阿里数据同步框架canal
前言
在日常的工作中,数据同步可以说是每个公司都会遇到的业务场景,但是大多数中小型企业并没有很好的数据同步方案,基本都是用代码逻辑来实现的,不仅有代码入侵,而且效率也不好,所以如何能实现数据的增量同步成了很多公司的痛点。今天介绍一个阿里的开源框架canal,他可以很好的同步增量数据到其它的存储应用。
官网地址:https://github.com/alibaba/canal
一、canal是什么
官网介绍:
canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
这句话有几个关键字:增量日志,增量数据订阅和消费。
我们可以简单的把canal理解为一个同步增量数据的工具。
接下来看一张官网提供的示意图:
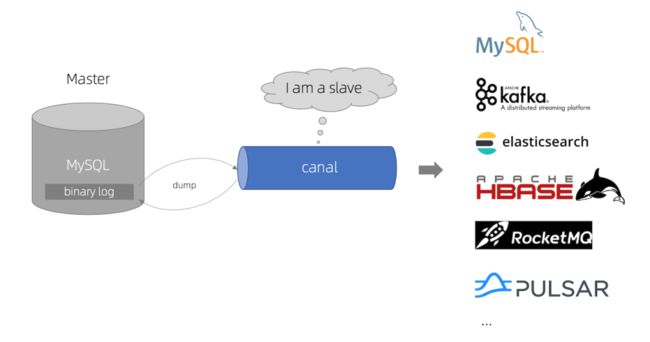
canal的工作原理就是把自己伪装成MySQL slave,模拟MySQL slave的交互协议向MySQL Mater发送 dump协议,MySQL mater收到canal发送过来的dump请求,开始推送binary log给canal,然后canal解析binary log,再发送到存储目的地,比如MySQL,Kafka,ElasticSearch等等。
二、canal能做什么?
canal的数据同步不是全量的,而是增量。基于binlog增量订阅和消费,canal的业务包括:
-
数据库镜像
-
数据库实时备份
-
索引构建和实时维护
-
业务cache刷新
-
带业务逻辑的增量数据处理
三、canal怎么用?
1. MySQL服务器
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x。
我的Linux服务器安装的是MySQL5.7版本。
然后在MySQL中需要创建一个用户,并授权:
--创建用户 用户名canal 密码canalCREATE USER canal IDENTIFIED BY 'canal';--授权 *.*表示所有库GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';--刷新使立即生效FLUSH PRIVILEGES;
进入mysql验证一下是否生效
select * from mysql.user where user='canal' \G
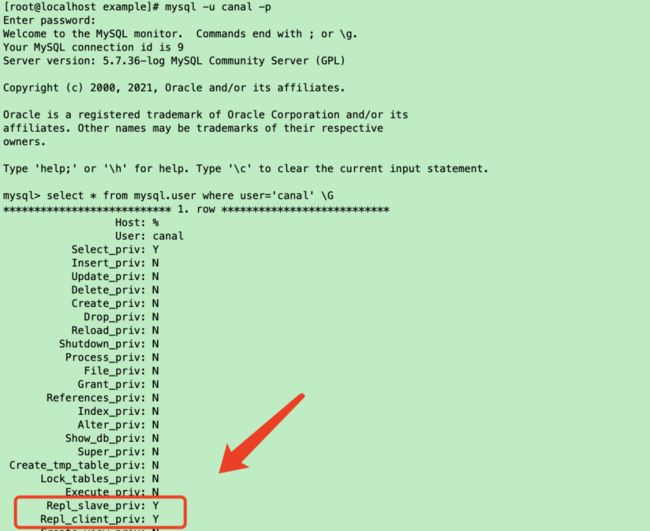
可以看到授权成功,一定要确保授权成功,不然canal没有权限去读mysql的数据。
下一步在MySQL配置文件/etc/my.cnf设置如下信息(不同版本不同环境的MySQL配置文件名称和路径略有差异,需自己找一下):
[mysqld]# 打开binloglog-bin=mysql-bin# 选择ROW(行)模式binlog-format=ROW# 配置MySQL replaction需要定义,不要和canal的slaveId重复server_id=1
改了配置文件之后,重启mysql,使用命令查看是否打开binlog模式:
--是否打开binlog模式show variables like 'log_bin';--查看binlog日志文件列表show binary logs;--查看当前正在写入的binlog文件show master status;
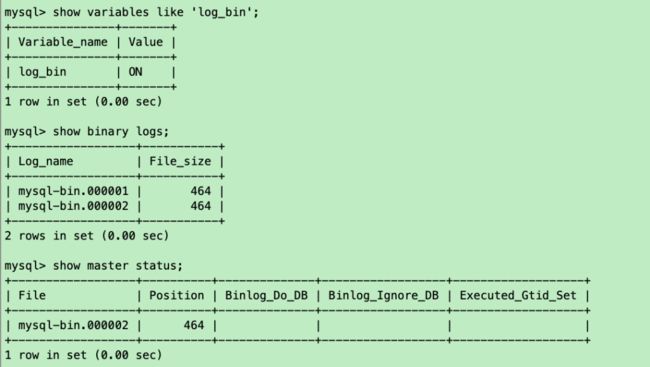
MySQL服务器配置就完成了。
2. canal服务端安装
官网下载安装包:
https://github.com/alibaba/canal/releases
我下载的是1.1.5版本 >>

解压后可以看到里面有5个文件夹:
接着打开配置文件:
conf/example/instance.properties,配置信息如下:
## mysql serverId , v1.0.26+ will autoGen# v1.0.26版本后会自动生成slaveId,所以可以不用配置# canal.instance.mysql.slaveId=0# 这里需要配一下数据库地址,其它信息可以不配# 数据库地址canal.instance.master.address=127.0.0.1:3306# binlog日志名称canal.instance.master.journal.name=# mysql主库链接时起始的binlog偏移量canal.instance.master.position=# mysql主库链接时起始的binlog的时间戳canal.instance.master.timestamp=canal.instance.master.gtid=# 配置canal的用户名密码canal.instance.dbUsername=canalcanal.instance.dbPassword=canal# table regex# .*\\..*表示监听所有表 也可以写具体的表名,用,隔开canal.instance.filter.regex=.*\\..*# table black regex# 数据解析表的黑名单,多个表用,隔开canal.instance.filter.black.regex=mysql\\.slave_.*
配置完成之后进入bin目录找到startup.sh启动:
启动完之后进入logs/example/example.log目录查看一下启动是否有问题:
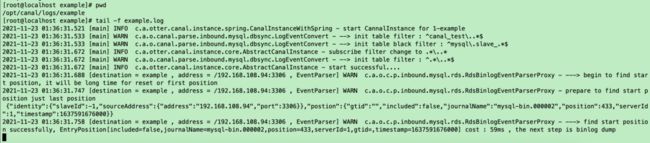
可以看到canal启动成功并且打印出了和master节点的连接信息。
四、Java客户端操作
1. 新建一个springboot项目,修改pom文件,引入依赖(注意我这里引的是1.1.0版本,因为官网的案例是基于这个版本的,1.1.5的话,部分方法可能有所改动,不能直接用,但是提供的功能都是相同的):
com.alibaba.otter canal.client 1.1.0
2. 新建一个Test类,将官网提供的ClientSample代码复制过来,地址:
https://github.com/alibaba/canal/wiki/ClientExample
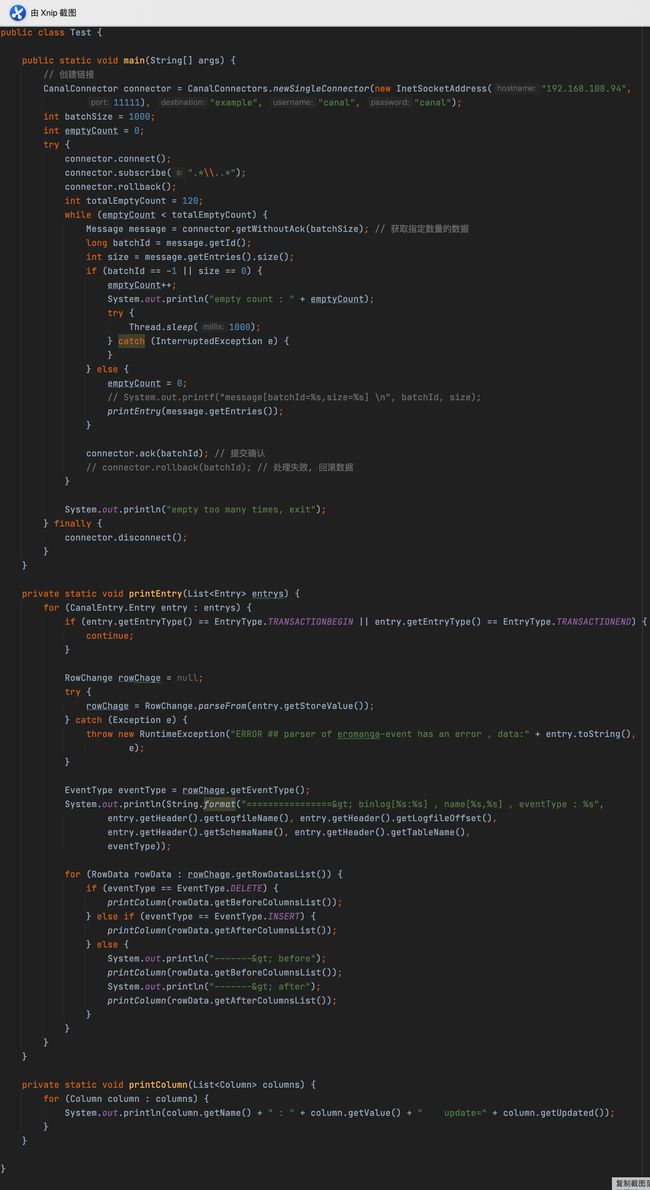
在main方法中修改一下连接信息,然后右键启动,可以从控制台中看到类似消息:

表明Java客户端已经连接到了canal,我们接下来做个测试:
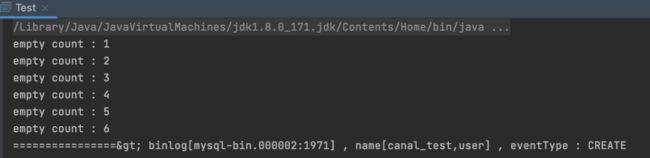
a. 创建一张user表:
CREATE TABLE `user_test` (`id` int NOT NULL,`name` varchar(20) DEFAULT NULL COMMENT '名字',`age` int DEFAULT '0' COMMENT '年龄',PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
然后在控制台中立马就可以看到如下信息
b. 新增一条数据,查看控制台打印的信息:
insert into user(id, name, age) values('1', 'zhangsan', '20');

c. 修改这条数据,查看控制台打印的信息:

总结
canal的好处在于对业务代码没有侵入,因为是基于监听binlog日志去进行同步数据的。而且能做到同步数据的实时性,是一种比较好的数据同步方案。
以上只是canal的原理和入门,实际项目并不是这样玩的,在实际项目中我们是配置MQ模式,配合RabbitMQ或者Kafka,canal会把数据发送到MQ中的topic,然后通过消息队列的消费者进行处理。
