kafka为什么速度快总结
kafka被广泛运用在各个系统中,被用来充当消息的中间件与数据总线的功能。而且我们都知道,kafka是基于磁盘存储的,但是描述kafka的形容词,最常见的经常有诸如速度快,延时小,吞吐量大这些,吞吐量能达到几十w甚至上百万每秒。而这些形容词,却与磁盘来说是格格不入的。所以kafka为什么快就成了一个经典的问题,下面我们就来进行初步总结。
1.顺序读写
kafka的数据持久化是在磁盘进行的。一提到磁盘,大家第一反应就是磁盘啊,那很慢啊,读写性能很差啊,很多时候系统整体性能就卡在磁盘的I/O上面,怎么基于一个磁盘的消息系统,还能做到快?
上面的说法,即对也不对。说他对,是因为磁盘的随机读写性能确实很差。但是说他不对,是因为不管内存还是磁盘,读写性能的快慢主要取决于数据的寻址方式,如果是顺序读写,性能就会很高了。贴一张 https://queue.acm.org/detail.cfm?id=1563874 上的图:
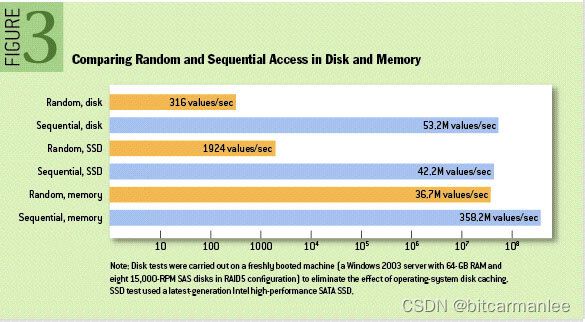
从上面的图不难看出,磁盘的随机读性能最差,只有可怜的316values/sec。但是如果是顺序读,却能达到53.2M values/sec,性能直接高了三个数量级,甚至超过了随机读内存。
kafka虽然是使用磁盘进行数据的持久化,但是使用的是顺序读取磁盘的方式。几乎所有kafka相关的文献都会指出,kafka通过不过将消息append(追加)到本地磁盘的文件末尾来完成消息的写入,这样kafka的吞吐量就大大得到了提升。在kafka中,每一个topic其实就是一个文件,分布式系统中的不同partition,则是在不同机器上对应的一个文件,下面就是某一个topic在本地磁盘上的存储。
00000000000000000025.index 00000000000000000025.log 00000000000000000025.snapshot 00000000000000000025.timeindex leader-epoch-checkpoint
我们主要关注一下xxx.index与xxx.log文件
log文件名是以文件中第一条message的offset来命名的,实际offset长度是64位,但是这里只使用了20位,应付生产是足够的。可以看出第一个log文件名是以25开头,而第二个log文件还没产生,说明该log文件产生之前该topic已经有24条消息。
而一组log+index+timeindex文件的名字都是一样的。
上面这种在文件末尾追加的方式,会带来一个弊端,就是无法删除数据。对应的,kafka也不能删除数据,而是会将所有的数据都保存下来,然后根据配置的删除策略来删除磁盘上对应的文件。
2.page cache
为了避免每次读写文件时,都需要对硬盘进行读写操作,Linux 内核使用 页缓存(Page Cache) 机制来对文件中的数据进行缓存。
在kafka中,利用了操作系统本身的page cache,也就是利用系统本身的内存而不是JVM虚拟机的内存来操作数据。这样主要的好处有如下几点
1.操作系统本身的page cache经过各种优化,本身就比其他的数据存储结果更为简单稳定可靠。kafka通过直接使用使用操作系统的page cache,让读写操作都基于内存进行,这样速度就得到了极大提升。
2.使用java堆内存的话,java对象内存消耗较大,通常是存储数据的两倍以上。
3.如果重度依赖java内存,JVM的GC问题将无法避免。
关于page cache,更为具体可以阅读参考文献1。
3.巧妙的文件结构设计
kafka的消息是以topic进行区分,每个topic相互独立不影响,而实际使用的时候,每个topic又都会进行分区,每个分区在物理上按大小被分成多个 segment,每个segment都包含有.log与.index等文件。
其中,index采用的是稀疏索引,这样能大大缩减index文件的大小。kafka采用mmap的方式,将index文件映射到内存中,这样对index的操作就直接在内存中进行不需要磁盘IO,大大提高了读写速度。
1.按照二分法找到小于 offset 的 segment 的.log 和.index
2.用目标 offset 减去文件名中的 offset 得到消息在这个 segment 中的偏移量。
3.再次用二分法在 index 文件中找到对应的索引。
4.到 log 文件中,顺序查找,直到找到 offset 对应的消息。
4.零拷贝
首先我们需要明确,零拷贝,不是说不需要拷贝,而是说减少不必要拷贝的次数,一般是指在IO读写过程中。
比如:读取文件,再用socket发送出去
传统方式实现:
先读取、再发送,实际经过1~4四次copy。
buffer = File.read
Socket.send(buffer)
1、第一次:将磁盘文件,读取到操作系统内核缓冲区;
2、第二次:将内核缓冲区的数据,copy到application应用程序的buffer;
3、第三步:将application应用程序buffer中的数据,copy到socket网络发送缓冲区(属于操作系统内核的缓冲区);
4、第四次:将socket buffer的数据,copy到网卡,由网卡进行网络传输。
传统方式,读取磁盘文件并进行网络发送,经过的四次数据copy是非常繁琐的。实际IO读写,需要进行IO中断,需要CPU响应中断(带来上下文切换),尽管后来引入DMA来接管CPU的中断请求,但四次copy是存在“不必要的拷贝”的。
重新思考传统IO方式,会注意到实际上并不需要第二个和第三个数据副本。应用程序除了缓存数据并将其传输回套接字缓冲区之外什么都不做。相反,数据可以直接从读缓冲区传输到套接字缓冲区。
显然,第二次和第三次数据copy 其实在这种场景下没有什么帮助反而带来开销,这也正是零拷贝出现的意义。
这种场景:是指读取磁盘文件后,不需要做其他处理,直接用网络发送出去。试想,如果读取磁盘的数据需要用程序进一步处理的话,必须要经过第二次和第三次数据copy,让应用程序在内存缓冲区处理。
具体详情可以见参考文献3
5.批量操作
对于大规模数据的读写,批量操作算是常规提升性能的手段之一。每次写入一大批数据,而不是一次写入一条数据,这样就能极大减少各种诸如IO之类的开销,大大提升系统的吞吐量。
6.批量压缩传输
kafka对数据采取了批量压缩传输的方式。kafka客户端向服务端发送数据的时候,并不是逐条消息发送,而是进行批量发送,同时还会对数据进行压缩。这样能节省宝贵的网络IO资源,提升系统整体性能。
参考文献
1.https://cloud.tencent.com/developer/article/1848933
2.https://www.cnblogs.com/rickiyang/p/13265043.html
3.https://zhuanlan.zhihu.com/p/78335525