【C++进阶之路】map与set的基本使用
文章目录
- 一、set系列
-
- 1.set
-
- ①insert
- ②find
- ③erase
- ④lower_bound与upper_bound
- 2.multiset
-
- ①count
- ②equal_range
- 二、map系列
-
- 1.map
-
- ①insert
-
- 1.插入pair的四种方式
- 2.常用两种方式
- ②[]
- 2.multimap
-
- ①count
- ②equal_range
一、set系列
1.set
①insert
- 函数分析(C++98):

- 简单使用:
set<int> s;
s.insert(5);
s.insert(6);
s.insert(7);
s.insert(9);
s.insert(8);
s.insert(1);
s.insert(2);
s.insert(3);
s.insert(4);
s.insert(4);
s.insert(4);
s.insert(4);
for (auto e : s)
{
cout << e << " ";
}
- 运行结果:

可见:set具有天然的去重和排序功能—— 二叉搜索树的结构
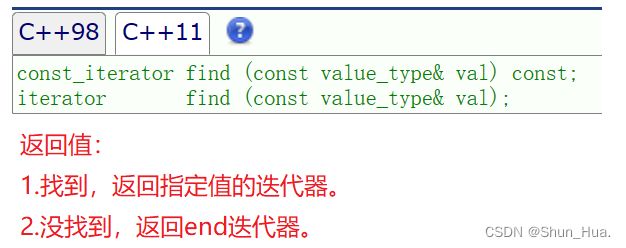
②find
- 函数分析:
- 简单应用:
set<int> s;
s.insert(5);
s.insert(6);
s.insert(7);
s.insert(9);
s.insert(8);
s.insert(1);
s.insert(2);
s.insert(3);
s.insert(4);
set<int>::iterator it = s.find(8);
if (it != s.end())
{
cout << "找到了" << endl;
}
else
{
cout << "没找到" << endl;
}
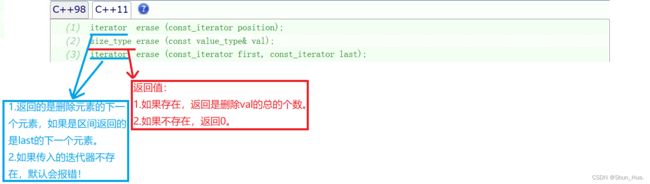
③erase
-
函数分析:
-
简单应用:
set<string> s;
s.insert("张三");
s.insert("李四");
s.insert("王五");
size_t n = s.erase("王五");
cout << n << endl;
set<string>::iterator it = s.find("李四");
if (it != s.end())
{
it = s.erase(it);
if(it != s.end())
cout << *it << endl;
}
- 运行结果:

④lower_bound与upper_bound
- 函数分析

- 简单使用
std::set<int> myset;
std::set<int>::iterator itlow, itup;
for (int i = 1; i < 10; i++)// 10 20 30 40 50 60 70 80 90
myset.insert(i * 10);
for (auto e : myset)
{
cout << e << " ";
}
cout << endl;
itlow = myset.lower_bound(30);
itup = myset.upper_bound(60);
//为了删除[30,60]且符合迭代器区间的左闭右开的规则,因此最终调整为:[30,70)
auto it = myset.erase(itlow, itup);
if(it != myset.end())
cout << *it << endl;
for (auto e : myset)
{
cout << e << " ";
}
- 运行结果

2.multiset
- 基本与set一致,这里介绍几个适合它使用的。
- 强调一点,mutiset可以存相同数据!
①count
-
函数分析

-
简单使用
multiset<int> s;
s.insert(1);
s.insert(1);
s.insert(2);
s.insert(3);
s.insert(4);
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
cout << s.count(1) << endl;
- 运行结果

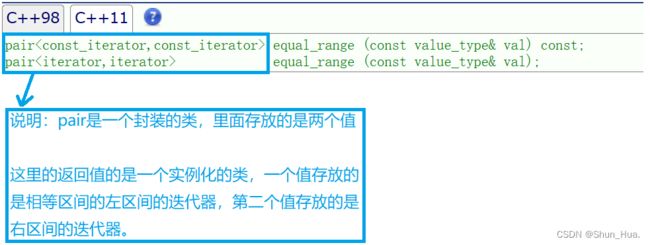
②equal_range
函数分析:
- 简单运用:
multiset<int> s;
s.insert(1);
s.insert(1);
s.insert(1);
s.insert(1);
s.insert(2);
s.insert(3);
s.insert(4);
//pair::iterator, multiset::iterator> it = s.equal_range(1);
auto it = s.equal_range(1);
//区间为:[1,2)
auto begin = it.first;
auto end = it.second;
while (begin != end)
{
cout << *begin << " ";
begin++;
}
cout << endl;
- 运行结果

强调:
- 在插入相同值时,并不能保证稳定性,即相同数据的前后顺序会不会发生改变——涉及AVL树。
- set系列的迭代器,在底层都是const迭代器,表明其值是不能被修改的,在底层上来讲,如果修改了,就破坏了二叉搜索树的结构。
二、map系列
1.map
①insert
1.插入pair的四种方式
map<string, string> dict;
//第一种方式:命名对象插入
pair<string, string> p("insert", "插入");
dict.insert(p);
//第二种方式:直接用匿名对象进行插入
dict.insert(pair<string, string>("sort", "排序"));
//第三种方式:make_pair交由函数(底层会被优化成内联)—— C++98。
//推荐使用这种,因为大多数都支持。
//C++98只支持单参数的构造函数
dict.insert(make_pair("object", "对象"));
//第四种方式:{} ——C++11采用了这种方式从而支持了多参数的构造函数。
dict.insert({ "English","英语" });
- 补充:make_pair函数——C++98

- 补充:pair的基本运算符重载

2.常用两种方式
//字典序
map<string, string> dict;
dict.insert(make_pair("object", "对象"));
dict.insert(make_pair("insert", "插入"));
dict.insert(make_pair("sort", "排序"));
dict.insert(make_pair("English", "英语"));
for (const auto& e : dict)
{
cout << e.first << ":" << e.second << endl;
}
//查找次数
string strs[] = { "苹果", "西瓜", "苹果", "樱桃", "苹果", "樱桃"\
, "苹果", "樱桃", "苹果" };
map<string, int> countMap;
for (const auto& e : strs)
{
auto it = countMap.find(e);
if (it != countMap.end())
{
(it->second)++;
}
else
{
countMap.insert(make_pair(e, 1));
}
}
for (const auto& e : countMap)
{
cout << e.first << ":" << e.second << endl;
}
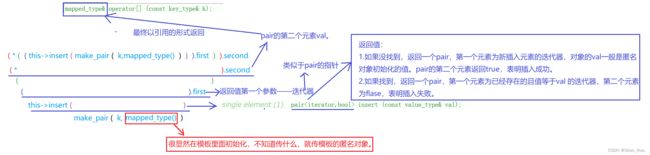
②[]
- 函数原理分析:
- 简单使用
string strs[] = { "苹果", "西瓜", "苹果", "樱桃", "苹果", "樱桃", \
"苹果", "樱桃", "苹果" };
map<string, int> countMap;
for (const auto& e : strs)
{
countMap[e]++;
}
for (const auto& e : countMap)
{
cout << e.first << ":" << e.second << endl;
}
-
时间复杂度:因为底层是二叉搜索树的结构,因此为logN(底层是优化了的,包括最坏情况也优化成了大概logN)。
-
补充:map对已有元素,是不会再进行插入和覆盖的,至少在VS下是这样。
2.multimap
- 说明:因为支持了重复元素的插入,因此不存在[]运算符重载。
①count
-
基本用法同multiset
-
简单应用:
multimap<string, string> dict;
dict.insert(make_pair("tell", "告诉"));
dict.insert(make_pair("tell", "分辨"));
dict.insert(make_pair("hot", "热的"));
dict.insert(make_pair("hot", "性感的"));
for (const auto& e : dict)
{
cout << e.first << ":" << e.second << endl;
}
size_t n = dict.count("tell");
//这里模拟的是一词多义,即tell有几种意思。
cout <<"tell有:" << n <<"种意思" << endl;
②equal_range
-
用法同multiset
-
简单运用:
multimap<string, string> dict;
dict.insert(make_pair("tell", "告诉"));
dict.insert(make_pair("tell", "分辨"));
dict.insert(make_pair("hot", "热的"));
dict.insert(make_pair("hot", "性感的"));
//pair::const_iterator, \
multimap::iterator> \
it = dict.equal_range("tell");
//tell的几个意思分别是
auto it = dict.equal_range("tell");
auto begin = it.first;
auto end = it.second;
while (begin != end)
{
cout << begin->first << ":" << begin->second << endl;
begin++;
}