回到文章最开头预留问题。
为什么Databricks和Snowflake产品和微软云数据PaaS产品是竞品,还战略合作?
讲一个段(真)子(事)。
某甲方客户数字化水平较高,三朵云均有使用。
有一天,微软云上的Datebricks产品在使用的时候出现了bug。
那么问题来了,你猜哪个团队会第一时间响应?
是微软云,还是Datebricks团队。
答案是,微软云第一时间响应,且解决。
也就是说,即使Datebricks和Snowflake在三朵云上的数据PaaS生意做得再大,钱也有一部分进了云厂商口袋,因为计算资源是三朵云的。
如果云厂商占大头,那积极性更高。
公有云是一棵大树,生态越茂盛对它的发展越好,这是公有云商业模式决定的。
Databricks和Snowflake产品的竞品是三朵云数据和AI平台产品,而不是公有云本身。难受的只有三朵云的数据和AI平台部门,以及他们肩膀上的KPI。
我认为,在数据PaaS这个赛道,Databricks和Snowflake赢过了三朵云。

One more thing

补充介绍一下参与讨论的两位大神,
他们分别代表了市场上两种不同的角色:建造者和用户。关涛是新朋友,他曾是前阿里云最年轻的P10,16年数据平台/分布式系统从业经验。杨荟博士是老朋友,十年数据平台架构设计和使用经验,他所发表观点仅代表个人对云上数据平台行业的观察,与目前就职公司无关。他以往的观点已经收录至我的新书:
《人工智能基建革命:我看见了风暴》

 更多阅读
更多阅读
1. 深聊京东科技何晓冬丨一场九年前的“出发”:奠基多模态,逐鹿大模型
2. 深聊王金桥丨紫东太初:造一个国产大模型,需用多少篇高质量论文?
3. 老店迎新客:向量数据库选型与押注中,没人告诉你的那些事
4. 大模型“搅局”,数据湖,数据仓库,湖仓选型会先淘汰谁?
