Beego开发记录
很久以前自己总结在beego开发中遇到的常见问题,现在发出来,如有冒犯,可以联系我删除或添加引用,谢谢!
Beego开发记录
1.1 官方帮助文档
网页地址:https://beego.me/docs/intro/
1.2 goland 文件头自动注释
网页地址:https://blog.csdn.net/weixin_30902251/article/details/99167935
代码:
/**
* @Author: ${USER}
* @Description:
* @File: ${NAME}
* @Version: 1.0.0
* @Date: ${DATE} ${TIME}
*/
package ${GO_PACKAGE_NAME}
1.3 自动打包代码(bat)
rem @echo off
rem #GOARCH: 386 amd64
set GOARCH=amd64
rem GOOS:windows,linux
set GOOS=linux
rem go mod on/off
set GO111MODULE=on
for %%i in ("%~dp0\.") do (
set CurDir=%%~ni
)
set TARGET=bin/%CurDir%-%GOOS%-%GOARCH%%TARGETEXT%
echo building %TARGET% ...
go build -o %TARGET%
echo "OK"
pause
1.4 创建beego项目
在你的$GOPATH所在的目录中运行下面的命令,将会生成一个项目的框架结构,我们将其命名为sitepointgoapp
bee new sitepointgoapp
1.5 beego模板不转义
在使用beego框架后台传入前台数据时,传入数据较长,且使用
造成前面Html页面无法合理分段,在这种情况下,可以使用beego模板不转义,直接输出html格式内容。
模版中这样写 {{str2html .Content}}
str2html 这个函数让它转回html
1.6 后端数据如何传入前端js文件
在前面html文件中,内嵌js属性即可。
例如:
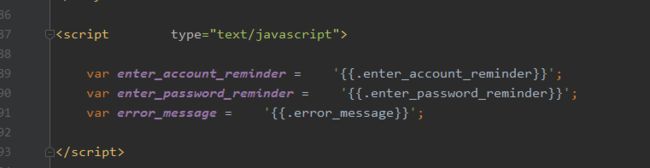
然后,再在js文件中,调用该属性。
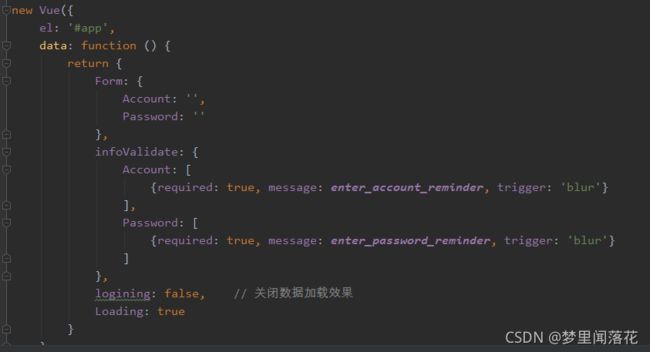
1.7 beego如何获取前一个页面URL
在controller中this.Ctx.Request.Referer()就可以获取前一个页面的URL,然后在找获取当前页面URL的方法时只找到了这个:
this.Ctx.Request.RequestURI
奇怪的是后面写的是URI,于是去查了下URI和URL的区别。
URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。而URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。而URN,uniform resource name,统一资源命名,是通过名字来标识资源,比如mailto:[email protected]。也就是说,URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。URL和URN都是一种URI。
大概是URI包括URL,使用的话还得看情况,但是使用URI是不会有问题的,而如果要使用URL,则要看它的可能取值,如果是绝对路径,能够定位的,那么用URL是没问题的。
1.8 Golang遍历读取文件夹下所有文件
来源于:https://blog.csdn.net/suiban7403/article/details/69538503
func GetAllFile(pathname string) error {
rd, err := ioutil.ReadDir(pathname)
for _, fi := range rd {
if fi.IsDir() {
fmt.Printf("[%s]\n", pathname+"\\"+fi.Name())
GetAllFile(pathname + fi.Name() + "\\")
} else {
fmt.Println(fi.Name())
}
}
return err
}
1.9 Golang数组的四种声明方法
//第一种
//var <数组名称> [<数组长度>]<数组元素>
var arr [2]int
arr[0]=1
arr[1]=2
//第二种
//var <数组名称> = [<数组长度>]<数组元素>{元素1,元素2,...}
var arr = [2]int{1,2}
//或者
arr := [2]int{1,2}
//第三种
//var <数组名称> [<数组长度>]<数组元素> = [...]<元素类型>{元素1,元素2,...}
var arr = [...]int{1,2}
//或者
arr := [...]int{1,2}
//第四种
//var <数组名称> [<数组长度>]<数组元素> = [...]<元素类型>{索引1:元素1,索引2:元素2,...}
var arr = [...]int{1:1,0:2}
//或者
arr := [...]int{1:1,0:2}
1.10 el-checkBox 文字超出长度换行
.el-checkbox__input {
display: inline-grid;
white-space: pre-line;
word-wrap: break-word;
overflow: hidden;
line-height: 20px;
}
1.11 Golang中用interface{}接收任何参数与强转
函数的传值中,interface{}是可以传任意参数的,就像java的object那样。
下面上我第一次想当然写的 ** 错误 **代码
package main
func main() {
Any(2)
Any("666")
}
func Any(v interface{}) {
v1:=int(v)
println(v1)
}
我只是想它能通过编译而已,因为上面的错误代码并没有任何的语法错误,心里只有666想说,下面是编译的错误提示:
cannot convert v (type interface {}) to type int: need type assertion
正确的代码就可以保证程序不出什么差错。
package main
func main() {
Any(2)
Any("666")
}
func Any(v interface{}) {
if v2, ok := v.(string);ok{
println(v2)
}else if v3,ok2:=v.(int);ok2{
println(v3)
}
}
输出如下
2
666
不得不惊叹go的严谨啊。java写类似代码一下就编过去了。
无形之中我喷了java 好多好多,但它毕竟是20年前的语言,比我年纪还大,有些问题是真的没办法,现在基于jvm的kotlin,如果我当时没有放弃android的话,我想我现在的主要工作语言就是它了。
解释一下,为什么Golang有些情况下,强转可以,有点情况下,强转不可以:
其实stack overflow一个国外大神说的很好了,
原话+野生翻译
The reason why you cannot convert an interface typed value are these rules in the referenced specs parts:
Conversions are expressions of the form T(x) where T is a type and x is an expression that can be converted to type T.
A non-constant value x can be converted to type T in any of these cases:
· x is assignable to T.
· x’s type and T have identical underlying types.
· x’s type and T are unnamed pointer types and their pointer base types have identical underlying types.
· x’s type and T are both integer or floating point types.
· x’s type and T are both complex types.
· x is an integer or a slice of bytes or runes and T is a string type.
· x is a string and T is a slice of bytes or runes.
But
iAreaId := int(val)is not any of the cases 1.-7.
1.12 Golang中创建无长度数组
//查找好友
func (service *ContactService)SearchFriend(userId int64)([]model.User) {
concents := make([]model.Contact,0)
objIds := make([]int64,0)
DbEngin.Where(&model.Contact{Ownerid:userId,Cate:model.CONCAT_CATE_USER}).Find(&concents)
for _,v := range concents{
objIds = append(objIds,v.Dstobj)
}
coms := make([]model.User,0)
if len(objIds) == 0{
return coms
}
DbEngin.Where("id = ?",objIds).Find(&coms)
return coms
}
1.13 golang strconv.ParseInt
func ParseInt(s string, base int, bitSize int) (i int64, err error)
参数1 数字的字符串形式
参数2 数字字符串的进制 比如二进制 八进制 十进制 十六进制
参数3 返回结果的bit大小 也就是int8 int16 int32 int64
代码:
package main import ( “strconv”) func main() { i, err := strconv.ParseInt(“123”, 10, 32) if err != nil { panic(err) } println(i)}
1.14 golang log简单使用例子详解
golang log标准库实现了简单日志服务。但不支持log分类、分级、过滤等复杂功能。由第三方库如glog(Github)、seelog(Github)
简单demo如下:
package main
import (
"log"
"os"
)
func main() {
file,err := os.Create("test.log")
if err != nil {
log.Fatalln("fail to create test.log file!")
}
defer file.Close()
logger := log.New(file, "info:", log.LstdFlags|log.Lshortfile)
logger.Println("this is phpddt.com testing")//info:2015/11/15 01:11:48 test.go:17: this is phpddt.com testing
}
可见,指定prefix可实现简单的分级。
通过查看源码可见logger结构:
type Logger struct {
mu sync.Mutex // ensures atomic writes; protects the following fields
prefix string // prefix to write at beginning of each line
flag int // properties
out io.Writer // destination for output
buf []byte // for accumulating text to write
}
日志格式flag的常量:
const (
Ldate = 1 << iota // the date in the local time zone: 2009/01/23
Ltime // the time in the local time zone: 01:23:23
Lmicroseconds // microsecond resolution: 01:23:23.123123. assumes Ltime.
Llongfile // full file name and line number: /a/b/c/d.go:23
Lshortfile // final file name element and line number: d.go:23. overrides Llongfile
LUTC // if Ldate or Ltime is set, use UTC rather than the local time zone
LstdFlags = Ldate | Ltime // initial values for the standard logger
)
1.15 GoLand中同一个目录同一个包调用不到另一个文件中函数
1.16 Golang timer定时器
timer 计时器
用于在指定的Duration类型时间后调用函数或计算表达式。
如果只是想指定时间之后执行,使用time.Sleep()
使用NewTimer(),可以返回的Timer类型在计时器到期之前,取消该计时器
直到使用<-timer.C发送一个值,该计时器才会过期
定义计数器
timer := time.NewTimer(time.Second * 2)
停止定时器
timer.Stop()
强制的修改timer中规定的时间
timer.Reset(0)
package main
func main() {
d := time.Duration(time.Second*2)
t := time.NewTimer(d)
defer t.Stop()
for {
<- t.C
fmt.Println("timeout...")
// need reset
t.Reset(time.Second*2)
}
}
output:
timeout…
timeout…
timeout…
使用timer定时器,超时后需要重置,才能继续触发。
ticker只要定义完成,从此刻开始计时,不需要任何其他的操作,每隔固定时间都会触发。
func main() {
d := time.Duration(time.Second*2)
t := time.NewTicker(d)
defer t.Stop()
for {
<- t.C
fmt.Println("timeout...")
}
}
输出: output:
timeout…
timeout…
timeout…
————————————————
原文链接:https://blog.csdn.net/lanyang123456/article/details/79794183
1.17 beego.AppConfig.String取不出默认配置的值
今天在运行新开发的beego工程发现使用beego.AppConfig.String取不出配置的值。下面说一下解决思路:
beego会默认加载 app.conf
由于beego会默认加载app.conf的配置,所以首先想到的是beego在何时加载默认配置。研究发现代码是在启动时就去加载默认配置的。所以在我使用前一定以及加载过默认配置。所以换一个思路。
beego加载默认app.conf的路径是什么
源码如下:
func init() {
BConfig = newBConfig()
var err error
if AppPath, err = filepath.Abs(filepath.Dir(os.Args[0])); err != nil {
panic(err)
}
workPath, err := os.Getwd()
if err != nil {
panic(err)
}
appConfigPath = filepath.Join(workPath, "conf", "app.conf")
if !utils.FileExists(appConfigPath) {
appConfigPath = filepath.Join(AppPath, "conf", "app.conf")
if !utils.FileExists(appConfigPath) {
AppConfig = &beegoAppConfig{innerConfig: config.NewFakeConfig()}
return
}
}
if err = parseConfig(appConfigPath); err != nil {
panic(err)
}
if err = os.Chdir(AppPath); err != nil {
panic(err)
}
}
上面可以看出,beego默认会从workPath或者AppPath处获取默认配置。所以就将这两个路径打印出来发现对应的路径下没有app.conf
打印出来的值如下******/gomodule/bin,默认的路径是app的启动路径。而使用默认参数go install编译出来的二进制文件在$GOPATH/bin下。那么思路很简单啦。
将编译好的二进制文件移到app所在的目录下就可以了,一般为$GOPATH/src/appname/下即可。
————————————————
原文链接:https://blog.csdn.net/zqz_qizheng/article/details/58608026
1.18 Golang-使用goconfig 读取配置文件
使用goconfig 读取ini 配置文件
1.18.1 安装
go get github.com/Unknwon/goconfig
1.18.2 使用方法
1.18.2.1 加载配置文件
cfg, err := goconfig.LoadConfigFile("conf.ini")
if err != nil{
panic("错误")
}
[mysql]
username=root
password=123456
url=(127.0.0.1:3306)/baidu
[redis]
address=127.0.0.1:6379
1.18.2.2 读取
1.18.2.2.1 读取单个值
value, err := cfg.GetValue("mysql", "username")
valut, err := cfg.Int("must", int)
1.18.2.2.2 读取整个区
sec err :== Cfg.GeSecion("mysql")
1.18.3 其他API
API 文档
http://gowalker.org/github.com/Unknwon/goconfig
1.19 beego注解路由中各个参数解释
beego注解路由的注释,我们可以把我们的注释分为以下类别:
@Title:接口的标题,用来标示唯一性,唯一,可选
格式:之后跟一个描述字符串
@Description:接口的作用,用来描述接口的用途,唯一,可选
格式:之后跟一个描述字符串
@Param:请求的参数,用来描述接受的参数,多个,可选
格式:变量名 传输类型 类型 是否必须 描述
传输类型:paht or body
类型:
变量名和描述是一个字符串
是否必须:true 或者false
o string
o int
o int64
o 对象,这个地方大家写的时候需要注意,需要是相对于当前项目的路径.对象,例如models.Object表示models目录下的Object对象,这样bee在生成文档的时候会去扫描改对象并显示给用户改对象。
o query 表示带在url串里面?aa=bb&cc=dd
o form 表示使用表单递交数据
o path 表示URL串中得字符,例如/user/{uid} 那么uid就是一个path类型的参数
o body 表示使用raw body进行数据的传输
o header 表示通过header进行数据的传输
@Success:成功返回的code和对象或者信息
格式:code 对象类型 信息或者对象路径
code:表示HTTP的标准status code,200 201等
对象类型:{object}表示对象,其他默认都认为是字符类型,会显示第三个参数给用户,如果是{object}类型,那么就会去扫描改对象,并显示给用
对象路径和上面Param中得对象类型一样,使用路径.对象的方式来描述
@Failure:错误返回的信息,
格式: code 信息
code:同上Success
错误信息:字符串描述信息
@router:上面已经描述过支持两个参数,第一个是路由,第二个表示支持的HTTP方法
// @Title /bills
// @Description 返回全量费用数据
// @Param beginTime query string false "beginTime"
// @Param endTime query string false "endTime"
// @Param limit query int false "限制一次返回的数据条目"
// @Param offset query int false "偏移量"
// @Success 200 {object} models.AllBillInfo
// @Failure 404 wrong params
// @router / [get]
链接:https://juejin.im/post/5c2dcf85e51d4542d8477656
1.20 关于golang.org/x包问题
由于谷歌被墙,跟谷歌相关的模块无法通过go get来下载
解决方法:
git clone https://github.com/golang/net.git $GOPATH/src/github.com/golang/net
git clone https://github.com/golang/sys.git $GOPATH/src/github.com/golang/sys
git clone https://github.com/golang/tools.git $GOPATH/src/github.com/golang/tools
ln -s $GOPATH/src/github.com/golang $GOPATH/src/golang.org/x
· 如果是Windows下,最后一条可以替换为mklink命令,或者直接拷贝文件夹修改一下名称即可。
go的官方包都在这个目录下:https://github.com/golang
原文地址:https://studygolang.com/articles/7087
1.21 Strings方法
1.22 golang go:linkname 的使用
由于go是按照首字母大小写决定是否可以被外部包引用的。所以,如果我们想方位某个包中的私有成员,就需要用到go:linkname了,也就是说我们可以通过 //go:linkname localname linkname 这种方式将本地的私有函数/变量,提供给外部使用。但是经过试验,常量是不可以的。同时还有一个 //go:nosplit 在源码中也是经常出现的,其实就是告诉编译器,下面的函数不会产生堆栈溢出,不需要插入堆栈溢出检查。
具体的使用有大致有两种
- 通过 //go:linkname localname linkname 将函数 localname 连接到 当前包(a),然后在使用的时候(b)同样需要 通过此命令连接到之前的符号。也就是 a.go 在函数上加 //go:linkname say a.say 此时无论使用方采用首字母大写关联还是小写进行管理,均不能直接使用之后 b.go 中
//go:linkname sayTest a.say
func sayTest(name string) string
func Greet(name string) string {
return sayTest(name)
}
1.23 os.Open()和os.OpenFile()
一直以来都以为Open()和OpenFile()没有什么大的区别,今天操作日志文件才发现,两者有很大的区别。
这是我刚开始写的代码:
logFile,err:=os.Open("log/system.txt")
if err!=nil{
log.Fatalln("读取日志文件失败",err)
}
defer logFile.Close()
logger:=log.New(logFile,"\r\n",log.Ldate|log.Ltime)
logger.Print("hello")
发现怎么都不能往system.txt文件中写入hello字符串,改了一下:
logFile,err:=os.OpenFile("log/system.txt",os.O_RDWR|os.O_CREATE,0)
if err!=nil{
log.Fatalln("读取日志文件失败",err)
}
defer logFile.Close()
logger=log.New(logFile,"\r\n",log.Ldate|log.Ltime)
这样就可以了,查了一下标准文档,原因如下:
Open打开一个文件用于读取。如果操作成功,返回的文件对象的方法可用于读取数据;对应的文件描述符具有O_RDONLY模式。如果出错,错误底层类型是*PathError。
所以,Open()只能用于读取文件。
原文链接:https://blog.csdn.net/u013025612/article/details/47981461
1.24 Golang中几种字符串链接方式
来源于:https://segmentfault.com/a/1190000012978989
最近在做性能优化,有个函数里面的耗时特别长,看里面的操作大多是一些字符串拼接的操作,而字符串拼接在 golang 里面其实有很多种实现。
1.24.1 实现方法
1.24.1.1 1. 直接使用运算符
func BenchmarkAddStringWithOperator(b *testing.B) {
hello := “hello”
world := “world”
for i := 0; i < b.N; i++ {
_ = hello + “,” + world
}
}
func BenchmarkAddMoreStringWithOperator(b *testing.B) {
hello := “hello”
world := “world”
for i := 0; i < b.N; i++ {
var str string
for i := 0; i < 100; i++ {
str += hello + “,” + world
}
}
}
golang 里面的字符串都是不可变的,每次运算都会产生一个新的字符串,所以会产生很多临时的无用的字符串,不仅没有用,还会给 gc 带来额外的负担,所以性能比较差
1.24.1.2 2. fmt.Sprintf()
func BenchmarkAddStringWithSprintf(b *testing.B) {
hello := “hello”
world := “world”
for i := 0; i < b.N; i++ {
_ = fmt.Sprintf("%s,%s", hello, world)
}
}
内部使用 []byte 实现,不像直接运算符这种会产生很多临时的字符串,但是内部的逻辑比较复杂,有很多额外的判断,还用到了 interface,所以性能也不是很好
1.24.1.3 3. strings.Join()
func BenchmarkAddStringWithJoin(b *testing.B) {
hello := “hello”
world := “world”
for i := 0; i < b.N; i++ {
_ = strings.Join([]string{hello, world}, “,”)
}
}
join会先根据字符串数组的内容,计算出一个拼接之后的长度,然后申请对应大小的内存,一个一个字符串填入,在已有一个数组的情况下,这种效率会很高,但是本来没有,去构造这个数据的代价也不小
1.24.1.4 4. buffer.WriteString()
func BenchmarkAddStringWithBuffer(b *testing.B) {
hello := “hello”
world := “world”
for i := 0; i < b.N; i++ {
var buffer bytes.Buffer
buffer.WriteString(hello)
buffer.WriteString(",")
buffer.WriteString(world)
_ = buffer.String()
}
}
func BenchmarkAddMoreStringWithBuffer(b *testing.B) {
hello := “hello”
world := “world”
for i := 0; i < b.N; i++ {
var buffer bytes.Buffer
for i := 0; i < 100; i++ {
buffer.WriteString(hello)
buffer.WriteString(",")
buffer.WriteString(world)
}
_ = buffer.String()
}
}
这个比较理想,可以当成可变字符使用,对内存的增长也有优化,如果能预估字符串的长度,还可以用 buffer.Grow() 接口来设置 capacity
1.24.2 测试结果
BenchmarkAddStringWithOperator-8 50000000 28.4 ns/op 0 B/op 0 allocs/op
BenchmarkAddStringWithSprintf-8 10000000 234 ns/op 48 B/op 3 allocs/op
BenchmarkAddStringWithJoin-8 30000000 56.2 ns/op 16 B/op 1 allocs/op
BenchmarkAddStringWithBuffer-8 20000000 86.0 ns/op 112 B/op 1 allocs/op
BenchmarkAddMoreStringWithOperator-8 100000 14295 ns/op 58896 B/op 100 allocs/op
BenchmarkAddMoreStringWithBuffer-8 300000 4551 ns/op 5728 B/op 7 allocs/op
这个是在我的自己 Mac 上面跑的结果,go 版本 go version go1.8 darwin/amd64,这个结果仅供参考,还是要以实际生产环境的值为准,代码在:https://github.com/hatlonely/…
1.24.3 主要结论
-
在已有字符串数组的场合,使用 strings.Join() 能有比较好的性能 -
在一些性能要求较高的场合,尽量使用 buffer.WriteString() 以获得更好的性能 -
较少字符串连接的场景下性能最好,而且代码更简短清晰,可读性更好 -
如果需要拼接的不仅仅是字符串,还有数字之类的其他需求的话,可以考虑 fmt.Sprintf
1.24.4 参考链接
go语言字符串拼接性能分析: http://herman.asia/efficient-…
1.25 golang package log学习
日志是程序中必不可少的部分,golang的日志包log相当简洁明了。
1.25.1 函数
log包主要有以下三个系列的函数
// Print calls Output to print to the standard logger.
// Arguments are handled in the manner of fmt.Print.
func Print(v ...interface{}) {
std.Output(2, fmt.Sprint(v...))
}
// Fatal is equivalent to Print() followed by a call to os.Exit(1).
func Fatal(v ...interface{}) {
std.Output(2, fmt.Sprint(v...))
os.Exit(1)
}
// Panic is equivalent to Print() followed by a call to panic().
func Panic(v ...interface{}) {
s := fmt.Sprint(v...)
std.Output(2, s)
panic(s)
}
Print系列:相当与直接输出日志
Fatal系列:输出日志后退出程序
Panic系列: 输出日志后终止程序原有的流程,逐层往上执行panic
还有以下两个函数对日志输出格式进行设置
// SetPrefix sets the output prefix for the standard logger.
func SetPrefix(prefix string) {
std.SetPrefix(prefix)
}
// SetFlags sets the output flags for the standard logger.
func SetFlags(flag int) {
std.SetFlags(flag)
}
· SetPrefix:设置日志的前缀
· SetFlags:设置日志输出的抬头信息
常量
const (
Ldate = 1 << iota // 日期 the date in the local time zone: 2009/01/23
Ltime // 时间 the time in the local time zone: 01:23:23
Lmicroseconds // 毫秒 microsecond resolution: 01:23:23.123123. assumes Ltime.
Llongfile // 绝对路径和行号 full file name and line number: /a/b/c/d.go:23
Lshortfile // 文件和行号 final file name element and line number: d.go:23. overrides Llongfile
LUTC // 转换时区 if Ldate or Ltime is set, use UTC rather than the local time zone
LstdFlags = Ldate | Ltime // 标准日志抬头信息 initial values for the standard logger
)
1.25.2 实例
运行上面例子的代码会输出以下内容
TEST LOG 2018/03/25 22:00:53 log.go:14: Hello Golang
TEST LOG 2018/03/25 22:00:53 log.go:14: Hello Python
注:我们一般会把日志的初始化放在init函数中,golang在执行main函数之前会执行init函数
1.25.3 如何定制我们项目日志
实际开发过程中,我们都会把程序的日志记录在文件中,而不是直接在终端中输出,log包中的New函数可以创建一个新的记录器,定制我们的日志
运行上面程序后,在当前目录下会生成test.log文件,且文件记录了我们写进去日志
你是不是也觉得官方的日志处理包log没有进行很好的封装,用起来总有那么一点不顺手或者憋屈,没关系,github上有一个日志处理包go-logging,肯定是你的菜,看看官方的例子
输出如下(还有颜色喔…)
原文链接:https://blog.csdn.net/luckytanggu/article/details/79692106
而fabric的日志系统主要使用了第三方包go-logging,很少一部分使用了go语言标准库中的log。在此基础上fabric自己封装出来了flogging。
在fabric v1.0中,代码集中在fabric/common/flogging目录下;在fabric v0.6中, 代码集中在fabric/flogging目录下;两个版本的flogging都供项目全局使用。
主要用到的函数:
原文链接:https://blog.csdn.net/code_segment/article/details/77500445
1.26 golang中字符串MD5生成方式
1.26.1.1 方案一
func md5V(str string) string {
h := md5.New()
h.Write([]byte(str))
return hex.EncodeToString(h.Sum(nil))
}
1.26.1.2 方案二
func md5V2(str string) string {
data := []byte(str)
has := md5.Sum(data)
md5str := fmt.Sprintf("%x", has)
return md5str
}
1.26.1.3 方案三
func md5V3(str string) string {
w := md5.New()
io.WriteString(w, str)
md5str := fmt.Sprintf("%x", w.Sum(nil))
return md5str
}
1.26.1.4 整体测试代码
package main
import (
“crypto/md5”
“encoding/hex”
“fmt”
“io”
)
func main() {
str := “MD5testing”
md5Str := md5V(str)
fmt.Println(md5Str)
fmt.Println(md5V2(str))
fmt.Println(md5V3(str))
}
// 输出结果:
f7bb96d1dcd6cfe0e5ce1f03e35f84bf
f7bb96d1dcd6cfe0e5ce1f03e35f84bf
f7bb96d1dcd6cfe0e5ce1f03e35f84bf
链接:https://www.jianshu.com/p/58dcbf490ef3
1.27 Goland常用快捷键
1.27.1 光标定位
Ctrl + Alt + 左右 跳转到上一个光标处。
来源于:https://blog.csdn.net/metheir/article/details/81807516
1.27.2 文件相关快捷键
CTRL+E,打开最近浏览过的文件。
CTRL+SHIFT+E,打开最近更改的文件。
CTRL+N,可以快速打开struct结构体。
CTRL+SHIFT+N,可以快速打开文件。
1.27.3 代码格式化
CTRL+ALT+T,可以把代码包在一个块内,例如if{…}else{…}。
CTRL+ALT+L,格式化代码。
CTRL+空格,代码提示。
CTRL+/,单行注释。CTRL+SHIFT+/,进行多行注释。
CTRL+B,快速打开光标处的结构体或方法(跳转到定义处)。
CTRL+“+/-”,可以将当前方法进行展开或折叠。
1.27.4 查找和定位
CTRL+R,替换文本。
CTRL+F,查找文本。
CTRL+SHIFT+F,进行全局查找。
CTRL+G,快速定位到某行。
1.27.5 代码编辑
ALT+Q,可以看到当前方法的声明。
CTRL+Backspace,按单词进行删除。
SHIFT+ENTER,可以向下插入新行,即使光标在当前行的中间。
CTRL+X,删除当前光标所在行。
CTRL+D,复制当前光标所在行。
ALT+SHIFT+UP/DOWN,可以将光标所在行的代码上下移动。
CTRL+SHIFT+U,可以将选中内容进行大小写转化。
————————————————
原文链接:https://blog.csdn.net/benben_2015/article/details/78813670
1.28 Panic和recover
1.28.1 Panic
Panic(err)
建议除非必要环节,否则不建议使用panic。
The panic built-in function stops normal execution of the current goroutine. When a function F calls panic, normal execution of F stops immediately. Any functions whose execution was deferred by F are run in the usual way, and then F returns to its caller. To the caller G, the invocation of F then behaves like a call to panic, terminating G’s execution and running any deferred functions. This continues until all functions in the executing goroutine have stopped, in reverse order. At that point, the program is terminated with a non-zero exit code. This termination sequence is called panicking and can be controlled by the built-in function recover.
panic内置函数停止当前goroutine的正常执行。当函数F调用时,F的正常执行立即停止。以通常的方式运行,然后返回到其调用方。对调用者G而言,F的调用就像调用panic一样,终止G的执行并运行任何延迟的函数。过去以相反的顺序继续使用它。此时,程序将以非零退出代码终止。此终止序列称为panicking,可以通过内置的功能restore控制。
1.28.2 Recover
The recover built-in function allows a program to manage behavior of a panicking goroutine. Executing a call to recover inside a deferred function (but not any function called by it) stops the panicking sequence by restoring normal execution and retrieves the error value passed to the call of panic. If recover is called outside the deferred function it will not stop a panicking sequence. In this case, or when the goroutine is not panicking, or if the argument supplied to panic was nil, recover returns nil. Thus the return value from recover reports whether the goroutine is panicking.
恢复内置功能允许程序管理紧急恐慌例程的行为。在延迟函数中执行恢复调用。如果在延迟函数之外调用了restore,它将不会在恐慌序列中停止。在这种情况下,当goroutine不惊慌时,或者如果提供给panic的参数为nil,则restore返回nil。因此,恢复报告的返回值。