【习题之Python篇】习题12(数据分析)
所用到的数据【学习笔记之Python篇】习题12(数据分析)
开始的开始我们需要引入我们所需要的库
import numpy as np
from pandas import DataFrame,Series
import pandas as pd
import os #标准库
from pandas import to_datetime #日期处理库
import matplotlib.pyplot as plt #可视化库
import matplotlib
1.一个一个的从外部读取数据并将其弄成一个表
s1= pd.read_excel("d://student1.xlsx",header=0)
s2= pd.read_excel("d://student2.xlsx",header=0)
df=pd.concat([s1,s2],ignore_index=True) #合并操作
小知识:
ignore_index的作用:对合并之后的表格重新排序
当ignore_index=False时
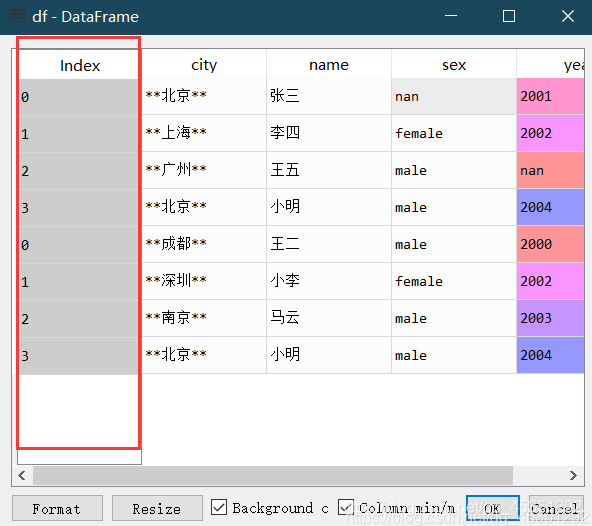
当ignore_index=True时
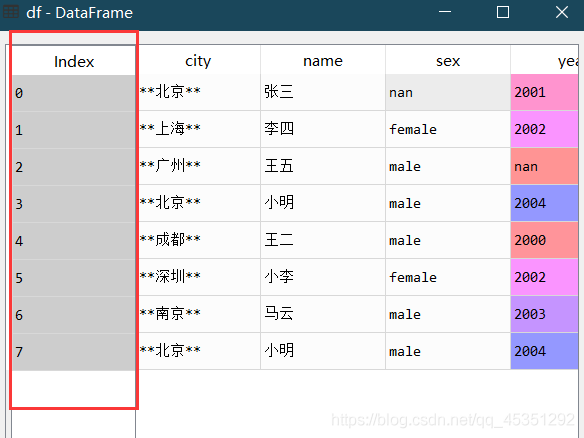
2.一次性读取多个同类型的数据
格式:

import pandas as pd
import os #标准库
file_dir = "d://data"
file_list = os.listdir(file_dir) #获取指定路径下的全部文件
for file in file_list:
df=pd.read_csv(os.path.join(file_dir,file),header=0,sep=",",dtype=str,engine="python",encoding='utf-8')
if file == file_list[0]: #判断是不是第一文件
all_data=df
else:
all_data=pd.concat([all_data,df],ignore_index=True)
小知识:
- os.path.join(file_dir,file) 连接文件
dtype=str将导入的数据改成字符串形式 engine=“python"更改引擎,默认engine为"c” , ,当文件中有中文字符串时进行这样操作encoding=‘utf-8’ 防止导进去的数据乱码。
3.数据清洗的常用操作
先读取数据
s1= pd.read_excel("d://student1.xlsx",header=0)
s2= pd.read_excel("d://student2.xlsx",header=0)
df=pd.concat([s1,s2],ignore_index=True) #合并操作
①缺失值删除(默认行向删除).dropna( )
s3=s1.dropna(1) #竖向删除

s3=s1.dropna(0) #行向删除

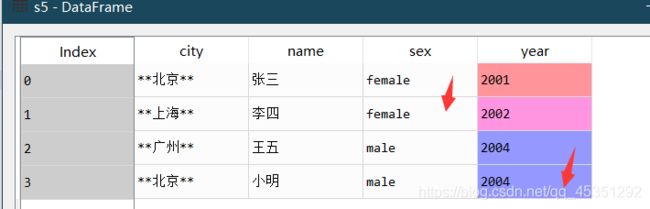
②缺失值填充 .fillna(method=‘填充的形式’)
s5=s1.fillna(method='bfill') #向下填充
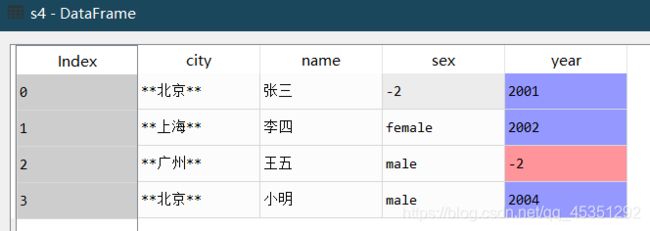
s4=s1.fillna(-2) #指定数据填充
s6=s1.fillna(method='pad') #向上填充
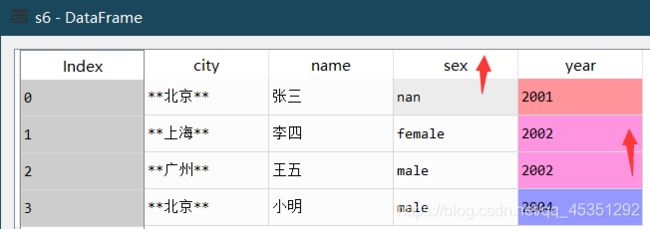
4.重复数据处理 .drop_duplicates( )
创建数据
s7=pd.concat([s1,s2],ignore_index=True)
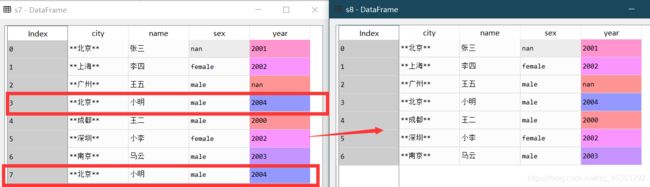
删除重复数据
删除重复项,除了第一次出现的不删除,其他重复的都删除
s8=s7.drop_duplicates() #删除重复数据记录,只保留一行
或
s8=s7.drop_duplicates(subset=None, keep='first')
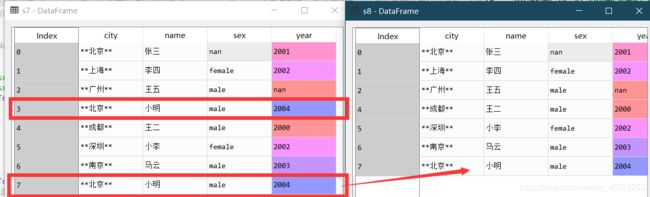
删除重复项,除了最后一次出现。
s8=s7.drop_duplicates(subset=None, keep='last')
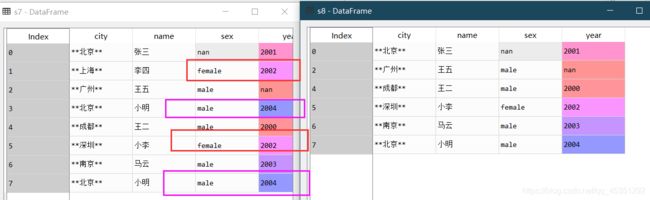
删除指定列标签中的重复项,除了最后一次出现。
s8=s7.drop_duplicates(subset=['sex','year'], keep='last')
小知识:
subset: 列标签,可选 (None表示考虑所有行)
keep: {‘first’, ‘last’, False}, 默认值 ‘first’
- first: 删除重复项,除了第一次出现的。
- last: 删除重复项,除了最后一次出现。
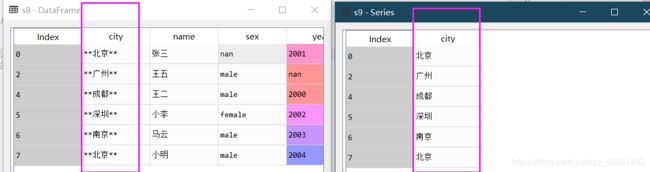
5.去除某些字符的指定字符 .strip( ‘删除的符号’ )
s9=s8["city"].str.strip('*') #一定将其转换成字符串,在用strip()
小知识:
strip() 删除指定字符
lstrip() 删除指定字符左部分
rstrip() 删除指定字符的右部分
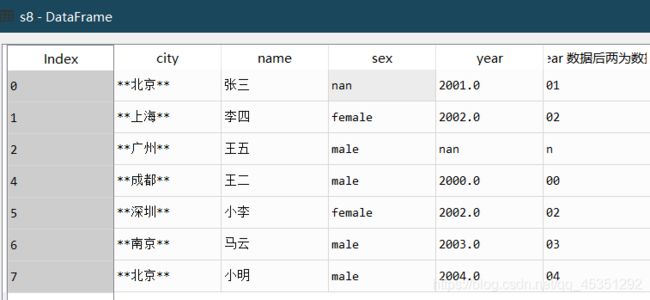
6.获取字段中的某个片段的值 .slice( 首区间 , 尾区间 )
得到 year 数据后两为数据
s8['year']=s8.year.astype(str) #更改为指定类型.astype(str)
s8['year 数据后两为数据']=s8['year'].str.slice(2,4)
注意:
如果你不这么操作就会报错,
s8['year']=s8.year.astype(str) #更改为指定类型.astype(str)

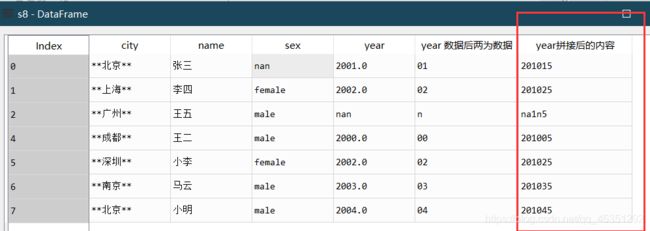
7.拼接操作
s8['year']=s8.year.astype(str) #更改为指定类型.astype(str)
s8['year拼接后的内容'] = s8.year.str.slice(0,2)+'1'+s8.year.str.slice(2,4)+'5' #从0开始数的在第二位和第三位后插入数字‘1’、‘5’
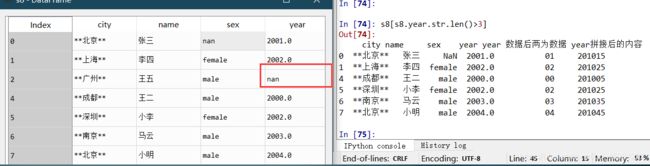
8.提取满足条件的行
找出city在北京的人
s8[s8.city=='**北京**']

找出year不为空的人
s8[s8.year.str.len()>3]
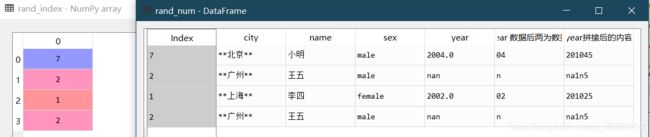
9.随机抽样
rand_index=np.random.randint(0,8,8//2) #定义随机的标号,范围及个数
s8.loc[rand_index] #找到随机的数据
10.连接表字段匹配 pd.merge(匹配的左表,匹配的右表 ,left_on=‘匹配的标签名’,right_on=‘匹配的标签名’)
创建表
df1=pd.read_excel("d://成绩表.xlsx", header=0)
df2=pd.read_excel("d://信息表.xlsx", header=0)
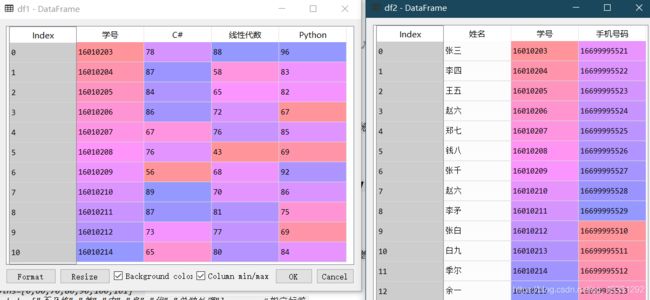
给df1增加“姓名”列,姓名信息来自df2
df1=pd.merge(df1, df2,left_on="学号",right_on="学号")
df1=df1.drop(columns=["手机号码"]) #因为要添加姓名列,所以要把多余的数据删掉
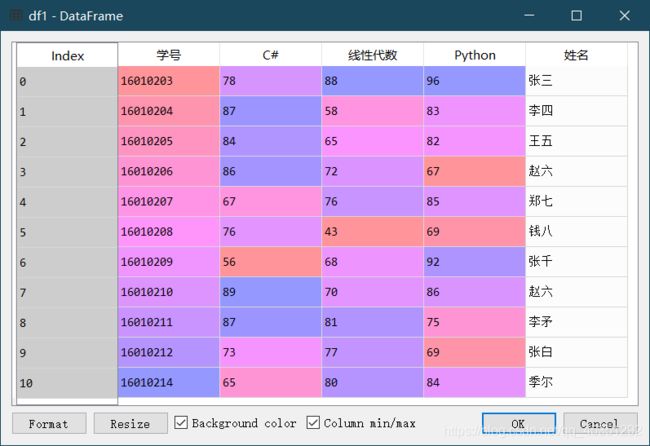
11.给df1增加“平均分”列,该列的值来自每位学生三门课程的平均成绩。
第一种
df1["平均分"]=(df1["C#"]+df1["线性代数"]+df1["Python"])/3
第二种
df1["平均分"]=df1.iloc[:,1:4].mean(axis=1) #切片找出三门课,在进行横向求平均值
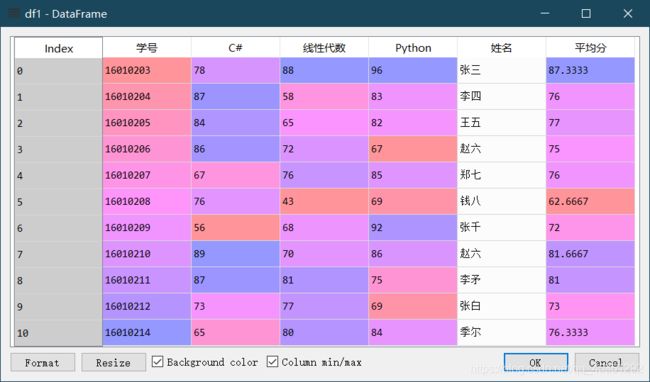
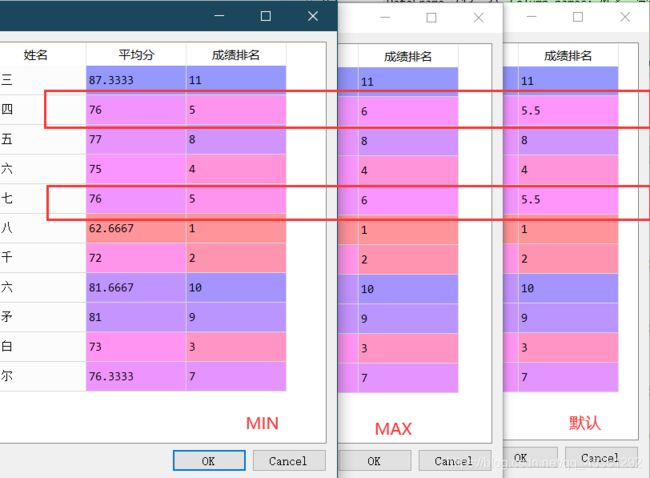
12.排名函数 .rank(ascending = False, method = ‘max’)
给df1增加“成绩排名”列,该列的值来自学生的平均分排名。
df1["成绩排名"]=df1.平均分.rank()
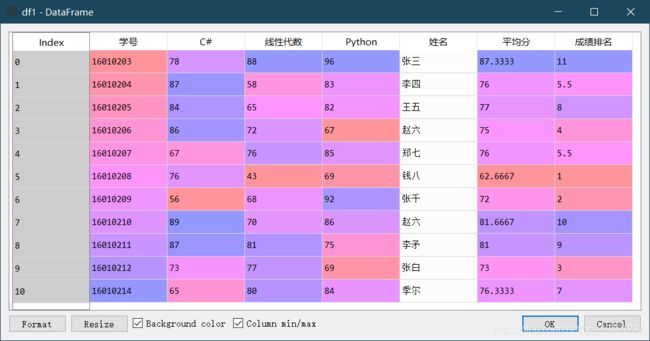
小知识: .rank(ascending = False, method = ‘max’)
ascending = False :表示降序 ,True:表示升序
method = ‘max’ :
max:表示在排名值为并列时向上取排名值
min:表示在排名值为并列时向下取排名值
默认 :则呈现小数点的形式
13.数据分组 pd.cut(指定的统计值 , bins 统计结果的行标签, labels=labels 统计结果的列标签,right=False 为闭区间,include_lowest=True 为开区间,aggfunc=[np.size,np.mean]要统计函数)
给df1添加“等级”列,按照平均成绩划分等级:[0,60 )为“不及格;[60,70 )为“差”; [70,80 )为“中”;[80, 90)为“良”;[90,100 )为“优”。 如果存在100分的,则需要对100分单独处理。
bins=[0,60,70,80,90,100,101]
labels=["不及格","差","中","良","优","单独处理"] #指定标签
df1["等级"]=pd.cut(df1.平均分,bins,labels=labels,right=False,include_lowest=True)
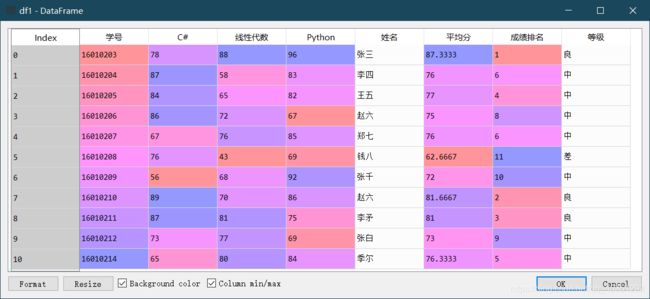
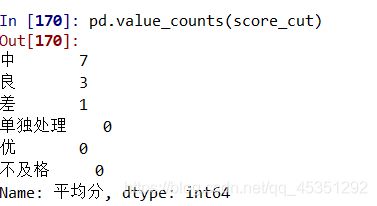
统计忧、良、中、差的人数 .value_counts(score_cut)
pd.value_counts(score_cut) #数score——cut中数量
14.分组分析.groupby()
引入数据
df=pd.read_excel("d://2007年12月CET4成绩.xls",header=0)
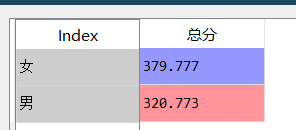
①男女分组,取总分这一列并求平均得分
df1=df.groupby(["性别"])["总分"].mean()
或
df["总分"].groupby(df["性别"]).mean()
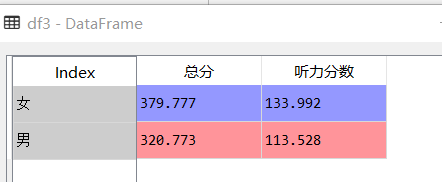
②获取多列分组统计
df3=df.groupby(["性别"])["总分","听力分数"].mean()
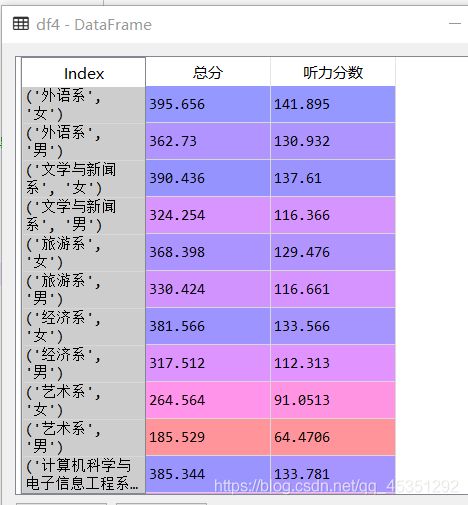
③使用多列分组对一列或多列求统计
df4=df.groupby(["院系名称","性别"])["总分","听力分数"].mean()
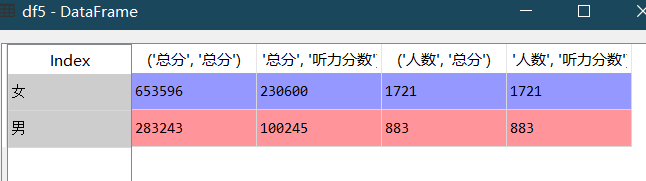
④一次分组得到多列分组统计值
df5=df.groupby(["性别"])["总分","听力分数"].agg({'总分':np.sum,'人数':np.size})
⑤统计缺考人数
df[df['缺考']=="缺"].缺考.size

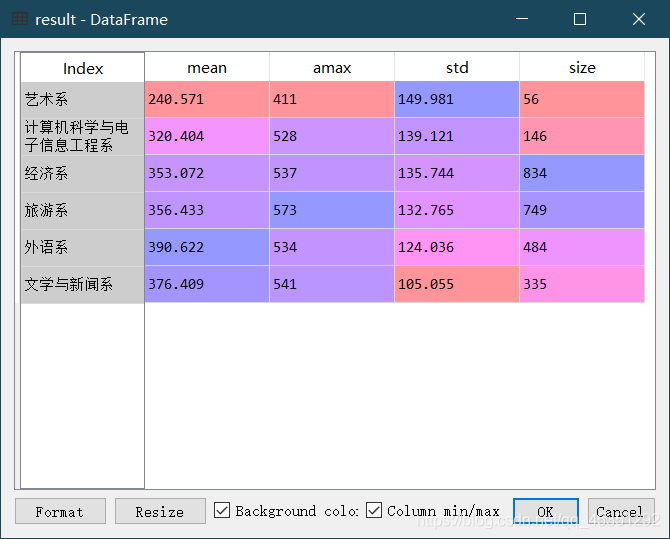
15. 排列 .sort_values(ascending=False降序,inplace=True是否在原对象基础上进行修改)
将result按平均分降序排列。
result=df.groupby(["院系名称"])["总分"].agg([np.mean,np.max,np.std,np.size]) #创建result
result.sort_values("std",inplace=True,ascending=False)
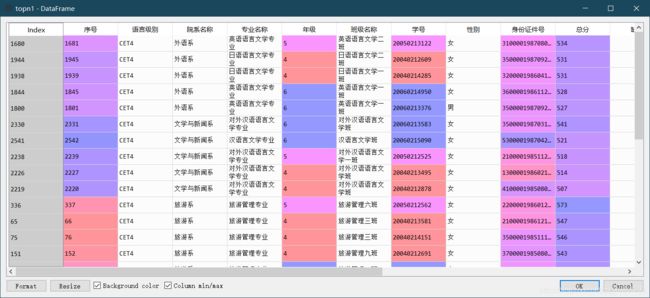
16. 按院系名称分组后得到每个院系总分前5名的数据记录
def topn(x,n=5):
return x.sort_values(by='总分',ascending=False)[:n] #按总分进行降序排序,再用切片取前五个
topn1=df.groupby("院系名称",group_keys=False).apply(topn)
小知识:
apply(func [, args [, kwargs ]]) 函数用于当函数参数已经存在于一个元组或字典中时,间接地调用函数。
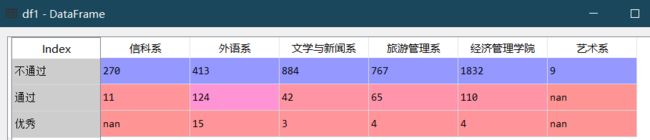
17.交叉分析 .pivot_table()
pivot_table(self,values=None, 指定行标签名index=None, 列标签columns=None, aggfunc=‘mean’, 缺失值 fill_value=None, margins=False, dropna=True, margins_name=‘All’, observed=False)
创建数据
df=pd.read_excel("d://2010年12月CET4成绩.xls", header=0)
通过交叉分析得到各院系各分数段人数,将统计结果赋值给df1。分数段划分如下:420以下(标记为不通过),420~510(标记为通过), 510分及以上(标记为优秀)。院系名称为列索引标签,分数段标记作为行索引标签。
bins=[min(df.总分),420,510,max(df.总分)+1] #定义区间
labels=["不通过","通过","优秀"] #指定区间行标签
df['总分分层']=pd.cut(df.总分,bins,labels=labels,right=False,include_lowest=True) #定义一个新列标签,进行分组
df1=df.pivot_table(values=['总分'],index=["总分分层"],columns=["院系名称"],aggfunc=[np.size]) #利用交叉分析把总分分层提取出来进行可视化
df1.columns=map(lambda x:x[2] , df1.columns) #将df1的列标签切片
df1=df1.replace(np.nan,0) #将df1中的'nan'值更改为'0'
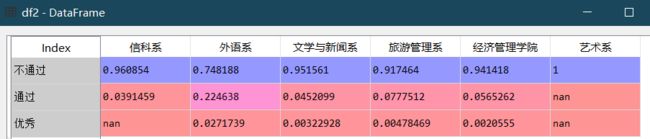
18.结构分析 .div()
利用df1进一步统计各分数段各学院的人数占比
df2=df1.div(df1.sum(axis=0),axis=1)
19.相关性分析 .corr()
df3=df[["总分","听力分数","阅读分数","写作分数","综合测试分数"]]
df3=df3.corr()

20.日期处理to_datetime(要处理的日期, format=当前的日期格式)
读取一个文件
df=pd.read_csv("d://城市序列数据.csv",sep=',',header=0,engine='python')
小知识:
sep=’,’ #分隔符 因为是CSV文件而里面的数据是用逗号分隔的
engine=‘python’ #默认为‘’C‘’ 所以要将其改为python
日期处理:将字符型日期格式转换为日期格式数据
to_datetime(要处理的日期, format=当前的日期格式)
df.日期= to_datetime(df.日期, format="%Y%m%d")
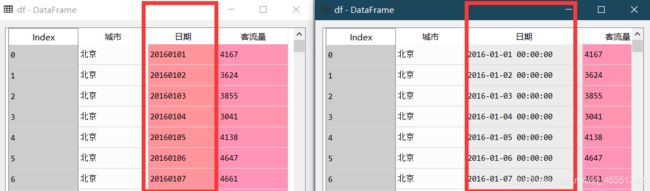
提示:
from pandas import to_datetime 用到这个库
21.可视化
垂直柱形图 plt.bar(横轴,纵轴)
8个月中客流总量前五的城市,并绘制柱形图
df=pd.read_csv("d://城市序列数据.csv",sep=',',header=0,engine='python') #导入数据
df1=df.groupby(['城市'])['客流量'].sum().sort_values(ascending=False)[:5] #找出客流量前五的城市
plt.bar(df1.index,df1.values) #绘制柱形图
plt.title('客流总量前五城市') #设置标题
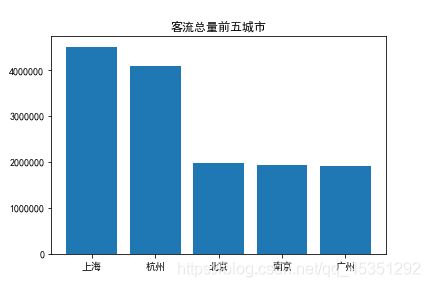
小知识:
①低版本的spyder需要设置这两条命令,才能使横坐标的中文不乱码
font={'family':'SimHei'} #便于图中显示中文
matplotlib.rc('font',**font) #用到这个库import matplotlib
水平柱状图 plt.barh(横轴,纵轴)
df=pd.read_csv("d://城市序列数据.csv",sep=',',header=0,engine='python') #导入数据
df1=df.groupby(['城市'])['客流量'].sum().sort_values(ascending=False)[:5] #找出客流量前五的城市
plt.barh(df1.index,df1.values) #绘制柱形图
plt.title('客流总量前五城市') #设置标题
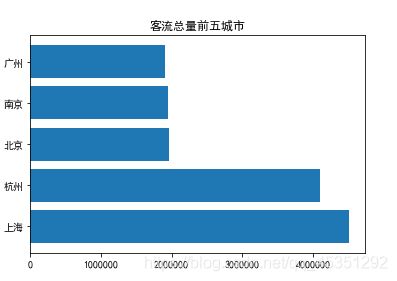
柱状堆积图
data1= np.arange(1,5)
data2=[20,6,58,34]
data3=[15,62,58,8]
plt.bar(data1,data2)
plt.bar(data1,data3,bottom=data2)
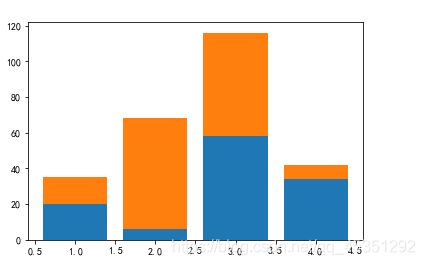
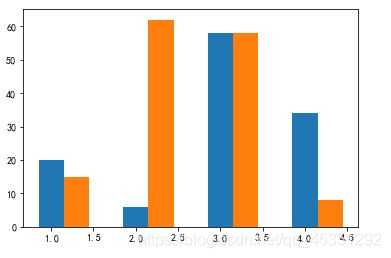
左右柱状图
data1= np.arange(1,5)
data2=[20,6,58,34]
data3=[15,62,58,8]
width=0.3 #设置偏移大小
plt.bar(data1,data2,width=width)
plt.bar(data1+width,data3,width=width)
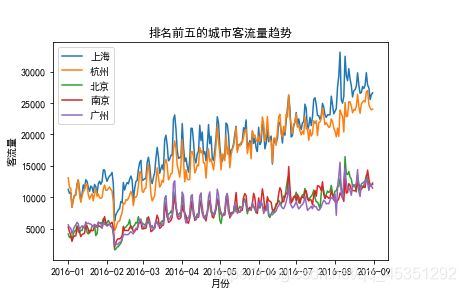
折线图 plt.plot(横轴,纵轴)
描绘排名前五的城市客流量趋势(即折线图)
df=pd.read_csv("d://城市序列数据.csv",sep=',',header=0,engine='python') #读取数据
df.日期= to_datetime(df.日期, format="%Y%m%d") #将df中的日期形式更改为真正日期的形式
df1=df.groupby(['城市'])['客流量'].sum().sort_values(ascending=False)[:5] #找出排名前五的城市
df3=DataFrame({}) #构造数据框,存放目标数据 不指定DatFrame形式就会默认Series。
for i in range(5): #遍历5次
tempdf=DataFrame({}) #每次循环都将临时tempdf设为空对象
tempdf[df1.index[i]]=df['客流量'][df.城市==df1.index[i]] #将排名前五的城市,存入到临时变量中
#df1rank.index[i]第i个城市名称
tempdf.index=df.日期.drop_duplicates() #.drop_duplicates()去重处理
df3[df1.index[i]] = tempdf[df1.index[i]] #插入到df3中即折线图
plt.plot(df3.index,df3.上海) #依次将每个城市写入折线图中
plt.plot(df3.index,df3.杭州)
plt.plot(df3.index,df3.北京)
plt.plot(df3.index,df3.南京)
plt.plot(df3.index,df3.广州)
plt.title("排名前五的城市客流量趋势") #设置标题
plt.xlabel('月份') #设置横坐标标签
plt.ylabel("客流量") #设置纵坐标标签
plt.legend(['上海','杭州','北京','南京','广州']) #设置左上角的漂浮提示框
小知识:
如果你画图是发现图不对,但是你又觉得代码没有什么问题,那你可以加上一个这个代码
报错如下:

plt.figure(1) #plt.figure(‘指定为那个画板’) #有设置画板的作用
可视化个性化设置
x = np.arange(10)
y = 2*x +1
plt.plot(x,y,color='red',marker='D',linestyle='--')
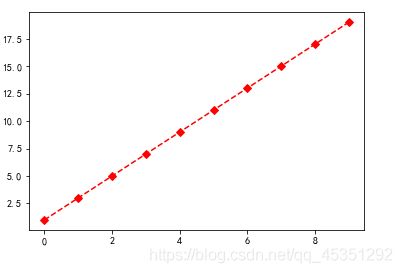
小知识:
color=‘pink’ 指定颜色
marker=‘D’ 特点
linesyle=’–’ 线条风格