Spark第三课
1.分区规则
1.分区规则
shuffle
1.打乱顺序
2.重新组合
1.分区的规则
默认与MapReduce的规则一致,都是按照哈希值取余进行分配.
一个分区可以多个组,一个组的数据必须一个分区
2. 分组的分区导致数据倾斜怎么解决?
- 扩容 让分区变多
- 修改分区规则
3.HashMap扩容为什么必须是2的倍数?
当不是2的倍数时, 好多的位置取不到
比如 为5 01234 123都取不到
必须保证,相关的位数全是1,所以必定2的倍数 2的n次方
所以位运算不是什么时候都能用的

2.转换算子
1.单值转换算子
1.filter过滤器
1.注意
过滤只是将数据进行校验,而不是修改数据. 结果为true就保留,false就丢弃

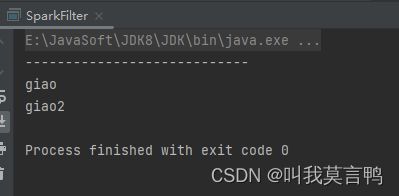
2.代码
JavaSparkContext sc = new JavaSparkContext("local[*]","filter");
List<String> dataList = Arrays.asList("giao","giao2","zhangsan","lisi");
JavaRDD<String> rdd1 = sc.parallelize(dataList);
//JavaRDD rddFilter1 = rdd1.filter(null);
JavaRDD<String> rddFilter2= rdd1.filter(s->s.substring(0,1).toLowerCase().equals("g"));
//rddFilter1.collect().forEach(System.out::println);
System.out.println("----------------------------");
rddFilter2.collect().forEach(System.out::println);
2.dinstinct
1.原理
分组
通过使用分组取重,相同的话,都是一个组了,所以Key唯一
应该是先分组,然后吧K提出来就好了
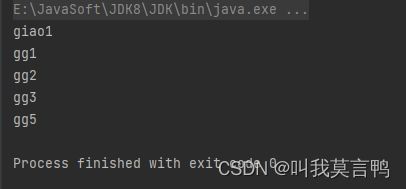
2.代码
JavaSparkContext sc = new JavaSparkContext("local[*]","Distinct");
List<String> dataList = Arrays.asList("giao1","gg1","gg1","gg2","gg2","gg1","gg3","gg1","gg5","gg3");
JavaRDD<String> rdd1 = sc.parallelize(dataList);
JavaRDD<String> rddDistinct = rdd1.distinct();
rddDistinct.collect().forEach(System.out::println);
3.排序
1.介绍
sortby方法需要传3个参数
参数1 排序规则
参数2 升序还是降序(false) 默认升序(true)
参数3 排序的分区数量(说明方法底层是靠shuffle实现,所以才有改变分区的能力)
2.排序规则
排序规则,是按照结果去排序
其实是用结果生成一个K值,通过K值进行排序,然后展示 V值
或者说权值, 按照权值排序
将Value变成K V
3.代码
public static void main(String[] args) {
JavaSparkContext sc = new JavaSparkContext("local[*]","SparkSort");
List<String> dataList = Arrays.asList("kunkun","giaogiao","GSD","JJ","chenzhen","Lixiaolong");
JavaRDD<String> rdd1 = sc.parallelize(dataList);
JavaRDD<String> rddSort = rdd1.sortBy(s -> {
switch (s.substring(0, 1).toLowerCase()) {
case "k":
return 5;
case "g":
return 3;
case "j":
return 1;
case "c":
return 2;
case "l":
return 4;
}
return null;
}, false, 3);
rddSort.collect().forEach(System.out::println);
}
2.键值对转换算子
1.介绍
1.什么是键值对转换算子
如何区分是键值对方法还是单值方法呢?
通过参数来判断, 如果参数是一个值,就是单值,如果是2个,就是键值对
2.元组是不是键值对?
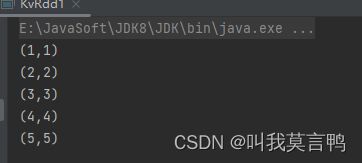
public static void main(String[] args) {
JavaSparkContext sc = new JavaSparkContext("local[*]","KVRDD");
List<Integer> dataList = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> rdd1 = sc.parallelize(dataList);
JavaRDD<Tuple2> rddmap = rdd1.map(num -> new Tuple2(num, num));
rddmap.collect().forEach(System.out::println);
}
答案是,不是,因为这个的返回值,是一个元组,而元组整体,是一个单值,所以,是单值
只有返回值 是RDD
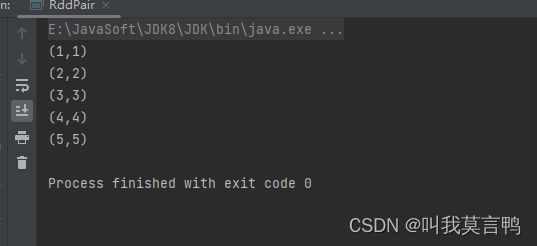
3. 使用Pair转换键值对算子
public static void main(String[] args) {
JavaSparkContext sc = new JavaSparkContext("local[*]","RddPair");
List<Integer> dataList = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> rdd = sc.parallelize(dataList);
JavaPairRDD<Integer, Integer> rddPair = rdd.mapToPair(num -> new Tuple2<>(num, num));
rddPair.collect().forEach(System.out::println);
}
4.直接在获取时转换键值对
这里使用的是parallelizePairs方法 获取的是JavaPairRDD
public static void main(String[] args) {
JavaSparkContext sc = new JavaSparkContext("local[*]","KVRDD");
JavaPairRDD<String, Integer> rddPair = sc.parallelizePairs(Arrays.asList(
new Tuple2<>("a", 1),
new Tuple2<>("a", 2),
new Tuple2<>("b", 1),
new Tuple2<>("b", 1),
new Tuple2<>("c", 2),
new Tuple2<>("c", 1)
));
rddPair.collect().forEach(System.out::println);
}
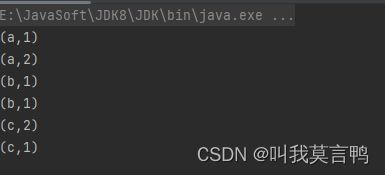
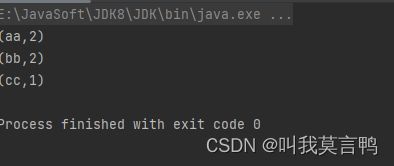
5.分组来获取键值对
```java
public static void main(String[] args) {
JavaSparkContext sc = new JavaSparkContext("local[*]","RddPair");
List<String> dataList = Arrays.asList("aa","bb","aa","bb","cc");
JavaRDD<String> rdd = sc.parallelize(dataList);
JavaPairRDD<Object, Iterable<String>> rddGroup = rdd.groupBy(s->s);
rddGroup.collect().forEach(System.out::println);
}
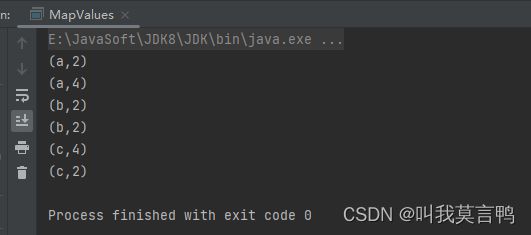
2.mapValue方法
1.介绍
直接对value进行操作,不需要管K
当然,也有mapKey方法可以无视Value操作Key
2.代码演示
public static void main(String[] args) {
JavaSparkContext sc = new JavaSparkContext("local[*]","KVRDD");
JavaPairRDD<String, Integer> rddPair = sc.parallelizePairs(Arrays.asList(
new Tuple2<>("a", 1),
new Tuple2<>("a", 2),
new Tuple2<>("b", 1),
new Tuple2<>("b", 1),
new Tuple2<>("c", 2),
new Tuple2<>("c", 1)
));
JavaPairRDD<String, Integer> mapV = rddPair.mapValues(num -> num * 2);
mapV.collect().forEach(System.out::println);
}
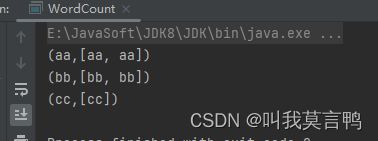
3.WordCount实现
iter.spliterator().estimateSize());
spliterator
Spliterator(Split Iterator)是Java 8引入的一个新接口,用于支持并行遍历和操作数据。它是Iterator的扩展,可以用于在并行流(Parallel Stream)中对数据进行划分和遍历,从而实现更高效的并行处理
spliterator()方法是在Iterable接口中定义的一个默认方法,用于生成一个Spliterator对象,以支持数据的并行遍历。它的具体作用是将Iterable中的数据转换为一个可以在并行流中使用的Spliterator对象。
estimateSize
estimateSize()方法是Java中Spliterator接口的一个方法,用于估算Spliterator所包含的元素数量的大小。Spliterator是用于支持并行遍历和操作数据的接口,而estimateSize()方法提供了一个估计值,用于在处理数据时预测Spliterator包含的元素数量。
public static void main(String[] args) {
JavaSparkContext sc = new JavaSparkContext("local[*]","RddPair");
List<String> dataList = Arrays.asList("aa","bb","aa","bb","cc");
JavaRDD<String> rdd = sc.parallelize(dataList);
JavaPairRDD<Object, Iterable<String>> rddGroup = rdd.groupBy(s->s);
JavaPairRDD<Object, Long> wordCount = rddGroup.mapValues(iter -> iter.spliterator().estimateSize());
wordCount.collect().forEach(System.out::println);
}
3.groupby 与groupByKey
1 .代码
public static void main(String[] args) {
JavaSparkContext sc = new JavaSparkContext("local[*]","G1");
JavaPairRDD<String, Integer> rddPair;
rddPair = sc.parallelizePairs(Arrays.asList(
new Tuple2<>("a", 1),
new Tuple2<>("a", 2),
new Tuple2<>("b", 1),
new Tuple2<>("b", 1),
new Tuple2<>("c", 2),
new Tuple2<>("c", 1)
));
JavaPairRDD<String, Iterable<Integer>> rddGroupByKey = rddPair.groupByKey();
JavaPairRDD<String, Iterable<Tuple2<String, Integer>>> rddGroupBy = rddPair.groupBy(t -> t._1);
rddGroupByKey.collect().forEach(System.out::println);
}
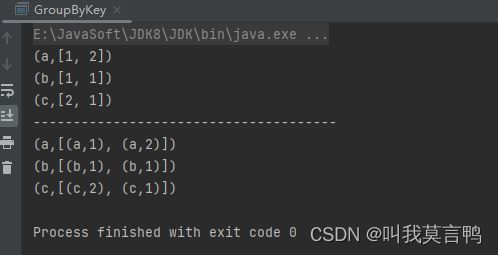
2.分析区别
- 1.参数
GroupBy是自选规则 而GroupByKey是将PairRDD的Key当做分组规则 - 2.结果
GroupBy是将作为单值去分组,即使RDD是Pair, 而GroupByKey 则是将K V分开 ,将V作为组成员
3.注意
GroupByKey是不能进行随意使用的,底层用的含有shuffle,如果计算平均值,就不能通过GroupByKey直接进行计算.
4.reduce与reduceByKey
1.介绍
多个变量进行同样的运算规则
Stream是1.8新特性,
计算的本质 两两结合
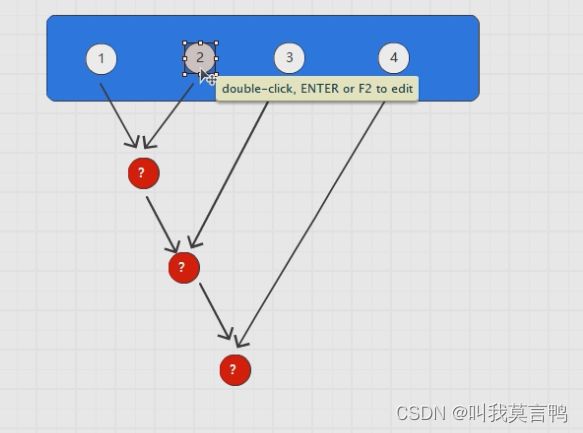
reduce
2. 代码
public static void main(String[] args) {
JavaSparkContext sc = new JavaSparkContext("local[*]","Reduce");
JavaPairRDD<String, Integer> rddPair;
rddPair = sc.parallelizePairs(Arrays.asList(
new Tuple2<>("a", 1),
new Tuple2<>("a", 2),
new Tuple2<>("b", 1),
new Tuple2<>("b", 1),
new Tuple2<>("c", 2),
new Tuple2<>("c", 1)
));
rddPair.reduceByKey(Integer::sum).collect().forEach(System.out::println);
}
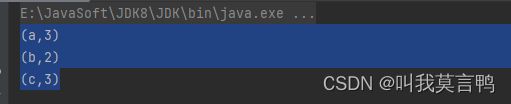
3.理解
相同Key值的V进行运算,所以底层是有分组的,所以底层是一定有Shuffle,一定有改变分区的能力,改变分区数量和分区规则.
4.与groupByKey区别
reduceByKey
将相同key的数量中1的V进行两两聚合
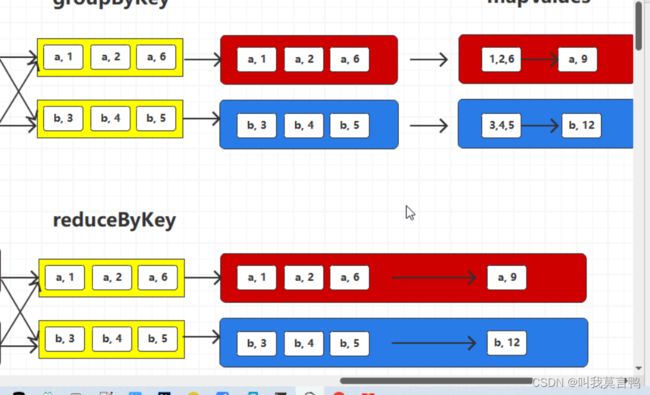
reduceByKey 相同的key两两聚合,在shuffle落盘之前对分区内数据进行聚合,这样会减少落盘数据量,并不会影响最终结果(预聚合) 这就是combine
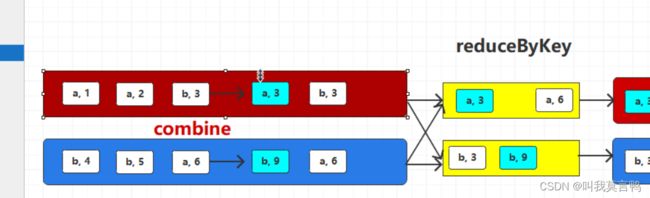
有钱先整IBM小型机
Shuffle优化
1.花钱
2.调大缓冲区(溢出次数减少)
3.
sortByKey
想比较必须实现可比较的接口
默认排序规则为升序,
通过K对键值对进行排序
行动算子
通过调用RDD方法让Spark的功能行动起来

map 是在new

转换算子 得到的是RDD
注意 转换跑不起来 行动能跑起来 这句话是错误的
当使用sort时,也是能跑起来的,但是还是转换算子
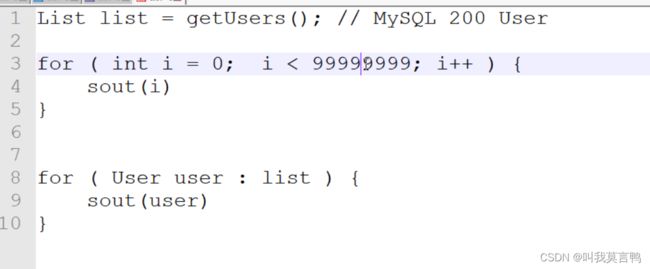
第一行运行占用内存,第一个for 运算需要内存,但是第一行占用了大量内存,所以第一行浪费了,这就需要懒加载,所以第一行的执行时机是在第二个for运行前使用的.
注意map collect 不是懒加载,只是没人调用他的job(RDD算子内部的代码)
RDD算子外部的代码都是在Driver端