同步机制比较
-
背景
开发过程中经常用到同步相关场景,比如多进程、多线程、协程等,每种机制都有各自的优缺点。俗话说的好,存在即合理,每种机制既然还存在就代表还有各自的不可替代性,因此了解每种机制的优缺点能帮助我们更好判断每种场景下适合的方案,下面就简单来分析一下
-
几种同步机制比较
1、并发与并行
看起来它们好像都一样,但其实还是有区别的:
并发:当有多个线程在操作时,如果系统只有一个CPU,则它根本不可能真正同时进行一个以上的线程,它只能把CPU运行时间划分成若干个时间段,再将时间 段分配给各个线程执行,在一个时间段的线程代码运行时,其它线程处于挂起状。.这种方式我们称之为并发(Concurrent)。
并行:当系统有一个以上CPU时,则线程的操作有可能非并发。当一个CPU执行一个线程时,另一个CPU可以执行另一个线程,两个线程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。
2、Future与Promise
1)Future:一种线程间通信方式,它是用于主线程获取子线程中的变量,可以来看一下android中的实现:
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
// The code below is very delicate, to achieve these goals:
// - call nanoTime exactly once for each call to park
// - if nanos <= 0L, return promptly without allocation or nanoTime
// - if nanos == Long.MIN_VALUE, don't underflow
// - if nanos == Long.MAX_VALUE, and nanoTime is non-monotonic
// and we suffer a spurious wakeup, we will do no worse than
// to park-spin for a while
long startTime = 0L; // Special value 0L means not yet parked
WaitNode q = null;
boolean queued = false;
for (;;) {
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
else if (s == COMPLETING)
// We may have already promised (via isDone) that we are done
// so never return empty-handed or throw InterruptedException
Thread.yield();
else if (Thread.interrupted()) {
removeWaiter(q);
throw new InterruptedException();
}
else if (q == null) {
if (timed && nanos <= 0L)
return s;
q = new WaitNode();
}
else if (!queued)
queued = U.compareAndSwapObject(this, WAITERS,
q.next = waiters, q);
else if (timed) {
final long parkNanos;
if (startTime == 0L) { // first time
startTime = System.nanoTime();
if (startTime == 0L)
startTime = 1L;
parkNanos = nanos;
} else {
long elapsed = System.nanoTime() - startTime;
if (elapsed >= nanos) {
removeWaiter(q);
return state;
}
parkNanos = nanos - elapsed;
}
// nanoTime may be slow; recheck before parking
if (state < COMPLETING)
LockSupport.parkNanos(this, parkNanos);
}
else
LockSupport.park(this);
}
}
上面是调用Future.get()的实现逻辑,可以看出其实是把当前线程挂起了,再来看一下什么时候恢复:
public void run() {
if (state != NEW ||
!U.compareAndSwapObject(this, RUNNER, null, Thread.currentThread()))
return;
try {
Callable c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
protected void set(V v) {
if (U.compareAndSwapInt(this, STATE, NEW, COMPLETING)) {
outcome = v;
U.putOrderedInt(this, STATE, NORMAL); // final state
finishCompletion();
}
}
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) {
if (U.compareAndSwapObject(this, WAITERS, q, null)) {
for (;;) {
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
done();
callable = null; // to reduce footprint
}
其实看了源码就会发现逻辑还是很清晰的,就是获取值得时候挂起当前线程,直到异步任务执行完后再唤醒,同时返回结果
2) Promise:异步线程获取主线程变量的一种方式,和Future刚好配对,同样看一下android上实现:
private final CountDownLatch resolved;
public T getValue() throws InvocationTargetException, InterruptedException {
this.resolved.await();
if (this.fail == null) {
return this.value;
} else {
throw new InvocationTargetException(this.fail);
}
}
void resolve(T v, Throwable f) {
synchronized(this.resolved) {
if (this.resolved.getCount() == 0L) {
throw new IllegalStateException("Already resolved");
}
this.value = v;
this.fail = f;
this.resolved.countDown();
}
this.notifyCallbacks();
}上面逻辑同样很清晰,在获取值得时候会被CountDownLatch卡住,等主线程变量值准备好的时候调用resolve来唤醒CountDownLatch就能获取到值了
3、协程与线程
1)协程概念
协程是一种用户态的轻量级线程,协程的调度完全由用户控制。从技术的角度来说,“协程就是你可以暂停执行的函数”。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快,这样带来的好处是性能得到了很大的提升,不会像线程切换那样消耗资源,但是...Java语言并没有对协程的原生支持,所以我们说的android上的协程并不是真的协程~
2) 协程与线程的区别:
- 一个线程可以多个协程,一个进程也可以单独拥有多个协程。
- 线程进程都是同步机制,而协程则是异步。
- 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态。
- 线程是抢占式,而协程是非抢占式的,所以需要用户自己释放使用权来切换到其他协程,因此同一时间其实只有一个协程拥有运行权,相当于单线程的能力。
- 协程并不是取代线程, 而且抽象于线程之上, 线程是被分割的CPU资源, 协程是组织好的代码流程, 协程需要线程来承载运行, 线程是协程的资源, 但协程不会直接使用线程, 协程直接利用的是执行器(Interceptor), 执行器可以关联任意线程或线程池, 可以是当前线程, UI线程, 或新建进程.。
- 线程是协程的资源。协程通过Interceptor来间接使用线程这个资源
3)有了上面基本区别,我们也能发现各自的优缺点:
- 协程优点是用户态程序,因此切换是不耗费时间的,同时可以随时挂起和恢复,可以让代码逻辑以同步方式展现,逻辑更加清晰,但是同样它缺点也很明显,协程是非抢占式的,因此同一时间只有一个协程在执行,如果需要大量并发操作的任务性能会跟不上
- 线程相对于协程的优缺点则刚好相反,它的优点是充分利用CPU资源进行并发操作,缺点则是切换开销
4)通过上面简单比较,它们的适用场景也是很明显的
- 对于并发要求不大,但是切换频繁的场景比较适合协程
- 对于并发量很高又不需要频繁切换线程的场景就比较适合线程
- 当两者差不多时协程对代码逻辑书写方面也有很大帮助,可以考虑协程
5)Kotlin协程
kotlin的协程并不是真正的协程,它是一种模拟协程,即结合多线程与协程的挂起机制,因此这种协程切换还是有内核开销的,但是同时具备多线程并发优势,也是一种不错的架构
4、多进程与多线程
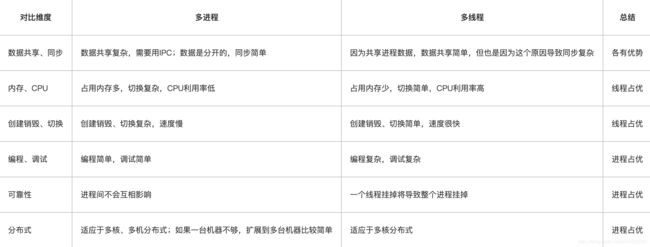
上面是多进程与多线程的一些对比,先了解一下它们基本特点,然后我们开始看一下它们分别适合什么场景?
1)需要频繁创建销毁的优先用线程
原因请看上面的对比。
这种原则最常见的应用就是Web服务器了,来一个连接建立一个线程,断了就销毁线程,要是用进程,创建和销毁的代价是很难承受的
2)需要进行大量计算的优先使用线程
所谓大量计算,当然就是要耗费很多CPU,切换频繁了,这种情况下线程是最合适的。
这种原则最常见的是图像处理、算法处理。
3)强相关的处理用线程,弱相关的处理用进程
什么叫强相关、弱相关?理论上很难定义,给个简单的例子就明白了。
一般的Server需要完成如下任务:消息收发、消息处理。“消息收发”和“消息处理”就是弱相关的任务,而“消息处理”里面可能又分为“消息解码”、“业务处理”,这两个任务相对来说相关性就要强多了。因此“消息收发”和“消息处理”可以分进程设计,“消息解码”、“业务处理”可以分线程设计。
当然这种划分方式不是一成不变的,也可以根据实际情况进行调整。
4)可能要扩展到多机分布的用进程,多核分布的用线程
原因请看上面对比。
5)都满足需求的情况下,用你最熟悉、最拿手的方式
至于“数据共享、同步”、“编程、调试”、“可靠性”这几个维度的所谓的“复杂、简单”应该怎么取舍,我只能说:没有明确的选择方法。但我可以告诉你一个选择原则:如果多进程和多线程都能够满足要求,那么选择你最熟悉、最拿手的那个。
6)总结:
- 进程是资源分配的基本单位,线程是CPU调度的基本单位,启动一个线程所花费的时间远远小于启动一个进程所花费的时间,而且,线程间彼此切换所需的时间也远远小于进程间切换所需要的时间,但是单核CPU上,任务量越大越能抹平进程在创建与销毁上的时间比重,同时扩大进程在资源分配上的独立性优势,因为进程间资源是独立的,不会互相影响,提高了效率与准确性
- 网上有人做了个实验:创建255个进程/线程,每个创建出的进程/线程打印600条“hello linux”字符串到控制台和日志文件,这时候多进程(时间包含进程创建与销毁)与多线程耗时基本相同。打印1000条时多进程比多线程快了1秒多
- 从上面分析中可以看出,在并发数超出CPU核数较多时,并且每个任务比较耗时情况下多进程反而比多线程来的快,在线程数增大时多线程程序还出现了运行错误,所以多进程与多线程都有各自的优缺点以及适合场景,这也是为什么它们不能互相取代的原因。
5、Actor与Reactor
1) Actor:一种通过消息传递方式来执行任务,彼此间互相独立,比较典型的是skynet框架
- 一个服务,默认不会执行任何逻辑,需要别人向它发出请求时,才会执行对应的逻辑(定时器也是通过消息队列,告诉指定服务,要执行定时事件),并在需要时返回结果给请求者。请求者往往也是其他服务。服务间的请求、响应和推送,并不是直接调用对方的api来执行,而是通过一个消息队列,也就是说,不论是请求、回应还是推送,都需要通过这个消息队列转发到另一个服务中
- skynet一共有4种线程,monitor线程用于检测节点内的消息是否堵住,timer线程运行定时器,socket线程进行网络数据的收发,worker线程则负责对消息队列进行调度(worker线程的数量,可以通过配置表指定)。消息调度规则是,每条worker线程,每次从全局消息队列中pop出一个次级消息队列,并从次级消息队列中pop出一条消息,并找到该次级消息队列的所属服务,将消息传给该服务的callback函数,执行指定业务,当逻辑执行完毕时,再将次级消息队列push回全局消息队列中。因为每个服务只有一个次级消息队列,每当一条worker线程,从全局消息队列中pop出一个次级消息队列时,其他线程是拿不到同一个服务,并调用callback函数,因此不用担心一个服务同时在多条线程内消费不同的消息,一个服务执行,不存在并发,线程是安全的
- 注意:服务模块要将数据,通过socket发送给客户端时,并不是将数据写入消息队列,而是通过管道从worker线程,发送给socket线程,并交由socket转发。此外,设置定时器也不走消息队列,而是直接将在定时器模块,加入一个timer_node。其实这样也很好理解,因为timer和socket线程内运行的模块并不是这里的context,因此消息队列他们无法消费
- 消息是如何写入到消息队列中去的。我们要向一个服务发消息,最终是通过调用skynet.send接口,将消息插入到该服务专属的次级消息队列的,次级消息队列的内容,并不是context结构的一部分(context只是引用了他的指针),因此,在一个服务执行callback的同时,其他服务(可能是多个线程内执行callback的其他服务)可以向它的消息队列里push消息,而message_queue的push操作,是加了一个自旋锁(自旋锁不会使线程状态发生切换,一直处于用户态,即线程一直都是active的;不会使线程进入阻塞状态,减少了不必要的上下文切换,执行速度快),以避免多个线程,同时操作一个消息队列,代码如下:
// skynet_server.c
int skynet_context_push(uint32_t handle, struct skynet_message *message) {
struct skynet_context * ctx = skynet_handle_grab(handle);
if (ctx == NULL) {
return -1;
}
skynet_mq_push(ctx->queue, message);
skynet_context_release(ctx);
return 0;
}
// skynet_handle.c
struct skynet_context * skynet_handle_grab(uint32_t handle) {
struct handle_storage *s = H;
struct skynet_context * result = NULL;
rwlock_rlock(&s->lock);
uint32_t hash = handle & (s->slot_size-1);
struct skynet_context * ctx = s->slot[hash];
if (ctx && skynet_context_handle(ctx) == handle) {
result = ctx;
skynet_context_grab(result);
}
rwlock_runlock(&s->lock);
return result;
}备注:在创建一个服务时会把这个服务注册到handle_storage里面,同时把服务对应的mq添加到global_queue,global_queue负责对外提供次级消息队列,添加消息到服务会直接访问handle_storage来获取次级消息队列,然后push message,其实整体看下来skynet和android服务框架非常类似~
2)Reactor:一种基于事件驱动的IO多路复用框架
普通的函数处理机制为:调用某函数-> 函数执行, 主程序等待阻塞-> 函数将结果返回给主程序-> 主程序继续执行
Reactor事件处理机制为:主程序将事件以及对应事件处理的方法在Reactor上进行注册, 如果相应的事件发生,Reactor将会主动调用事件注册的接口,即 回调函数. libevent即为封装了epoll并注册相应的事件(I/O读写,时间事件,信号事件)以及回调函数,实现的事件驱动的框架,典型的是Nodejs框架
IO多路复用:先来看一段简单代码:
# coding: utf-8
# blocking / epoll io client
import selectorsimport socket
import time
sel = selectors.DefaultSelector()
def accept(sock, mask):
conn, addr = sock.accept() # Should be ready,拷贝到内存空间,并分配一个新的socket,给当前接入的请求
print('accepted', addr)
conn.setblocking(False)
sel.register(conn, selectors.EVENT_READ, read) # 将这个sokcet注册到 sel,也就是sel也可以开始监听这个sock,并注册回调,等待下次轮训
def read(conn, mask):
data = conn.recv(1000) # 下次轮训,执行这个回调
if data:
print('echoing', conn)
conn.send(data) # 回传数据给请求方。
print('send over', conn)
else:
print('closing', conn)
sel.unregister(conn) # 请求结束,删除socket监听
conn.close()
sock = socket.socket() # 绑定一个socket
sock.bind(('localhost', 12325))
sock.listen(100)
sock.setblocking(False)
sel.register(sock, selectors.EVENT_READ, accept) # selector注册监听这个socket。可以把这个sokcet当作一个流。一直监听的只有这个接收请求的socket
i = 1
while True: # 轮训sel的ready事件
events = sel.select()
time.sleep(10)
for key, mask in events:
callback = key.data
callback(key.fileobj, mask)
print('this is ', i)
i += 1
其中while循环前将socket添加到select监视中,然后在while内一直调用select获取被激活的socket,一旦socket可读,便调用read函数将socket中的数据读取出来
可以观察到,sel.select()每次选出一个sock,然后对这个sock上的事件进行处理。所以io多路复用,在没有用特殊异步api的情况下,还是同步的操作,唯一不同是不阻塞接收下一个请求,这里主要用到了系统提供的Select机制
以select为例,将关注的IO操作告诉select函数并调用,进程阻塞,内核“监视”select关注的文件描述符fd,被关注的任何一个fd对应的IO准备好了数据,select返回。再使用read将数据复制到用户进程。
select可同时监听的文件描述符数量(socket)是通过FS_SETSIZE来限制的,在Linux系统中,该值为1024,当然我们可以增大这个值,但随着监听的文件描述符数量增加,select的效率会降低
3) Actor与Reactor比较
Actor:
优点:
Actors一大重要特征在于actors之间相互隔离,它们并不互相共享内存。也就是说,一个actor能维持一个私有的状态,并且这个状态不可能被另一个actor所改变
缺点:
一个Actor同时只能在一个work_thread中执行,对于要求高并发的任务来说效率上会有点不足
Reactor:
优点:
Reactor实现相对简单,对于耗时短的处理场景处理高效;
操作系统可以在多个事件源上等待,并且避免了多线程编程相关的性能开销和编程复杂性;
事件的串行化对应用是透明的,可以顺序的同步执行而不需要加锁;
事务分离:将与应用无关的多路分解和分配机制和与应用相关的回调函数分离开来
缺点:
Reactor处理耗时长的操作会造成事件分发的阻塞,影响到后续事件的处理,如果中途执行错误就要重头开始,所以不适合链路过长类型
适用场景:
同时接收多个服务请求,并且依次同步的处理它们的事件驱动程序
4)总结:
Actor与Reactor是框架层次上的异步与同步机制,这里只是初步介绍这两个机制的特点,个人觉得在设计项目的模块化上面可以考虑Actor机制,在单个模块上面的架构上面可以考虑Reactor或其他架构,比如,用类似skynet设计多模块结构,其中某个负责数据拉取与处理的模块就可以采用类似nodejs的I/O多路复用结构,负责某个业务的模块可以采用Jetpack结构等等
-
总结
上面按照从小到大的顺序依次介绍了线程内的同步机制、线程与协程的同步机制、进程与线程的同步机制、最后上升到框架结构的actor与reactor同步机制,帮助大家初步了解了目前常见的一些同步结构,同时大概介绍了它们的异同点、优缺点、适用场景,让大家对同步大家族有个基本的认识,个人觉得在设计一个框架或者一个模块,甚至一个小的功能点时只有对同步相关知识有个系统的了解才能更好选择适合的机制或者实现方式,同时后期维护和扩展也更加方便!