01 小样本学习 概述
一、前言
小样本学习(Few-Shot Learning)是近几年兴起的一个研究领域,小样本学习旨在解决在数据有限的机器学习任务[参考]。
1.1 小样本学习存在的意义?
近些年,以深度卷积神经网络为代表的深度学习方法在各类机器学习任务上取得了优异的成绩——很多任务上已经超越了人类表现。狂欢背后,危机四伏。因为这些深度学习方法work的关键之一是海量标注数据的支持。
但是在工业界,很多时候难以获得海量的训练数据,更别提还要标注了。这里我脑洞一下:不久的将来,深度学习会沦为高科技公司和大型科研机构的专属玩具——因为小公司、小科研机构根本无法接触到高品质的、海量的数据。那么,有没有一种方法可以让我们只需要少量的样本,就能训练出良好的模型呢?于是,小样本学习就登上了历史舞台。
实际上,我们人类就比较擅长小样本学习。给人几张不同角度的图片,人就可以对新的图片进行分辨——这种强大的学习能力恰恰是当前深度学习所缺乏的,也是鼓舞我们探索的动力所在。
1.2 什么是小样本学习?
这里给出小样本学习的严格定义,在介绍小样本学习之前,我们先看机器学习的定义。
Machine Learing : A computer program is said to learn from experience E with respect to some classes of task T and performance measure P, if its performance can improve with E on T measured by P.
然后我们引入小样本学习的定义。
Few-Shot Learning (FSL) : A type of machine learning problems (specified by E,T and P), where E contains only a limited number of examples with supervised information for the target T.
- 机器学习就是从数据中学习,从而使完成任务的表现越来越好;
- 小样本学习是具有有限监督数据的机器学习;
- 弱监督学习是强调在不完整、不准确、有噪声、数据少的数据上学习;
- 半监督学习是强调在少量标注数据和大量非标注数据上学习;
- 迁移学习是把充足数据上学习的知识迁移到数据匮乏的任务上。
1.3 小样本学习的方法有哪些?
如果把小样本学习比作一个黑盒子,给这个黑盒子喂少量的数据,凭什么能让它表现得好呢?显然我们需要外力来帮助,这个外力就是“先验知识”。
小样本学习的先验知识来自三方面:数据、模型、算法,小样本学习的研究也都是从这三方面着手。因此,小样本学习方法大致可分为基于数据增强的方法、基于模型改进的方法、基于算法优化的方法。
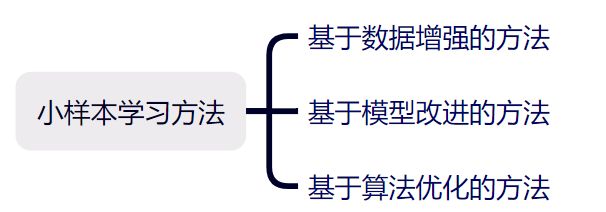
1.3.1 基于数据增强的方法
主要思路就是数据增强,通俗地讲就是扩充样本。想到数据增强,我们通常会想到平移、裁剪、翻转、加噪声等操作,但是这些操作可能在特定数据集表现很好,不具有普适性。而且设计这些操作需要对所处理的领域具有足够的了解。小样本学习所使用的数据增强方法主要有三个思路:
1)只有小样本数据集:可以训练一个transformer学习样本之间的变化,然后使用该transformer对小样本数据集进行扩充;
2)有小样本数据集+弱标注数据集:可以训练transformer从弱标注数据集中“挑选”样本来扩充小样本数据集;
3)有小样本数据集+相似的数据集:可以训练一个GAN网络,通过学习给小样本数据集加上扰动来生成新样本。
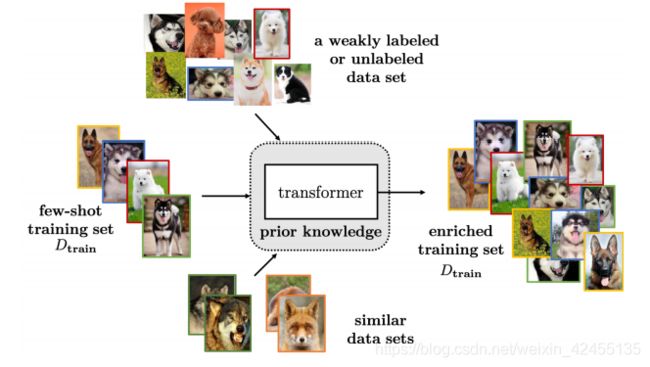
基于数据的方法比较容易理解,但是存在的问题是:很多工作都不具备普适性,难以迁移到别的数据集。
1.3.2 基于模型改进的方法
每个模型经过迭代都会得到近似解,而当样本有限时,在假设空间搜索解就变得困难。这类方法为了缩小假设空间,主要有四种方法:
1.多任务学习(Multitask Learning):这种模型可以处理多个任务,因此也就兼备了模型的普适性和一般性。在处理多个任务时,模型的参数可以是共享的,也可以是相关联的;
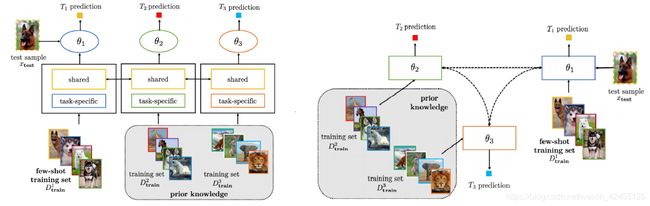
多任务学习共享参数(左)、关联参数(右)模型示意图
2.嵌入学习(Embedding Learning):将样本映射到一个低维度空间,从而达到了缩小假设空间的效果,然后就可以通过少量的样本求出模型在该假设空间下的近似解。根据映射到低维空间的方法又分为三类:任务特定型(结合任务的具体特点进行映射)、通用型、结合型(结合任务和通用);
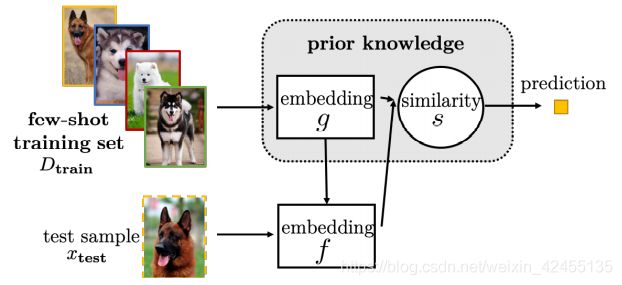
嵌入学习模型示意图
3.基于外部记忆的学习(Learning with External Memory):通过对小样本数据集学习得到知识,然后存储到外部,对于新样本,都使用存储在外部的知识进行表示,并根据表示来完成匹配。这种方法大大降低假设空间;
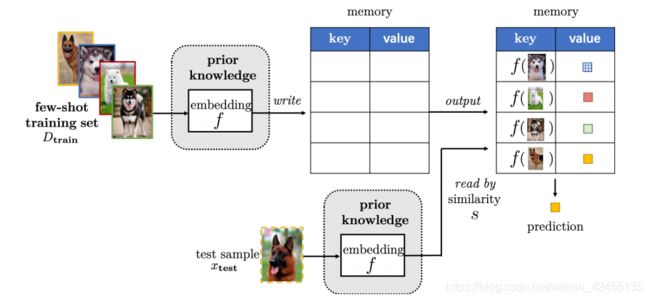
基于外部记忆的学习模型示意图
4.生成模型(Generative Modeling):生成模型学习小样本数据集的数据分布,并可将其用于各种任务。
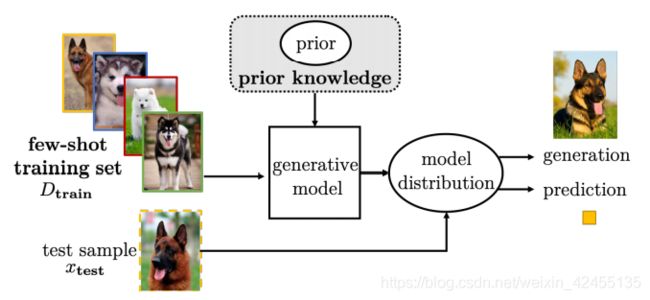
生成模型模型示意图
1.3.3 基于算法优化的方法
这类方法的核心是通过改进优化算法来更快地搜索到合适解。主要方法有三种:
1.改善已有参数。这种方法从参数初始化的角度着手,主要思路是借助已训练好的模型参数来调整小样本模型的参数,例如:在大数据集训练好模型来初始化小样本模型;聚合其他已训练好的模型到一个模型;给已训练好的模型加一些特用于小样本任务的参数;等等。
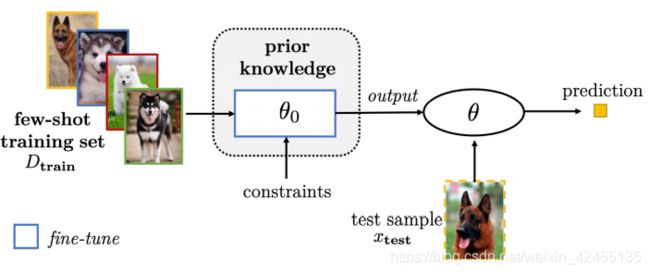
改善模型已有参数流程示意图
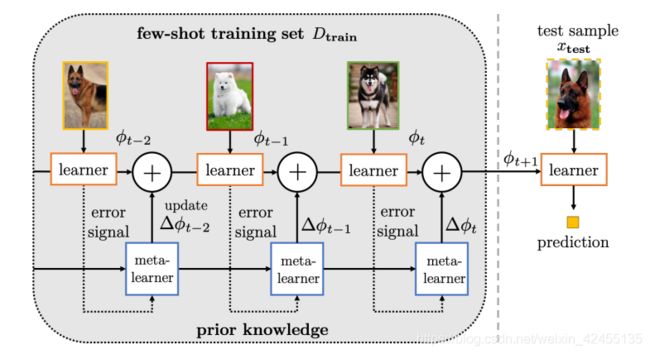
2.改善元学习参数。元学习(meta-learning)是当下很火的一个研究方向,它的思想是学习如何学习。它的结构一般是由一个底层模型和一个顶层模型组成,底层模型是model的主体,顶层模型是meta-learner。更新参数时,它除了要更新底层model,还要更新meta参数。改善策略大致有三类:
1)结合不同特定任务模型参数来对新任务的参数进行初始化;
2)对模型不确定性建模,以备后续提升;
3)改进参数调整流程。

改善元学习参数流程示意图
3.学习优化器。如下图所示,optimizer每次都迭代会更新上一次的模型参数,现在通过学习小样本数据集中每个迭代的更新值,从而应用在新的测试数据上。
学习优化器流程示意图
结语
小样本学习是机器学习领域未来很有前景的一个发展方向,它要解决的问题很有挑战性、也很有意义。小样本学习中最重要的一点就是先验知识的利用,如果我们妥善解决了先验知识的利用,能够做到很好的迁移性,想必那时我们距离通用AI也不远了。
参考文献
Y. Wang, J. Kwok, L. M. Ni and Q. Yao, "Generalizing from a few examples: A survey on few-shot learning", arXiv:1904.05046, 2019