【前端】-【node.js基础】-学习笔记
【前端】-【node.js】-学习笔记
- 1 node.js介绍
-
- 1.1 node.js优点
- 1.2 node.js 不足之处
- 1.3 nodejs与java的区别
- 2. node中函数
- 3. 浏览器和node
- 4. Buffer缓冲器
-
- 4.1 Buffer是什么
- 4.2 Buffer的特点
- 3 node中的文件写入操作
-
- 3.1 简单文件写入
- 3.2 流式文件写入
- 4 node中的文件读取操作
-
- 4.1 简单文件读取
- 4.2流式文件读取
- 5 node.js原生服务器
1 node.js介绍
node.js不是编程语言
也不是框架和库
node.js是基于Chrome V8 JavaScript 引擎之上的 JavaScript 运行环境
写js=>翻译成c/c++

1.1 node.js优点
I/O操作
- input:写, output:读(文件)
- input:写, output:读(数据库)
node.js优点
- 异步非阻塞的I/O (I/O线程池) =》读取数据的时候,可以进行其他操作
- 特别适用于I/O密集型应用=》频繁操作I/O
- 事件循环机制=》独有的一和套,和浏览器不一样
- 单线程(成也单线程,败也单线程)
- 跨平台
1.2 node.js 不足之处
- 回调函数嵌套太多、太深(俗称回调地狱)
- 单线程,处理不好cpu密集型任务
web交互模型:

1.3 nodejs与java的区别
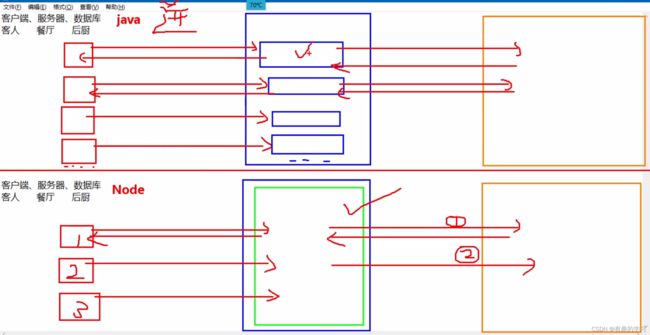
大厂用的是java,node.js能很好的解决I/O密集型,但是比较怕CPU密集型
1)、Node.js比Java更快 :
node.js开发快,运行的效率也算比较高,但是如果项目大了就容易乱,而且javascript不是静态类型的语言,要到运行时才知道类型错误,所以写的多了之后免不了会出现光知道有错但是找不到哪儿错的情况,所以测试就得些的更好更详细。
java开发慢,但是如果项目大、复杂的话,用java就不容易乱,管理起来比node.js省。
2)、Node.js 前后端都采用Javascript,代表未来发展的趋势,而java则是现在的最流行的服务器端编程语言。
3)、Node.js和Java EE——一种是解释语言,一种是编译语言.
Node.js解决问题的速度比Java EE快20%,一种解释语言和一种编译语言在一个VM中的速度是一样快的,这没有多年的优化过程是绝对达不到的。
4)、Java是一种编程语言,而NodeJS是用C,C ++编写的基于 Chrome V8 引擎的 JavaScript 运行环境。
5)、Java严格来说是一种与浏览器无关的服务器端语言,而Node JS可以在客户端和服务器端有效地使用。
2. node中函数
- Node中任何一个模块(js文件)都被一个外层函数所包裹
function (exports,require,module,__filename,__dirname){ ...}
exports:用于支持commonjs模块化暴露语法
require:用于支持commonjs模块化规范的引入语法
module:用于支持commonjs模块化暴露语法
__filename:当前运行文件的绝对路径
__dirname:当前运行文件所在文件夹的绝对路径
- 为什么要设计这种外层函数(这个外层函数有什么用)?
1)用于支持模块化语法
2)隐藏服务器内部实现(从作用域角度去看)
3. 浏览器和node
1.浏览器端,js由那几部分组成?
- BOM---->window浏览器对象模型----->很多API(location,history)
- DOM----->document文档对象模型------>很多API(对DOM增删改查)
- ES规范-------------------ES5、ES6
2.Node端,js由那几部分组成?
- 没有BOM---->因为服务器不需要(服务器没有浏览器对象)
- 没有DOM----->因为没有浏览器窗口
- 几乎包含了所有的ES规范
- 没有了window,但是取而代之是一个叫做global的全局变量
3.node中的事件循环模型(了解即可)
clearImmediate:清空立即执行函数
clearInterval:清除循环定时器
clearTimeout: 清除延迟定时器
setImmediate:设置立即执行函数
setInterval:设置循环定时器
setTimeout: 设置延迟定时器
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
各阶段概览
————————————————
第一阶段: timers (定时器阶段–setTimeout,setInterval):
·1.开始计时
·2执行定时器回调
第二阶段: pending callbacks(系统阶段)
第三阶段:idle, prepare, (准备阶段)
第四阶段:poll(轮询阶段,核心#)
- 如果回调队列中有待执行的回调函数:
从回调队列中取出回调函数,同步执行(一个一个执行),直到回调队列为空了,或者达到系统最大限度 - 如果回调队列为空:
- 如果设置过setImmediate
进入下一个check阶段,目的:为了执行setImmediate所设置的回调
- 如果未设置setImmediate
在此阶段停留,等待回调函数被插入回调队列
若定时器到点了,进入下一个check阶段,原因:为了走第五阶段,随后走第六阶段,随后第一阶段(最终目的)
第五阶段:check(专门用于执行 setImmediate所设置的回调)
第六阶段:close callbacks
process.nextTick() -------用于设置立即执行函数(“VIP”------能在任意阶段优先执行,除了主线程)
————————————————
4. Buffer缓冲器
4.1 Buffer是什么
Buffer是一个和【数组类似】的对象,不同的是Buffer是专门用于保存二进制数据的
B
4.2 Buffer的特点
1)大小固定:创建时大小就确定,且无法调整
2)性能好:存储和读取很快,直接对计算机的内存进行操作
3)每个元素大小为1字节(byte)
4) 是Node中非常核心的模块,无需下载,无需引入,直接即可使用
创建一个Buffer的实例对象----性能特别差
1.在堆里开辟空间
2.清理
let buf =new Buffer(10) console.log(buf2)
创建一个Buffer的实例对象----性能比new Buffer()稍微好一点
在堆里开辟一个空间(该空间没有人用过)
let buf2=Buffer.alloc(10)
创建一个Buffer的实例对象----性能最好
在堆里开辟空间
let buf3 = Buffer.alllocUnsafe(10)
前两个用的比较多
- 输出的
Buffer为什么不是2进制?
输出的是16进制,但是存储的是2进制,输出的时候自动转成16进制
alllocUnsafe输出的Buffer为啥不为空?
在堆里开辟空间,可能残留别人用过的数据,所以allocUnsafe
将数据存入一个Buffer实例
let buf4 =Buffer.from('hello world')
console.log(buf4) # 输出的是16进制
console.log(buf4.toString()) # 输出的是hello world
h是1字节,e是1字节
进制相关:
十六进制:00-ff
二进制:00000000-11111111
计算机单位:
8位(bit)=1字节(Byte)
1024Byte=1kb
3 node中的文件写入操作
3.1 简单文件写入
1.Node中的文件系统:
- 在NodeJS中有一个文化系统,就是对计算机中的文件进行增删改查等操作
- 在NodeJS中,给我们提供了一个模块,叫做fs模块(文件系统),专门用于操作文件
- fs模块是Node的核心模块,使用时无需下载,直接引入
2.异步文件写入(简单文件写入)
fs.writeFile(file,data[,options],callback)
----file:要写入的文件路径+文件名
----data:要写入的数据
----options:可选参数
---------encoding:设置文件的编码方式,默认是utf8
---------mode:设置文件的操作权限,默认是0o666=0o222+0o444,可选0o111(可执行,例如.exe .msc,几乎不用),0o222(可写入),0o444(可读取)
---------flag:打开文件要执行的操作,默认是‘w’(写),可选‘a’(追加)
----callback:回调函数
---------err:错误对象
# 引入内置的fs模块
let fs = require('fs')
fs.writeFile(__dirname+'./demo.txt','美女',{mode:0o4444,flag:
'a'}(err)=>{
if(err){
console.log('文件写入失败',err)
}else{
console.log('文件写入成功')
}
})
__dirname 动态获取 当前文件模块所属目录的绝对路径
3.2 流式文件写入
蚂蚁搬家,慢慢来,
创建一个可读流 可写流
fs.createWriteStream(path[, options])
-----path:要写入的文件路径+文件名+文件后缀
-----option:配置对象
----------fd:文件统一标识符,linux下文件标识
----------autoClose:自动关闭文件。默认true
----------emitClose:关闭—文件,强制关闭(出现问题)。默认true
----------start:读取文件的起始位置
let fs= require('fs')
# 创建一个可写流
let ws=fs.createWriteStream(__dirname+'./demo.txt')
# 只要用到了流,必须检测流的状态
ws.on('open',function(){
console.log('可写流打开')
})
ws.on('close',function(){
console.log('可写流关闭')
})
# 使用可写流写入数据
ws.write('美女')
ws.end() # 在node的8版本用end关闭
4 node中的文件读取操作
4.1 简单文件读取
fs.readFile(path[,options],callback)
----path:要写入的文件路径+文件名+后缀
----options:可选参数
----callback:回调函数
---------err:错误对象
---------data:读出来的数据
let fs= require('fs')
fs.readFile(__dirname+'./demo.txt',function(err,data)=>{
if(err){
console.log('文件读取失败',err)
}else{
console.log(data)
}
})
为什么读取出来的是Buffer?
用户存储的不一定是纯文本
4.2流式文件读取
创建一个读取流
fs.createReadStream(path[, options])
-----path:要写入的文件路径+文件名+文件后缀
-----option:配置对象
----------fd:文件统一标识符,linux下文件标识
----------autoClose:自动关闭文件。默认true
----------emitClose:关闭—文件,强制关闭(出现问题)。默认true
----------start:起始偏移量
----------end:结束偏移量
----------highWaterMark:每次读取数据的大小,默认64*1024
let fs= require('fs')
# 创建一个可读流
let rs=fs.createWReadStream(__dirname+'./demo.mp4',{highWaterMark:64*1024*1024})
# 只要用到了流,必须检测流的状态
rs.on('open',function(){
console.log('可读流打开')
})
rs.on('close',function(){
console.log('可读流关闭')
})
rs.on('data',function(data){
console.log(data.size)// 输出65536,每次读取64kb大小
})
# 使用可写流写入数据
ws.write('美女')
ws.end() # 在node的8版本用end关闭
5 node.js原生服务器
不借助任何第三方库
#1 引入node内置的http模块
let http=require('http')
//引入一个内置模块,用于解析key=value&key=value这种形式的字符串为js中的对象
//备注:1.形如:key=value&key=value...编码形式:urlencoded编码形式
// 2.请求地址里携带urlencoded编码形式的参数,叫做查询字符串参数
# 引入的qs是一个对象,该对象身上有很多有用的方法,最具代表性的是parse()
let qs=require('querystring')
#2 创建服务器
let server=http.ceateServer(function(request,response){
let params=request.url.split('?')[1];//name=zhangsan&age=18
let objParams = qs.parse(params) //{name:'zhangsan',age:18}
console.log(objParams) {name:'zhangsan',age:'18'}
let {name,age}=objParams
//请求对象request 相应对象response
response.setHeader('content-type','text/html;charset=utf-8') //不需要记
response.end(`<h1>你好${name},你的年龄是${age}<h2>`)
})
#3 指定服务器的端口号
server.listen(3000,function(err){
if(!err) console.log('服务器启动成功!');
else console.log(err);
})
这个node文档不错